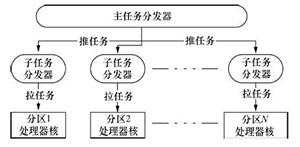
Task scheduling on a many-core processor for high-volume throughput applications
XU Yuanchao1,2, YANG Lu1
1. College of Information Engineering, Capital Normal University, Beijing 100048, China;
2. State Key Laboratory of Computer Architecture, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China
Abstract:Big data applications with high-volume throughputs have become the most common applications in datacenters. The efficiencies of these applications running on traditional processors are very low for various reasons, one of which is the low-efficiency task scheduling. This paper presents a task scheduling framework that identifies program behavior and the running environment and then partitions the cores with hierarchical task scheduling though hardware and software co-design to reduce the negative effect of shared resource contention and improving the instruction cache hit rate using thread similarity. Tests show this algorithm improves performance by 20% on average over the legacy work-stealing scheduling algorithm.
徐远超, 杨璐. 面向高通量应用的众核处理器任务调度[J]. 清华大学学报(自然科学版), 2017, 57(3): 244-249.
XU Yuanchao, YANG Lu. Task scheduling on a many-core processor for high-volume throughput applications. Journal of Tsinghua University(Science and Technology), 2017, 57(3): 244-249.
王元卓, 靳小龙, 程学旗. 网络大数据:现状与展望[J]. 计算机学报, 2013, 36(6):1-15.WANG Yuanzhuo, JIN Xiaolong, CHENG Xueqi. Network big data:Present and future[J]. Chinese Journal of Computers, 2013, 36(6):1-15. (in Chinese)
[2]
詹剑锋, 王磊, 孙凝晖. 高通量计算机的性能评价[J]. 中国计算机学会通讯, 2011, 7(7):40-43.ZHAN Jianfeng, WANG Lei, SUN Ninghui. Performance evaluation of high-volume throughput computer[J]. Communication of CCF, 2011, 7(7):40-43. (in Chinese)
[3]
Allan A, Edenfeld D, Joyner W H, et al. 2001 technology roadmap for semiconductors[J]. Computer, 2002, 35(1):42-53.
[4]
Broquedis F, Diakhaté F, Thibault S, et al. Scheduling dynamic OpenMP applications over multicore architectures[C]//Proc of the International Workshop on OpenMP. Berlin, Germany:Springer, 2008:170-180.
[5]
Frigo M, Leiserson C E, Randall K H. The implementation of the Cilk-5 multithreaded language[C]//ACM Sigplan Notices. Montreal, Quebec, Canada:ACM, 1998:212-223.
[6]
Blumofe R D, Leiserson C E. Scheduling multithreaded computations by work stealing[C]//Proc 35th Annual Symposium on Foundations of Computer Science. New York, NY, USA:IEEE, 1994:356-368.
[7]
Ebrahimi E, Lee C J, Mutlu O, et al. Fairness via source throttling:A configurable and high-performance fairness substrate for multi-core memory systems[C]//ACM Sigplan Notices. Pittsburgh, PA, USA:ACM, 2010, 45(3):335-346.
[8]
Diamos G F, Yalamanchili S. Harmony:An ution model and runtime for heterogeneous many core systems[C]//Proc 17th International Symposium on High Performance Distributed Computing. Boston, MA, USA:ACM, 2008:197-200.
[9]
Augonnet C, Thibault S, Namyst R, et al. StarPU:A unified platform for task scheduling on heterogeneous multicore architectures[C]//Proc of the European Conference on Parallel Processing. Berlin, Germany:Springer, 2009:863-874.
[10]
Nightingale E B, Hodson O, McIlroy R, et al. Helios:Heterogeneous multiprocessing with satellite kernels[C]//Proc 22nd ACM SIGOPS Symposium on Operating Systems Principles. Big Sky, MT, USA:ACM, 2009:221-234.
[11]
Baumann A, Barham P, Dagand P E, et al. The multikernel:A new OS architecture for scalable multicore systems[C]//Proc 22nd ACM SIGOPS Symposium on Operating Systems Principles. Big Sky, MT, USA:ACM, 2009:29-44.
[12]
Wentzlaff D, Agarwal A. Factored operating systems (fos):The case for a scalable operating system for multicores[J]. ACM SIGOPS Operating Systems Review, 2009, 43(2):76-85.
[13]
Boyd-Wickizer S, Chen H, Chen R, et al. Corey:An operating system for many cores[C]//Proc 8th USENIX Symposium on Operating Systems Design and Implementation. San Diego, CA, USA:USENIX, 2008, 8:43-57.
[14]
Rhoden B, Klues K, Zhu D, et al. Improving per-node efficiency in the datacenter with new OS abstractions[C]//Proc 2nd ACM Symposium on Cloud Computing. Cascais, Portugal:ACM, 2011:25.
[15]
Kumar V, Fedorova A. Towards better performance per Watt in virtual environments on asymmetric single-ISA multi-core systems[J]. ACM SIGOPS Operating Systems Review, 2009, 43(3):105-109.
[16]
曹仰杰, 钱德沛, 伍卫国, 等. 众核处理器系统核资源动态分组的自适应调度算法[J]. 软件学报, 2012, 23(2):240-252. CAO Yangjie, QIAN Depei, WU Weiguo, et al. Adaptive scheduling algorithm based on dynamic core-resource partitions for many-core processor systems[J]. Journal of Software, 2012, 23(2):240-252. (in Chinese)
[17]
Mogul J C, Mudigonda J, Binkert N, et al. Using asymmetric single-ISA CMPs to save energy on operating systems[J]. IEEE Micro, 2008, 28(3):26-41.
[18]
Ye X, Fan D, Sun N, et al. SimICT:A fast and flexible framework for performance and power evaluation of large-scale architecture[C]//Proc of the 2013 International Symposium on Low Power Electronics and Design. Beijing, China:IEEE Press, 2013:273-278.
[19]
Ferdman M, Adileh A, Kocberber O, et al. Clearing the clouds:A study of emerging scale-out workloads on modern hardware[C]//ACM SIGPLAN Notices. London, UK:ACM, 2012:37-48."
 2017, Vol. 57
2017, Vol. 57