| COMPUTER SCIENCE AND TECHNOLOGY |
|
 |
|

|
|
|
DNN-LSTM based VAD algorithm |
| ZHANG Xueying, NIU Puhua, GAO Fan |
| College of Information Engineering, Taiyuan University of Technology, Taiyuan 030024, China |
|
|
|
|
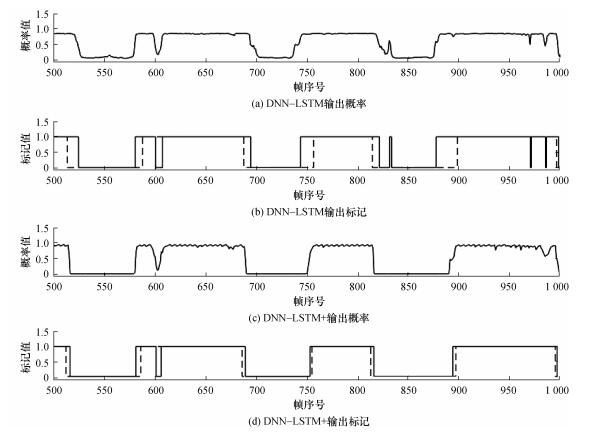
Abstract Voice activity detection (VAD) algorithms based on deep neural networks (DNN) ignore the temporal correlation of the acoustic features between speech frames which significantly reduces the performance in noisy environments. This paper presents a hybrid deep neural network with long-short term memory (LSTM) for VAD analyses which utilizes dynamic information from the speech frames. A context information based cost function is used to train the DNN-LSTM network. The noisy speech corpus used here was based on TIDIGITS and Noisex-92. The results show that the DNN-LSTM based VAD algorithm has better recognition accuracy than DNN-based VAD algorithms in noisy environment which shows that this cost function is more suitable than the traditional cost function.
|
| Keywords
voice activity detection
deep neural network
long-short term memory
|
|
|
|
Issue Date: 15 May 2018
|
|
|
[1] BENYASSINE A, SHLOMOT E, SU H Y, et al. A robust low complexity voice activity detection algorithm for speech communication systems[C]//Speech Coding for Telecommunications Proceeding. Pocono Manor, USA:IEEE, 1997:97-98.
[2] CHO N, KIM E K. Enhanced voice activity detection using acoustic event detection and classification[J]. IEEE Transactions on Consumer Electronics, 2011, 57(1):196-202.
[3] CHANG J H, KIM N S. Voice activity detection based on complex Laplacian model[J]. Electronics Letters, 2003, 39(7):632-634.
[4] RAMIREZ J, YELAMOS P, GORRIZ J M, et al. SVM-based speech endpoint detection using contextual speech features[J]. Institution of Engineering and Technology, 2006, 42(7):426-428.
[5] ZHANG X L, WU J. Deep belief network based voice activity detection[J]. Audio, Speech, and Language Processing, 2013, 21(4):691-710.
[6] GHOSH P K, TSIARTAS A, NARAYANAN S. Robust voice activity detection using long-term signal variability[J]. IEEE Transactions on Audio Speech & Language Processing, 2011, 19(3):600-613.
[7] SALISHEV S, BARABANOV A, KOCHAROV D, et al. Voice activity detector (VAD) based on long-term Mel frequency band features[C]//International Conference on Text, Speech, and Dialogue. Brno, Czech Republic:Springer International Publishing, 2016:352-358.
[8] ZHOU Q, MA L, ZHENG Z, et al. Recurrent neural word segmentation with tag inference[M]. Kunming, China:Natural Language Understanding and Intelligent Applications Springer International Publishing, 2016.
[9] HAS,IM SAK, SENIOR A, RAO K, et al. Learning acoustic frame labeling for speech recognition with recurrent neuralnetworks[C]//International Conference on Acoustics, Speech and Signal Processing. Brisbane, Australia:IEEE, 2015:4280-4284.
[10] ZHANG X L, WANG D. Boosted deep neural networks and multi-resolution cochleagram features for voice activity detection[J]. Speech and Signal Processing, 2014:6645-6649.
[11] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 2012, 9(8):1735-1780.
[12] GRAVES A. Supervised sequence labelling with recurrent neural networks[M]. Berlin, Germany:Springer-Verlag, 2012.
[13] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(1):2493-2537.
[14] DUCHI J, HAZAN E, SINGER Y. Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2011, 12(7):2121-2159.
[15] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout:A simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1):1929-1958.
[16] PEARCE D, HIRSCH H G. The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions[C]//The Proceedings of the 6th International Conference on Spoken Language Processing (Volume Ⅳ). Beijing, China:Interspeech, 2000:29-32.
[17] SHAO Y, JIN Z, WANG D L, et al. An auditory-based feature for robust speech recognition[C]//International Conference on Acoustics, Speech and Signal Processing. Taipei, China:IEEE, 2009:4625-4628.
[18] HE K, ZHANG X, REN S, et al. Delving deep into rectifiers:surpassing human-level performance on imagenet classification[C]//IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015:1026-1034. |
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|
 2018,
Vol. 58
2018,
Vol. 58