| COMPUTER SCIENCE AND TECHNOLOGY |
|
 |
|

|
|
|
Mispronunciation tendency detection using deep neural networks |
| ZHANG Jinsong1,2, GAO Yingming1, XIE Yanlu1 |
1. College of Information Science, Beijing Language and Culture University, Beijing 100083, China;
2. Center for Studies of Chinese as a Second Language, Beijing Language and Culture University, Beijing 100083, China |
|
|
|
|
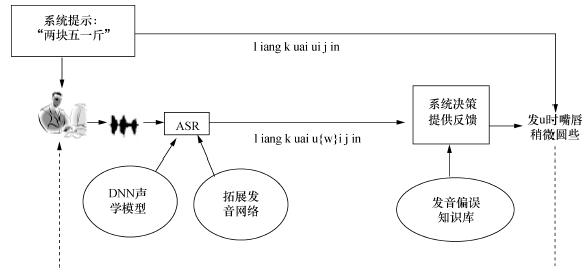
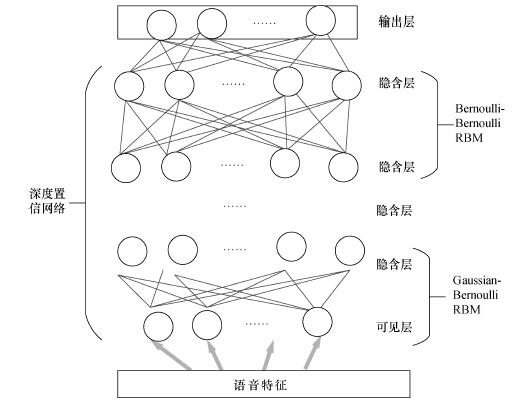
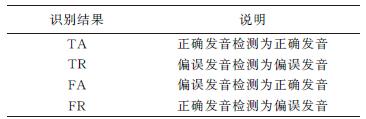
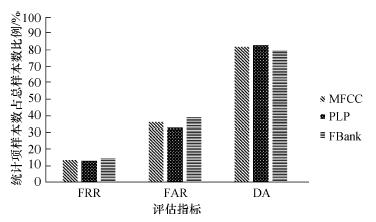
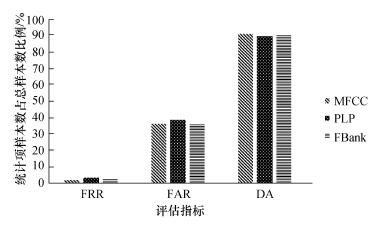
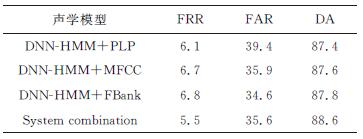
Abstract A previous computer aided pronunciation training (CAPT) system with instructive feedback used mispronunciation tendency labeling in a GMM-HMM based detection system. This system is improved here using a DNN-HMM to model the mispronunciation with comparisons of the effects of three kinds of acoustic features, the mel-frequency cepstral coefficient (MFCC), the perceptual linear predictive analysis (PLP) and the Mel filter bank (FBank). The lattice rescore method is also used with these three features. The results show that the DNN-HMM gives a better detection rate than the conventional approach based on the GMM-HMM. Different features behave differently in capturing the specific mispronunciation tendencies, so the integration of these three features based on the lattice rescore gives the best results with an FRR of 5.5%, FAR of 35.6%, and DA of 88.6%.
|
| Keywords
computer aided pronunciation training
mispronunciation detection
deep neural network
|
|
|
|
Issue Date: 15 November 2016
|
|
|
| [1] |
Witt S M. Automatic error detection in pronunciation training:Where we are and where we need to go[C]//Proceedings of the International Symposium on Automatic Detection of Errors in Pronunciation Training (IS ADEPT). Stockholm, Sweden, 2012:1-8.
|
| [2] |
Zheng J, Huang C, Chu M, et al. Generalized segment posterior probability for automatic Mandarin pronunciation evaluation[C]//The International Conference on Acoustics, Speech and Signal Processing. Hawii, USA:IEEE Press, 2007:201-204.
|
| [3] |
Hu W, Qian Y, Soong F K. A new DNN-based high quality pronunciation evaluation for computer-aided language learning (CALL)[C]//Proceedings of Conference of International Speech Communication Association. Lyon, France:International Speech Communication Association Press, 2013:1886-1890.
|
| [4] |
Neri A, Cucchiarini C, Strik H. ASR-based corrective feedback on pronunciation:Does it really work?[C]//Proceedings of Conference of International Speech Communication Association. Pittsburgh PA, USA:International Speech Communication Association Press, 2006:1982-1985.
|
| [5] |
Harrison A M, Lo W K, Qian X, et al. Implementation of an extended recognition network for mispronunciation detection and diagnosis in computer-assisted pronunciation training[C]//Proceedings of the 2nd ISCA Workshop on Speech and Language Technology in Education. Warrickshire. Brighton, United Kingdom:International Speech Communication Association Press, 2009:45-48.
|
| [6] |
Cao W, Wang D, Zhang J, et al. Developing a Chinese L2 speech database of Japanese learners with narrow-phonetic labels for computer assisted pronunciation training[C]//Proceedings of Conference of International Speech Communication Association. Chiba, Japan:International Speech Communication Association Press, 2010:1922-1925.
|
| [7] |
Duan R, Zhang J, Cao W, et al. A Preliminary study on ASR-based detection of Chinese mispronunciation by Japanese learners[C]//Proceedings of Conference of International Speech Communication Association. Singapore:International Speech Communication Association Press, 2014:1478-1481.
|
| [8] |
Li K, Meng H. Mispronunciation detection and diagnosis in l2 english speech using multi-distribution Deep Neural Networks[C]//Proceedings of the International Symposium on Chinese Spoken Language Processing (ISCSLP). Singapore:IEEE Press, 2014:255-259.
|
| [9] |
Hu W, Qian Y, Soong F K. A DNN-based acoustic modeling of tonal language and its application to Mandarin pronunciation training[C]//Acoustics, Speech and Signal Processing (ICASSP). Florence, Italy:IEEE Press, 2014:3206-3210.
|
| [10] |
Qian X, Meng H M, Soong F K. The use of DBN-HMMs for mispronunciation detection and diagnosis in L2 English to support computer-aided pronunciation training[C]//Proceedings of Conference of International Speech Communication Association. Portland, USA:International Speech Communication Association Press, 2012:775-778.
|
| [11] |
Hu W, Qian Y, Soong F K. A new neural network based logistic regression classifier for improving mispronunciation detection of L2 language learners[C]//Proceedings of the International Symposium on Chinese Spoken Language Processing (ISCSLP). Singapore:IEEE Press, 2014:245-249.
|
| [12] |
Golik P, Tüske Z, Schlüter R, et al. Development of the RWTH transcription system for Slovenian[C]//Proceedings of Conference of International Speech Communication Association. Lyon, France:International Speech Communication Association Press, 2013:3107-3111.
|
| [13] |
Zolnay A, Schlüter R, Ney H. Acoustic feature combination for robust speech recognition[C]//The International Conference on Acoustics, Speech and Signal Processing. Philadelpnia, PENN, USA:IEEE Press, 2005:457-460.
|
| [14] |
Siniscalchi S M, Li J, Lee C H. A study on lattice rescoring with knowledge scores for automatic speech recognition[C]//Proceedings of Conference of International Speech Communication Association. Pittsburgh PA, USA:International Speech Communication Association Press, 2006:517-520.
|
| [15] |
Yoon S Y, Hasegawa-Johnson M, Sproat R. Landmark-based automated pronunciation error detection[C]//The International Conference on Acoustics, Speech and Signal Processing. Dallas, TX, USA:IEEE Press, 2010:614-617.
|
| [16] |
Hinton G, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7):1527-1554.
|
| [17] |
Luo D, Yang X, Wang L. Improvement of segmental mispronunciation detection with prior knowledge extracted from large L2 speech corpus[C]//Proceedings of Conference of International Speech Communication Association. Florence, Italy:International Speech Communication Association Press, 2011:1593-1596.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|
 2016,
Vol. 56
2016,
Vol. 56