Overlapping speech detection using high-level information features
MA Yong1,2, BAO Changchun1
1. School of Electronic Information and Control Engineering, Beijing University of Technology, Beijing 100124, China;
2. School of Physics and Electronic Engineering, Jiangsu Normal University, Xuzhou 221009, China
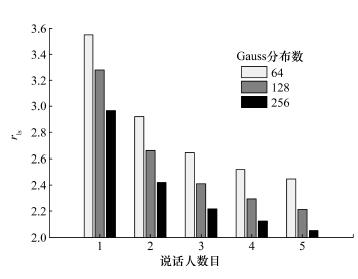
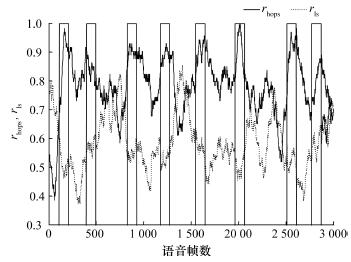
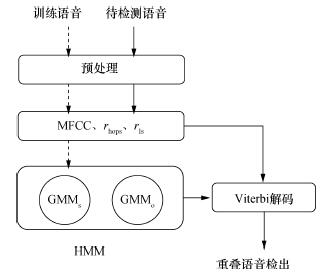
Abstract:Overlapping speech is one of the main factors influencing the performance of speaker segmentation. This paper presents an overlapping speech detection method using a high-level information feature to improve the speaker segmentation results. A linguistic high-level information feature of the speech is extracted using the universal background model (UBM). Then, a hidden Markov model (HMM) is trained using the Mel frequency cepstral coefficients (MFCC) and the high-level information to detect overlapping speech. The result is then used for the speaker segmentation of the pre-processed speech. Tests on a dataset generated from the TIMIT database show that the error ratio for overlapping speech detection is significantly lower than the reference method using just the MFCC feature. The speaker segmentation is also significantly improved.
马勇, 鲍长春. 基于高层信息特征的重叠语音检测[J]. 清华大学学报(自然科学版), 2017, 57(1): 79-83.
MA Yong, BAO Changchun. Overlapping speech detection using high-level information features. Journal of Tsinghua University(Science and Technology), 2017, 57(1): 79-83.
Shriberg E, Stolcker A, Baron D. Observations on overlap:Finding and implications for automatic processing of multi-party conversation[C]//Proc 7th European Conference on Speech Communication and Technology. Aalborg, Denmark:ISCA, 2001:1359-1362.
[2]
Sinclair M, King S. Where are the challenges in speaker diarization[C]//Proc International Conference on Acoustics, Speech, Signal and Signal Processing. Vancouver, Canada:IEEE, 2013:7741-7745.
[3]
马勇, 鲍长春. 说话人分割聚类研究进展[J]. 信号处理, 2013, 29(9):1190-1199.MA Yong, BAO Changchun. Advance in speaker segmentation and clustering[J]. Journal of Signal Processing, 2013, 29(9):1190-1199. (in Chinese).
[4]
Kotti M, Moschou V, Kotropoulos C. Speaker segmentation and clustering[J]. Signal Processing, 2008. 88(5):1091-1124.
[5]
Otterson S, Ostendorf M. Efficient use of overlap information in speaker diarization[C]//Proc Conference Automatic Speech Recognition & Understanding, Kyoto, Japan:IEEE, 2007:683-686.
[6]
Roakye K, Hornero B, Vinyals O, et al. Overlapped speech detection for improved diarization in multi-party meetings[C]//Proc International Conference on Acoustics, Speech, Signal and Signal Processing. Las Vegas, NV, USA:IEEE, 2008:4353-4356.
[7]
Roakye K, Vinyals O, Friedland G. Improved overlapped speech handling for speaker diarization[C]//Proc International Speech Communication Association. Florence, Italy:ISCA, 2011:941-944.
[8]
Zelenak M, Segura C, Luque J, et al, Simultaneous speech detection with spatial features for speaker diarization[J]. IEEE Transaction on Audio, Speech and Language Processing, 2012, 20(2):436-446.
[9]
Geiger J T, Eyben F, Evans N, et al. Using linguistic information to detect overlapping speech[C]//Proc International Speech Communication Association. Lyon, France:ISCA, 2013:941-944.
[10]
Yella S H, Bourlard H. Overlapping speech detection using long-term conversational features for speaker diarization in meeting room conversations[J]. IEEE Transaction on Audio, Speech and Language Processing, 2014, 22(12):1688-1700.
[11]
Reynolds D, Quatieri T, Dunn R. Speaker verification using adapted Gaussian mixture models[J]. Digital Signal Processing, 2000, 10(1):19-41.
[12]
Delacourt P, Wellekens C J. DISTBIC:A speaker-based segmentation for audio data indexing[J]. Speech Communication, 2000, 32(1):111-126.
 2017, Vol. 57
2017, Vol. 57