Hybrid computational strategy for deep learning based on AVX2
JIANG Wenbin, WANG Hongbin, LIU Pai, CHEN Yuhao
Services Computing Technology and System Laboratory, National Engineering Research Center for Big Data Technology and System, School of Computer Science and Technology, Huazhong University of Science and Technology, Wuhan 430074, China
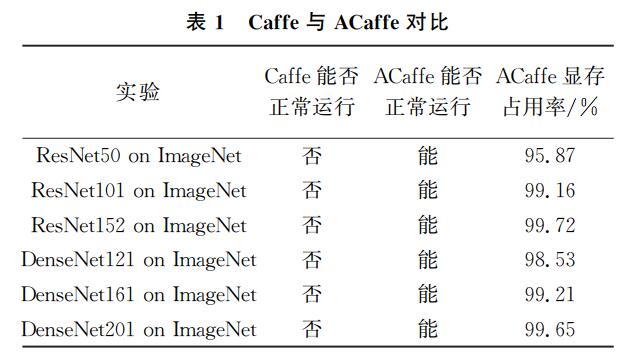
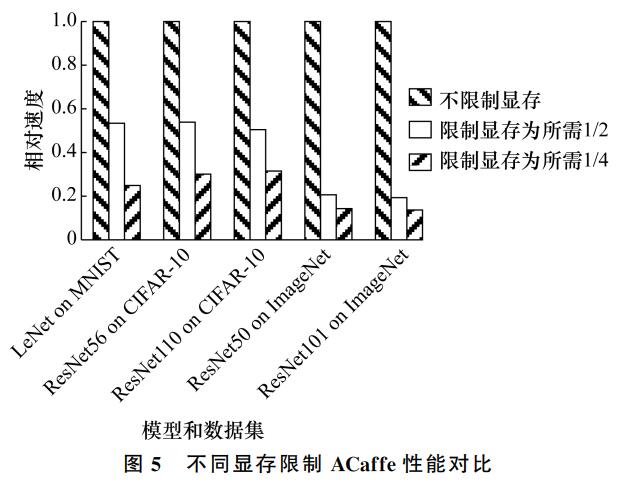
Abstract:Small GPU memories usually restrict the scale of deep learning network models that can be handled in the GPU processors. To address this problem, a hybrid strategy for deep learning was developed which also uses the potential of the CPU by means of the new Intel SIMD instruction set AVX2. The neural network layers which need much memory for the intermediate data are migrated to the CPU to reduce the GPU memory usage. AVX2 is then used to improve the CPU efficiency. The key points include coordinating the network partitioning scheme and the code vectorization based on AVX2. The hybrid strategy is implemented on Caffe. Tests on some typical datasets, such as CIFAR-10 and ImageNet, show that the hybrid computation strategy enables training of larger neural network models on the GPU with acceptable performance.
蒋文斌, 王宏斌, 刘湃, 陈雨浩. 基于AVX2指令集的深度学习混合运算策略[J]. 清华大学学报(自然科学版), 2020, 60(5): 408-414.
JIANG Wenbin, WANG Hongbin, LIU Pai, CHEN Yuhao. Hybrid computational strategy for deep learning based on AVX2. Journal of Tsinghua University(Science and Technology), 2020, 60(5): 408-414.
[1] LECUN Y, BENGIO Y, HINTON G E, et al. Deep learning[J]. Nature, 2015, 521(7553):436-444. [2] KRIZHEVSKY A, SUTSKEVER I, HINTON G E, et al. ImageNet classification with deep convolutional neural networks[C]//International Conference on Neural Information Processing Systems. New York, USA:NIPS, 2012:1097-1105. [3] GRAVES A, SCHMIDHUBER J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J]. Neural Networks, 2005, 18(5-6):602-610. [4] DAVIDSON J, LIEBALD B, LIU J N, et al. The YouTube video recommendation system[C]//Proceedings of the Fourth ACM Conference on Recommender Systems. Barcelona, Spain:ACM, 2010:293-296. [5] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537. [6] LOMONT C. Introduction to Intel® advanced vector extensions[R/OL]. (2011-06-21). https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions/. [7] JIA Y Q, SHELHAMER E, DONAHUE J, et al. Caffe:Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM international Conference on Multimedia. Orlando, USA:ACM, 2014:675-678. [8] RHU M, GIMELSHEIN N, CLEMONS J, et al. vDNN:Virtualized deep neural networks for scalable, memory-efficient neural network design[C]//Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture. Taipei, China:IEEE, 2016:18. [9] WANG L N, YE J M, ZHAO Y Y, et al. Superneurons:Dynamic GPU memory management for training deep neural networks[C]//Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Vienna, Austria:ACM, 2018:41-53. [10] JIN H, LIU B, JIANG W B, et al. Layer-centric memory reuse and data migration for extreme-scale deep learning on many-core architectures[J]. ACM Transactions on Architecture and Code Optimization, 2018, 15(3):37. [11] WANG E D, ZHANG Q, SHEN B, et al. Intel math kernel library[M]//WANG E D, ZHANG Q, SHEN B, et al. High-Performance Computing on the Intel® Xeon PhiTM. Cham:Springer, 2014:167-188. [12] RODRIGUEZ A, SEGAL E, MEIRI E, et al. Lower numerical precision deep learning inference and training[R/OL]. (2018-01-19). https://software.intel.com/en-us/articles/accelerate-lower-numerical-precision-inference-with-intel-deep-learning-boost. [13] HECHT-NIELSEN R. Theory of the backpropagation neural network[M]//WECHSLER H. Neural Networks for Perception. New York:Academic, 1992. [14] CHANDRA R, DAGUM L, KOHR D, et al. Parallel programming in OpenMP[M]. San Francisco:Morgan Kaufmann, 2001.
 2020, Vol. 60
2020, Vol. 60