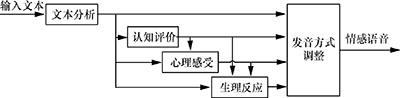
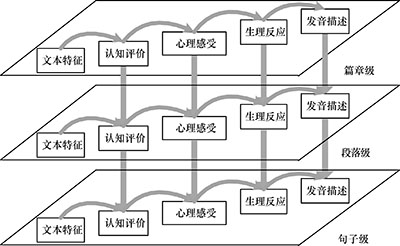
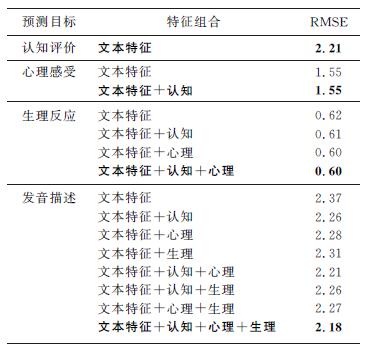
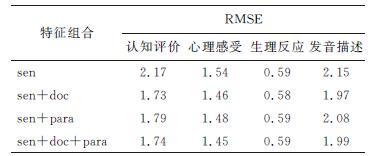
Abstract:A multi-perspective emotion model is presented to provide more details about the emotions in expressive speech synthesis and to facilitate automatic predictions. The method describes the emotion development in terms of the cognitive appraisal, psychological feeling, physical response and utterance manner. The descriptive model is used to develop a text-based emotion prediction model using a deep neural network (the deep stacking network), which supports distributed representation and has a stacking structure. Tests validate the benefits of using this prediction method for the interactions among different emotional aspects and the contextual impacts, as well as the effectiveness of the deep stacking network and the multi-perspective emotion model.
Govind D, Prasanna S R M. Expressive speech synthesis:A review[J]. International Journal of Speech Technology, 2013, 16(2):237-260.
[2]
徐俊, 蔡莲红. 面向情感转换的层次化韵律分析与建模[J]. 清华大学学报:自然科学版, 2009, 49(S1):1274-1277.XU Jun, CAI Lianhong. Hierarchical prosody analysis and modeling for emotional conversions[J]. J Tsinghua Univ:Sci & Tech, 2009, 49(S1):1274-1277. (in Chinese)
[3]
TAO Jianhua, KANG Yongguo, LI Aijun. Prosody conversion from neutral speech to emotional speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4):1145-1154.
[4]
韩纪庆, 邵艳秋. 基于语音信号的情感处理研究进展[J]. 电声技术, 2006(5):58-62.HAN Jiqing, SHAO Yanqiu. Research progress of emotion processing based on speech signal[J]. Audio Engineering, 2006(5):58-62. (in Chinese)
[5]
Ekman P, Friesen W V, O'Sullivan M, et al. Universals and cultural differences in the judgments of facial s of emotion[J]. Journal of Personality and Social Psychology, 1987, 53(4):712-717.
[6]
Cowie R, Douglas-Cowie E, Savvidou S, et al. FEELTRACE:An instrument for recording perceived emotion in real time[C]//ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion. Newcastle, UK, 2000:19-24.
[7]
Mehrabian A. Pleasure-arousal-dominance:A general framework for describing and measuring individual differences in temperament[J]. Current Psychology, 1996, 14(4):261-292.
[8]
Moors A, Ellsworth P C, Scherer K R, et al. Appraisal theories of emotion:State of the art and future development[J]. Emotion Review, 2013, 5(2):119-124.
[9]
高莹莹, 朱维彬. 言语情感描述体系的试验性研究[J]. 中国语音学报, 2013, 4:71-81.GAO Yingying, ZHU Weibin. The research for the description system of speech emotion[J]. Chinese Journal of Phonetics, 2013, 4:71-81. (in Chinese)
[10]
DENG Li, YU Dong, Platt J. Scalable stacking and learning for building deep architectures[C]//IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Kyoto, Japan, 2012:2133-2136.
[11]
Riedl M, Biemann C. Text segmentation with topic models[J]. Journal for Language Technology and Computational Linguistics, 2012, 27(1):47-69.
[12]
Blei D M, Ng A Y, Jordan M I. Latent Dirichlet allocation[J]. The Journal of Machine Learning Research, 2003, 3:993-1022.
[13]
Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504-507.
[14]
Hinton G. A practical guide to training restricted Boltzmann machines[J]. Momentum, 2010, 9(1):599-619.
[15]
YU Dong, DENG Li. Accelerated parallelizable neural network learning algorithm for speech recognition[C]//12th Annual Conference of the International Speech Communication Association (INTERSPEECH). Florence, Italy:ISCA Press, 2011:2281-2284.
 2017, Vol. 57
2017, Vol. 57