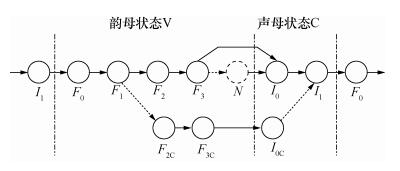
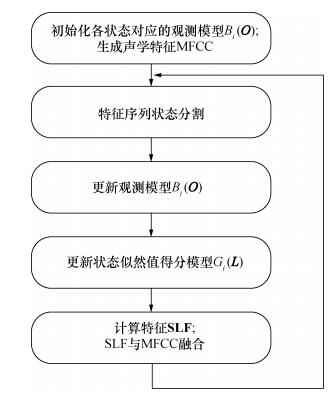
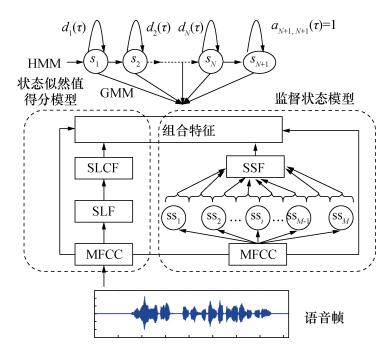
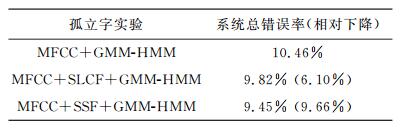
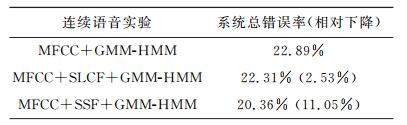
Abstract:A Gaussian mixture model-hidden Markov model (GMM-HMM) for speech recognition uses the most likely state sequence (MLSS) criterion to get the best state series of observations. Since the MLSS search algorithm only considers the maximum likelihood state of speech frame, the effects of other suboptimal states are neglected and some important information is lost, which reduces the system recognition rate. Acoustic state likelihood modelling and supervised state modelling are used here to better utilize the acoustic state likelihood information. A state likelihood cluster feature and a supervised state feature are used to calculate the state likelihood of the acoustic feature Mel frequency cepstrum coefficient (MFCC). Tests show that these three features improve the speech recognition accuracy. The state likelihood cluster and supervised state feature reduce the relative error rate by 6.10% and 9.66% for isolated word recognition compared to GMM-HMM using only MFCC and by 2.53% and 11.05% for continuous speech recognition.
肖熙, 徐晨. 基于声学状态似然值得分模型及监督状态模型的语音识别特征融合算法[J]. 清华大学学报(自然科学版), 2019, 59(6): 476-481.
XIAO Xi, XU Chen. Speech feature fusion algorithm based on acoustic state likelihood and supervised state modelling. Journal of Tsinghua University(Science and Technology), 2019, 59(6): 476-481.
[1] BAKER J M, LI D, GLASS J, et al. Developments and directions in speech recognition and understanding, Part 1[DSP Education] [J]. IEEE Signal Processing Magazine, 2009, 26(3):75-80. [2] RABINER L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Readings in Speech Recognition, 1990, 77(2):267-296. [3] FURUI S. Digital speech processing, synthesis, and recognition[M]. New York:Marcel Dekker, 2000. [4] YU D, LI D, SEIDE F. The deep tensor neural network with applications to large vocabulary speech recognition[J]. IEEE Transactions on Audio Speech and Language Processing, 2013, 21(2):388-396. [5] 欧智坚, 王作英. 从线性预测HMM到一种新的语音识别的混合模型[J]. 电子学报, 2002, 30(9):1313-1316.OU Z J, WANG Z Y. A hybrid model from linear prediction HMM to a new speech recognition[J]. Chinese Journal of Electronics, 2002, 30(9):1313-1316. (in Chinese) [6] PANG Z H, TU S K, SU D, et al. Discriminative training of GMM-HMM acoustic model by RPCL learning[J]. Frontiers of Electrical and Electronic Engineering, 2011, 6(2):283-290. [7] REYNOLDS D A, ROSE R C. Robust text-independent speaker identification using Gaussian mixture speaker models[J]. IEEE Transactions on Speech & Audio Processing, 1995, 3(1):72-83. [8] HERMANSKY H, ELLIS D, SHARMA S. Tandem connectionist feature extraction for conventional HMM systems[C]//2000 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.00CH37100). Istanbul, Turkey:IEEE, 2000, 1635-1638. [9] HAEBUMBACH R, NEY H. Linear discriminant analysis for improved large vocabulary continuous speech recognition[C]//IEEE International Conference on Acoustics. San Francisco, USA:IEEE, 1992, 13-16. [10] 李春, 王作英. 基于语音学分类的三音子识别单元的研究[C]//第六届全国人机语音通讯学术会议论文集.深圳:中国中文信息学会, 2001, 257-262.LI C, WANG Z Y. Triphone recognition unit based on phonetics category[C]//The 6th National Conference of Human Computer Speech Communication. Shenzhen, China:CIPSC, 2001, 257-262. (in Chinese) [11] 游展. DDBHMM语音识别段长模型的研究和改进[D]. 北京:清华大学, 2008.YOU Z. The research and improvement on DDBHMM speech recognition model[D]. Beijing:Tsinghua University, 2008. (in Chinese)
 2019, Vol. 59
2019, Vol. 59