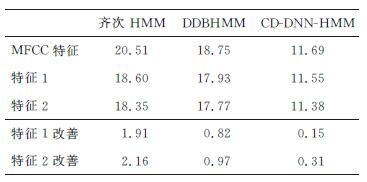
Abstract:The inter-frame independence assumption for speech recognition simplifies the computations. However, it also reduces the model accuracy and can easily give rise to recognition errors. Therefore, the objective of this paper is to search for a feature which can weaken the inter-frame dependence of the speech features and keep as much information of the original speech as possible. Two speech recognition feature extraction algorithms are given based on the k-means algorithm and the normalized intra-class variance. These algorithms provide adaptive clustering feature extraction. Speech recognition tests with these algorithms on a Gaussian mixture model-hidden Markov model (GMM-HMM), a duration distribution based HMM (DDBHMM), and a context dependent deep neural network HMM (CD-DNN-HMM) show that the adaptive feature based on the normalized intra-class variance reduces the relative recognition error rates by 10.53%, 5.17%, and 2.65% relative to the original features. Thus, this adaptive clustering feature extraction algorithm provides improved speech recognition.
Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Readings in Speech Recognition, 1990, 77(2):267-296.
[2]
Reynolds D A, Rose R C. Robust text-independent speaker identification using Gaussian mixture speaker models[J]. IEEE Transactions on Speech & Audio Processing, 1995, 3(1):72-83.
[3]
Sainath T N, Kingsbury B, Saon G, et al. Deep convolutional neural networks for large-scale speech tasks[J]. Neural Networks the Official Journal of the International Neural Network Society, 2015, 64:39-48.
[4]
Ansari Z, Seyyedsalehi S A. Toward growing modular deep neural networks for continuous speech recognition[J/OL]. Neural Computing & Applications, 2016:1-20. DOI:10.1007/s00521-016-2438-x.
[5]
Hinton G, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition:The shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6):82-97.
[6]
Yu D, Deng L, Seide F. The deep tensor neural network with applications to large vocabulary speech recognition[J]. IEEE Transactions on Audio Speech & Language Processing, 2013, 21(2):388-396.
[7]
Hinton G, Osindero S, Teh Y. A fast learning algorithm for deep belief nets[J]. Neural Computation, 1989, 18(7):1527-1554.
[8]
Yu D, Seltzer M L. Improved bottleneck features using pretrained deep neural networks[C]//INTERSPEECH 2011, Conference of the International Speech Communication Association. Florence, Italy, 2011:237-240.
[9]
Dahl G E, Yu D, Deng L, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Transactions on Audio Speech & Language Processing, 2012, 20(1):30-42.
[10]
Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Readings in Speech Recognition, 1990, 77(2):267-296.
[11]
肖熙. DDBHMM语音识别模型的训练和识别算法[D]. 北京:清华大学, 2003.XIAO Xi. The Training and Recognition Algorithm for DDBHMM Speech Recognition Model[D]. Beijing:Tsinghua University, 2003. (in Chinese)
[12]
李春, 王作英. 基于语音学分类的三音子识别单元的研究[C]//全国人机语音通讯学术会议. 深圳, 2001:257-262.LI Chun, WANG Zuoying. Triphone recognition unit based on phonetics category[C]//The 6th National Coference of Human-Computer Speech Communication. Shenzhen, 2001:257-262. (in Chinese)
 2017, Vol. 57
2017, Vol. 57