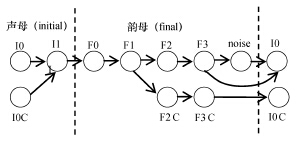
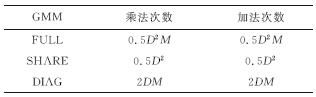
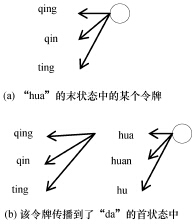
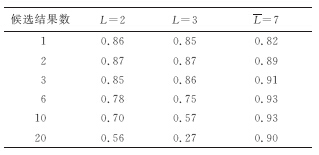
Abstract:An improved lattice-based speech keyword spotting system was developed from the Gaussian mixture model and an improved N-best speech recognition algorithm. First, tests were used to evaluate different simplified structures of Gaussian mixture models. Then, an N-best token passing algorithm was developed from the classic token passing algorithm using some unique pronunciation rules for the Chinese language. These two modifications improve the performance of both the 1-best and N-best speech recognition candidates. Finally, a key word spotting system was developed based on an N-best lattice to show the effectiveness of these improvements.
Reynolds D A, Rose R C. Robust text-independent speaker identification using Gaussian mixture speaker models [J]. IEEE Trans Speech Audio Process, 1995, 3(1): 72-83.
[2]
Hinton G, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups [J]. IEEE Signal Process Mag, 2012, 29(6): 82-97.
[3]
Yu D, Deng L, Seide F, The deep tensor neural network with applications to large vocabulary speech recognition [J]. IEEE Trans Audio Speech Lang Process, 2013, 21(2): 388-396.
[4]
Pang Z, Tu S, Su D, et al. Discriminative training of GMM-HMM acoustic model by RPCL learning [J]. Front Electr Electron Eng China, 2011, 6(2): 283-290.
[5]
Povey D, Burget L, Agarwal M, et al. The subspace Gaussian mixture model: A structured model for speech recognition [J]. Comput Speech Lang, 2011, 25(2): 404-439.
[6]
Du J, Hu Y, Jiang H. Boosted mixture learning of gaussian mixture hidden markov models based on maximum likelihood for speech recognition [J]. IEEE Trans Audio Speech Lang Process, 2011, 19(7): 2091-2100.
[7]
Veiga A, Lopes C, Sá L, et al. Acoustic similarity scores for keyword spotting [J]. Computational Processing of the Portuguese Language, 2014, 8775: 48-58.
[8]
Thambiratnam K, Sridharan S. Dynamic match phone-lattice searches for very fast and accurate unrestricted vocabulary keyword spotting [C]//Proc ICASSP. Philadelphia, PA, USA: IEEE Press, 2005: 465-468.
[9]
罗骏, 欧智坚, 王作英. 基于拼音图的两阶段关键词检索系统 [J]. 清华大学学报, 2005, 45(10): 1356-1359.LUO Jun, OU Zhijian WANG Zuoying. Two-stage keyword spotting system based on syllable graphs [J]. Journal of Tsinghua University (Science and Technology), 2005, 45(10): 1356-1359. (in Chinese)
[10]
Young S J, Russell N H, Thornton J H S. Token Passing: A Simple Conceptual Model for Connected Speech Recognition Systems, CUED/F-INFENG/TR, 38 [R]. Cambridge, UK: University of Cambridge, 1989.
[11]
李春, 王作英. 基于语音学分类的三音子识别单元的研究 [C]//第六届全国人机语音通讯学术会议论文集. 深圳: 中国中文信息学会, 2001: 257-262.LI Chun, WANG Zuoying. Triphone recognition unit based on phonetics category [C]//The 6th National Conference of Human-Computer Speech Communication. Shenzhen, China: CIPSC, 2001, 257-262. (in Chinese)
[12]
游展. DDBHMM语音识别段长模型的研究和改进 [D]. 北京: 清华大学, 2008.YOU Zhan. The Research and Improvement on DDBHMM Speech Recognition Model [D]. Beijing: Tsinghua University, 2008. (in Chinese)
[13]
肖熙. DDBHMM语音识别模型的训练和识别算法 [D]. 北京: 清华大学, 2003.XIAO Xi. The Training and Recognition Algorithm for DDBHMM Speech Recognition Model [D]. Beijing: Tsinghua University, 2003. (in Chinese).
 2015, Vol. 55
2015, Vol. 55