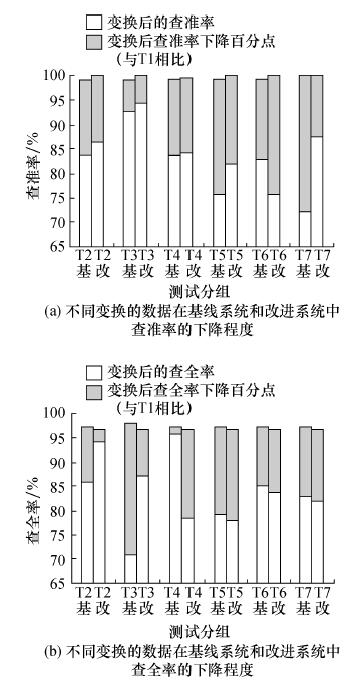
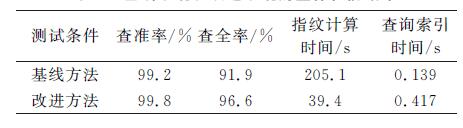
Abstract:Key audio detection, an important form of audio retrieval, uses a query audio sample to search in an audio database but such searches are not very efficient or robust. This paper optimizes the pre-processing, fingerprint extraction and retrieval of the audio retrieval. The pre-processing uses endpoint detection based on the sub-band energy ratio with a modified window function and measurements of the sub-band divisions. The fingerprint extraction uses seed fragments and spectral sub-band centroids. The retrieval part uses a threshold for the hit counts to improve the efficiency. This system improves the precision and reduces the recall rate with good noise suppression. The retrieval efficiency and performance are effectively improved.
孙甲松, 张菁芸, 杨毅. 基于子带频谱质心特征的高效音频指纹检索[J]. 清华大学学报(自然科学版), 2017, 57(4): 382-387.
SUN Jiasong, ZHANG Jingyun, YANG Yi. Effective audio fingerprint retrieval based on the spectral sub-band centroid feature. Journal of Tsinghua University(Science and Technology), 2017, 57(4): 382-387.
欧智坚, 罗骏, 谢达东, 等. 多功能语音/音频信息检索系统的研究与实现[C]//全国网络与信息安全技术研讨会. 北京: 中国通信学会, 2004: 106-112.OU Zhijian, LUO Jun, XIE Dadong, et al. The research and implementation of multi-function voice/audio information retrieval system[C]//National Network and Information Security Technology Conference. Beijing: CIC, 2004: 106-112.
[4]
Smith G, Murase H, Kashino K. Quick audio retrieval using active search[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Seattle, USA: IEEE, 1998: 3777-3780.
[5]
Roy D, Malamud C. Speaker identification based text to audio alignment of an audio retrieval system[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Munich, Germany: IEEE, 1997: 1099-1102.
[6]
QIN Jing, LIU Xinyue, LIN Hongfei. Audio retrieval based on manifold ranking[C]//Sixth International Symposium on Parallel Architectures, Algorithms and Programming. Beijing, China: IEEE, 2014: 187-190.
[7]
Foote J. An overview of audio information retrieval[J]. Multimedia Systems, 1999, 7(1): 2-11.
[8]
Wold E, Blum T, Keislar D, et al. Content-based classification search and retrieval of audio[J]. IEEE Multimedia Magazine, 1996, 3(3): 27-36.
[9]
LIU Mingchun, WAN Chunru. A study on content based classification and retrieval of audio database[C]//IEEE Database Engineering and Applications Symposium. Grenoble, France: IEEE, 2001: 339-345.
[10]
Piamsa-Nga P, Alexandridis N A, Srakaew S, et al. In-clip search algorithm for content-based audio retrieval[C]//Proceedings of the Third International Conference on Computational Intelligence and Multimedia Applications. New Delhi, India: IEEE, 1999: 263-267.
[11]
Haitsma J, Kalker T. A highly robust audio fingerprinting system with an efficient search strategy[J]. Journal of New Music Research, 2003, 32(2): 211-221.
[12]
WANG Avery, LI Chun. An industrial strength audio search algorithm[C]//Ismir 2003, International Conference on Music Information Retrieval, Baltimore. Washington, DC, USA: FEUP Edições, 2003: 7-13.
[13]
XU Haotian, OU Zhijian. Scalable discovery of audio fingerprint motifs in broadcast streams with determinantal point process based motif clustering[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2016, 24(5): 978-989.
[14]
Chaudhary P, Hamid H, Kamel N, et al. A novel approach for segment level audio retrieval using singular value decomposition[C]//5th International Conference on Intelligent and Advanced Systems. Kuala Lumpur, Malaysia: IEEE, 2014: 1-5.
[15]
Dermatas E S, Fakotakis N D, Kokkinakis G K. Fast endpoint detection algorithm for isolated word recognition in office environment[C]//IEEE International Conference on Acoustic, Speech and Signal Processing. Salt Lake: IEEE, 1991: 733-736.
[16]
Haitsma J, Kalker T. Speed-change resistant audio fingerprinting using auto-correlation[C]//International Conference on Acoustics, Speech and Signal Processing. Hong Kong, China: IEEE, 2003, 4: 728-731.
[17]
Shen F, Shen C, Shi Q, et al. Inductive hashing on manifolds[C]//IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013: 1562-1569.
[18]
ZHANG Xueyuan, HE Qianhua, LI Yanxiong, et al. An inverted index based audio retrieval method[J]. Journal of Electronics & Information Technology, 2012, 34(11): 2561-2567.
[19]
Paliwalm K K. Spectral subband centroid features for speech recognition[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Seattle, USA: IEEE, 1998: 617-620.
[20]
Seo J S, Jin M, Lee S, et al. Audio fingerprinting based on normalized spectral subband centroids[C]//IEEE International Conference on Acoustics, Speech and Signal Processing. Philadelphia, USA: IEEE, 2005, 3: 213-216.
 2017, Vol. 57
2017, Vol. 57