

绿色建筑是中国建筑业推进节能减排的工作重点。随着建筑节能技术的不断发展,如何在设计阶段选择合适的节能方案已成为一个复杂的决策问题。传统节能方案的选择往往依赖于设计师经验,具有一定局限性,难以在复杂设计环境中综合考虑技术、成本等因素。
利用机器学习算法进行建筑成本效益预测的研究较多,包括利用多种人工神经网络、遗传算法等机器学习技术对成本效益进行预测。例如,刘静[17]利用遗传算法-支持向量机(genetic algorithm-support vector machine,GA-SVM) 模型对装配式建筑的成本进行了预测分析;代倩茹[18]利用双变异粒子群优化-反向传播(particle swarm optimization-back propagation,PSO-BP)神经网络对装配式建筑及构件的成本进行准确预测。但这些研究集中于建造成本预测,对绿色建筑增量成本预测考虑较少。这可能是因为经过认证的绿色建筑样本量较少,需考虑到的决策条件属性较多,数据处理存在挑战且难以达到期望的预测效果,特别是在设计阶段信息并不充分的条件下实现成本预测模型构建存在一定困难。因此,能否利用CBR方法挖掘已有样本信息来确定技术方案,并结合机器学习算法对所确定的技术方案进行成本预测,仍值得深入研究。
建筑初步设计阶段是节能设计的关键环节,可提前优化节能效果与绿色建筑等级,避免后期成本增加。该阶段确定的关键条件属性影响较大,星级指标的确定也会影响设计选择与参数确定。但是,初步设计阶段已知信息少且依赖专家经验。为提升决策效率,本研究针对此场景的决策需求,提出将CBR和机器学习算法相结合的建筑节能方案智能决策模型。在该模型中,CBR方法用于确定建筑节能技术方案,机器学习算法则用于预测方案实施的增量成本。具体而言,CBR方法通过分析案例库中的历史案例,提供关于节能技术方案的重要参考值,如窗墙比、围护结构传热系数、新型热泵空调负荷比例等;而基于机器学习的增量成本预测模型则通过对这些参考值和其他设计前期已知的条件属性进行综合分析,预测出相应的绿色增量成本,从而为决策者提供更加全面的信息支持。
1 基于经验知识的建筑节能方案智能决策模型框架
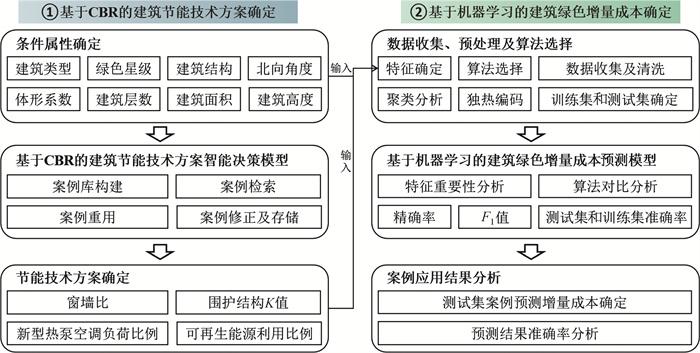
1) 基于CBR的建筑节能技术方案确定。该阶段的核心为利用CBR建立建筑节能技术方案智能决策模型。该模型的输入为建筑类型、绿色星级、建筑结构等建筑设计前期已知的信息,输出为《绿色建筑设计标识申报书》和《绿色建筑设计标识自评估报告》中的关键能耗指标,具体包括:4个方向的窗墙比、围护结构传热系数K、新型热泵空调负荷比例、可再生能源提供生活用水比例及可再生能源提供电量比例。第1阶段的输出也将作为第2阶段的重要输入特征。
2) 基于机器学习的建筑绿色增量成本确定。该阶段的核心为基于机器学习算法的建筑绿色增量成本预测模型。该模型的输入特征为设计前期已知的第1阶段的输入条件属性,及根据条件属性确定的最相似案例对应的重用节能技术方案。本文将对不同算法进行对比分析,最终确定学习效率较高的算法作为模型核心。模型输出为预测增量成本。
最终,本研究所构建的基于经验知识的建筑决策模型通过建筑设计前期已知的条件属性,利用经验知识,确定节能技术方案关键参数,进而确定该节能技术方案可能的绿色增量成本,为决策者提供参考。
2 基于案例推理的建筑节能技术方案确定模型
2.1 案例推理框架
本研究基于案例推理的建筑节能技术方案确定阶段具体包括4个步骤:建筑节能案例库构建、相似案例检索、节能案例技术方案重用、案例修正及存储。首先,收集对建筑节能技术方案确定有参考价值的案例构建案例库。随后,通过计算案例条件属性之间的相似度,从案例库中检索与当前建筑案例最相似的节能案例。然后,将最相似案例的节能技术方案作为目标问题的初步解决方案。此阶段的重点在于根据新问题的具体情况对过去的解决方案进行适当的调整和重用。当问题成功解决后,将当前建筑案例存储到建筑节能案例库中,以供未来类似问题参考。
对于相似案例检索这一步骤,本研究利用余弦相似度进行计算。余弦相似度是一种常用的相似性度量方法,常用于文本分析、信息检索和推荐系统等研究中[19]。余弦相似度通过关注向量的方向而非大小来忽略向量长度差异,其结果介于-1和1之间,直观地表示相似程度。该方法仅需已知点积和模长,计算效率高,在高维空间中表现良好,对稀疏向量具有鲁棒性,因此在处理高维和稀疏数据时较为有效。向量的每个维度都可以表示特征的权重,具体如式(1)所示。本研究中CBR模型基于Python中的Sklearn库实现,核心语句为Cosine Similarity模块,模型输出为相似度结果。
其中:A和 B是2个向量,Ai和Bi是2个向量的分量,i≥1。
2.2 条件属性确定
本研究的条件属性选择分为3步:1) 通过查阅文献资料及标准规范,找出与建筑能耗和增量成本相关的影响因素,为模型建立提供参考;2) 所构建模型的应用场景为建筑初步设计阶段,由于该阶段已知信息有限,筛选该阶段已知的、有效的条件属性;3) 结合文献检索结果与实际初步设计阶段的设计任务书及相关规划文件,进一步确定纳入模型的条件属性,以在保证预测效果的同时避免因初步设计阶段数据未知而无法使用决策支持模型。最终纳入模型的条件属性如下:
1) 绿色建筑星级。根据《绿色建筑评价标准》(GB/T 50378),目前共有3个等级的绿色建筑,分别是一星级、二星级和三星级。星级反映了初步设计时对绿色建筑效果的期望,也反映了绿色建筑完成时的效果。一般星级要求越高,需要使用的绿色建筑相关技术越多,增量成本越高。
2) 建筑类型。不同类型建筑的用能特点不同,对绿色建筑技术的选择也有不同的偏好,可能造成不同的绿色建筑增量成本。本研究所涉及的建筑类型包括办公建筑、商场建筑、科研建筑、旅馆建筑、综合建筑和文化建筑。
3) 建筑面积。建筑面积是影响绿色建筑技术选择及增量成本的重要因素。以暖通空调系统为例,如采用地源热泵技术,则需要考虑空调所辐射的建筑面积来计算增量成本。
4) 建筑高度。建筑高度也是影响某些绿色建筑技术增量成本的重要因素。以围护结构技术为例,建筑高度越高,所需要的围护结构保温材料越多,因此增量成本可能越高。
5) 建筑层数。建筑层数和建筑高度类似,也可能会从材料数量的角度影响增量成本。此外,建筑层数还与一些绿色建筑技术的应用难度以及可行性相关。
6) 建筑结构。不同建筑结构在进行绿色建筑技术选择时会有不同的偏好,而应用不同技术的难度和成本也会有所区别。根据所搜集到的案例情况,本研究所涉及的建筑结构包括框架结构、剪力墙结构以及框架-剪力墙结构。
7) 北向角度。北向角度涉及光照问题,因此可能会导致不同的绿色建筑技术的应用,从而影响增量成本。
8) 体形系数。建筑体形决定建筑体形系数,不同体形系数的建筑采用的绿色建筑技术可能不同。比如,对于围护结构改造技术,不同体形系数的建筑的围护结构热工性能值要求不同,导致其绿色技术增量成本不同。
2.3 数据收集与处理
表 1 数据描述性统计结果 |
| 条件属性 | 取值范围 | 均值 | 方差 | 最小值 | 第一四分位数 | 中位数 | 第三四分位数 | 最大值 |
| 建筑面积/m2 | >0 | 35 094.81 | 42 951.30 | 1 753.00 | 9 136.01 | 21 066.76 | 41 084.50 | 285 421.90 |
| 建筑高度/m | >0 | 46.64 | 42.23 | 8.10 | 18.10 | 28.00 | 70.52 | 298.90 |
| 建筑层数/层 | >0 | 11.01 | 10.26 | 1.00 | 4.00 | 6.00 | 17.00 | 64.00 |
| 北向角度/(°) | 0~360 | 105.16 | 116.41 | 0.00 | 80.00 | 90.00 | 99.45 | 1 393.00 |
| 体形系数/m-1 | >0 | 0.19 | 0.08 | 0.07 | 0.13 | 0.18 | 0.24 | 0.48 |
2.4 案例推理结果分析
将147个案例按照3∶7分为测试集和训练集,根据测试案例的条件属性与训练案例进行相似度计算,找到相似度最高的案例序号,如表 2第2列所示。可以将训练案例已知的屋顶、外墙和窗户的传热系数K值,新型热泵空调负荷比例、太阳能热水占比、太阳能发电占比,以及具体的节能方案进行重用,为测试集中案例的绿色节能技术选择提供参考(见表 2)。比如,案例12是位于镇江市的科研教育建筑项目,根据其条件属性预期匹配到的是南京市条件属性类似的项目,表明所提出的基于CBR的建筑节能方案智能决策模型具有一定的可靠性。根据相似度结果,案例12可以重用案例128的窗墙比数值以及围护结构K值,而且其可选的节能方案包括:超过50%的新型热泵空调、利用可再生能源提供生活用水比例为48%左右。因此,基于CBR的建筑节能方案智能决策模型可以根据目标案例的少量的条件属性,给出最相似案例的窗墙比、围护结构K值,以及新型热泵空调负荷、可再生能源利用比例等绿色建筑评价的重要指数以供决策参考。
表 2 测试集案例推理结果 |
| 测试集案例 | 最相似案例 | 相似度 | 屋顶K值 | 外墙K值 | 窗户K值 | 新型热泵空调负荷比例/% | 可再生能源提供生活用水比例/% | 可再生能源提供电量比例/% |
| 10 | 9 | 0.98 | 0.50 | 0.91 | 2.60 | 0.00 | 19.38 | 0.00 |
| 12 | 128 | 0.99 | 0.58 | 0.71 | 2.30 | 52.54 | 48.31 | 0.00 |
| 13 | 79 | 0.99 | 0.55 | 0.55 | 2.30 | 0.00 | 0.00 | 0.00 |
| 20 | 147 | 0.76 | 0.57 | 0.46 | 2.60 | 70.23 | 0.00 | 0.00 |
| 21 | 65 | 0.94 | 0.54 | 0.76 | 2.30 | 0.00 | 76.70 | 0.00 |
| 24 | 5 | 0.96 | 0.60 | 0.78 | 2.20 | 78.00 | 33.00 | 0.00 |
| 28 | 117 | 1.00 | 0.55 | 0.85 | 2.63 | 100.00 | 63.83 | 0.00 |
| 31 | 148 | 0.99 | 0.39 | 0.42 | 1.80 | 97.83 | 0.00 | 0.00 |
| 32 | 73 | 0.99 | 0.53 | 0.73 | 2.30 | 0.00 | 46.39 | 0.00 |
| 33 | 7 | 0.62 | 0.60 | 0.79 | 2.22 | 78.00 | 33.00 | 0.00 |
| 43 | 112 | 0.86 | 0.49 | 0.67 | 2.60 | 0.00 | 0.00 | 0.00 |
| 61 | 106 | 0.98 | 0.54 | 0.62 | 2.50 | 0.00 | 0.00 | 0.00 |
| 69 | 105 | 0.99 | 0.38 | 0.56 | 2.60 | 0.00 | 0.00 | 2.50 |
| 80 | 135 | 0.93 | 0.51 | 0.62 | 2.40 | 0.00 | 0.00 | 3.35 |
| 82 | 134 | 0.99 | 0.59 | 0.78 | 2.60 | 0.00 | 0.00 | 0.00 |
| 83 | 130 | 0.88 | 0.74 | 0.63 | 2.40 | 0.00 | 10.98 | 0.00 |
| 85 | 95 | 0.99 | 0.46 | 0.79 | 3.40 | 0.00 | 42.11 | 0.00 |
| 94 | 109 | 0.96 | 0.65 | 0.92 | 2.70 | 0.00 | 0.00 | 4.57 |
| 100 | 30 | 0.99 | 0.60 | 0.66 | 2.30 | 0.00 | 100.00 | 0.00 |
| 101 | 163 | 0.96 | 0.60 | 0.72 | 3.00 | 20.35 | 100.00 | 0.00 |
| 115 | 139 | 0.94 | 0.36 | 0.86 | 2.00 | 0.00 | 58.49 | 0.00 |
| 123 | 55 | 0.84 | 0.73 | 1.59 | 3.15 | 0.00 | 0.00 | 4.92 |
| 124 | 104 | 0.99 | 0.60 | 0.66 | 2.70 | 0.00 | 100.00 | 0.00 |
| 137 | 84 | 0.90 | 0.70 | 0.73 | 2.40 | 0.00 | 0.00 | 0.00 |
| 143 | 118 | 0.96 | 0.53 | 0.48 | 2.70 | 0.00 | 51.10 | 0.00 |
| 152 | 142 | 0.95 | 0.48 | 0.46 | 2.25 | 0.00 | 46.90 | 0.00 |
| 153 | 92 | 1.00 | 0.58 | 0.35 | 3.00 | 0.00 | 7.50 | 14.40 |
| 157 | 56 | 0.93 | 0.50 | 1.39 | 3.00 | 0.00 | 0.00 | 2.60 |
| 162 | 51 | 1.00 | 0.63 | 1.02 | 3.50 | 0.00 | 0.00 | 2.07 |
当前测试集案例相似度绝大多数大于0.8,少数为0.6~0.8,表明所构建的案例推理模型具有一定的稳定性。若出现目标案例与现有案例相似度均不高的情况,可对条件属性选择的准确性作进一步分析,并对案例库进行扩展,必要时可采用专家咨询法对推理结果进行补充和调整。此外,本研究选择与测试集相似度最高的案例作为参考案例,但如果测试集案例与现有案例相似度均很高且相近,而这些案例的技术方案存在明显差异时,需要考虑技术可行性、建筑地理位置等多种因素进行适当调整,再进行方案重用。
3 基于机器学习的增量成本预测模型
3.1 算法简介
1) 极端梯度提升(extreme gradient boosting,XGBoost)。XGBoost是基于Boosting决策树算法的一种改进算法。XGBoost的优化标准完全基于目标函数的最小化推导,并在推导过程中插入了二阶Taylor公式进行展开,以允许用户定义损失函数。此外,XGBoost算法继承了以往决策树相关算法的随机采样、随机特征选择和保证高效学习等实用功能,使特征计算能够并行化。
2) 支持向量机(support vector machine,SVM)。支持向量机作为一种基于统计学习理论的广义线性分类器,可以通过核方法进行非线性分类。SVM通过非线性映射将输入向量从原始空间转换为Hilbert高维空间,在该特种空间中,存在超曲面可以将正样本和负样本分开。支持向量机可以提高泛化性能,解决高维问题,同时避免因为神经网络结构选择和局部样本数据极小带来的误差。
3) 随机森林(random forest,RF)。随机森林算法的原理是将训练集分成若干个新的训练集,并为训练样本集构建新的训练决策树。随机森林通过组合多个决策树分类器,可以处理高维数据且不需要特征选择,一定程度上提高了模型的预测效果,避免了过拟合。
4) 人工神经网络(artificial neural network,ANN)。人工神经网络模仿生物神经网络,通过大量互联节点组成多层网络进行信息处理。ANN使用反向传播算法调整连接权重以最小化损失函数,适用于图像识别、自然语言处理等领域。其训练过程采用随机梯度下降等方法提高收敛速度,并通过并行计算提高计算效率和模型性能。
本研究中基于机器学习算法的增量成本预测模型的核心处理语句为Sklearn库中的RandomForestClassifier、SVC、XGBClassifier和MLPClassifier模块。模型输出为增量成本预测结果。
3.2 数据预处理
通过对不同条件属性数据的分析,本文对不同数据利用不同技术进行处理:对分类数据进行了独热编码;对于极值较大的连续性数据,比如建筑面积、建筑高度等,尝试采用聚类分析,将其转化为分类数据。具体内容如表 3所示。将全部147个有效案例构成的数据集的20%作为测试集,80%作为训练集。
表 3 条件属性预处理结果 |
| 条件属性 | 类型 | 编码 | 编码形式 |
| 星级 | 分类数据 | 独热编码 | [1, 0, 0], [0, 1, 0], [0, 0, 1] |
| 建筑类型 | 分类数据 | 独热编码 | [1, 0, 0, 0, 0, 0] … |
| 建筑面积 | 连续数据 | 聚类编码 | [0, 1, 2, 3, 4, 5, 6, 7] |
| 建筑高度 | 连续数据 | 聚类编码 | [0, 1, 2, 3, 4, 5, 6, 7] |
| 建筑层数 | 离散数据 | 数值编码 | |
| 北向角度 | 连续数据 | 数值编码 | |
| 建筑结构 | 分类数据 | 独热编码 | [1, 0, 0], [0, 1, 0], [0, 0, 1] |
| 体形系数 | 连续数据 | 数值编码 | |
| 增量成本 | 连续数据 | 独热编码 | [1, 0, 0, 0, 0], [0, 1, 0, 0, 0] … |
3.3 特征重要性分析
利用KMeans函数将增量成本预测结果分成3~8类,经过调整发现,将其分成5类可以最大程度上避免极值对预测结果的影响,也能有相对准确的结果。因此,将增量成本按照0~132.02元/m2、132.02~273.98元/m2、273.98~436.91元/m2、436.91~739.61元/m2及739.61~1 198.92元/m2分成5类。在机器学习预测模型中,虽根据前期调研及模型输出可确定部分特征,但这些特征是否准确以及它们之间存在哪些内在联系仍需进一步分析。因此,本研究应用特征重要性分析,一方面,进行特征选择,去除不重要的特征以简化模型、提高效率;另一方面,有助于理解模型决策过程哪些特征对结果影响较大。本节利用机器学习算法中的import_plot模块来实现,其原理是通过计算特征在决策树构建过程中对目标变量的贡献程度,以特征在所有分支中的平均不纯度减少量确定重要性。特征重要性分析结果如图 3所示。
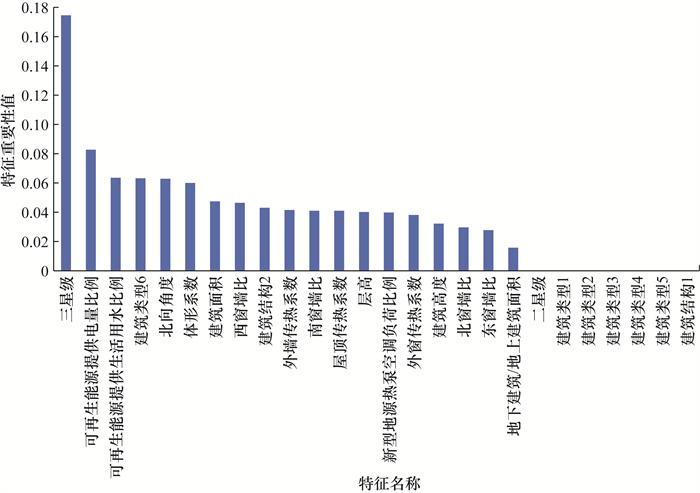
三星级为增量成本中最重要的特征,这是因为星级越高对节能的要求越高,对应的绿色建筑增量成本也就越大。其次,比较重要的特征依次是可再生能源利用比例、建筑类型、北向角度、体形系数、屋顶传热系数、建筑面积、西窗墙比等。图 1所示的模型框架的第2阶段增量成本预测模型中很多重要特征,如可再生能源利用比例、体形系数、北向角度等,均来自于第1阶段基于CBR模型的输出,说明了第1阶段基于CBR的建筑节能技术方案确定的重要性。重要性几乎为0的特征包括其他5种建筑类型以及二星级和建筑结构1。在整个模型调整的过程中,尝试将重要性较高的特征逐个剔除观察模型预测准确率的变化,以此避免对准确率有负向影响的特征存在模型中。结果发现,去掉体形系数特征后,模型准确率得到了提升。因此,最终只剔除体形系数特征,保留了其余特征。
3.4 机器学习算法比较与选择
本研究基于常用的算法评价指标,包括精确率、训练集准确率、测试集准确率以及F1值,对比了4种不同的机器学习算法的增量成本预测结果,如表 4所示。
表 4 4种机器学习算法的增量成本预测结果 |
| 机器学习算法 | 训练集准确率/% | 测试集准确率/% | 精确率/% | F1值 |
| 随机森林 | 100.00 | 68.97 | 54.79 | 0.61 |
| 支持向量机 | 48.21 | 48.28 | 23.31 | 0.31 |
| 极端梯度爬升 | 100.00 | 72.41 | 75.67 | 0.72 |
| 人工神经网络 | 88.39 | 44.83 | 37.59 | 0.41 |
表 4表明,增量成本预测模型中,基于XGBoost算法训练的模型的测试集准确率最高, 为72.41%,远高于其他3种算法,其F1值为0.72、精确率为75.67%,均高于其他3种算法,因此最终在增量成本预测中选择了XGBoost算法。
3.5 案例应用分析与讨论
利用案例测试集已知的条件属性和基于CBR确定的最相似案例重用的决策变量,最终基于所构建的增量成本预测模型得出的结果的预测准确率如图 4所示。第2类增量成本(132.02~273.98元/m2)预测准确率最高,为71.43%,其次是第1类增量成本(0~132.02元/m2)预测准确率,为66.67%。这两类增量成本预测准确率较高可能是因为训练集中这部分增量成本的训练案例占比较大,机器学习算法挖掘效率相对较高。相反地,第5类增量成本(739.61~1 198.02元/m2)预测准确率为0%,这类增量成本位于聚类时的极值所在处。现实中导致增量成本过高的原因不仅是决策条件属性特殊,也有项目特有的额外要求,如业主的个性化要求或地标性建筑等,导致虽仍是三星级绿色建筑,但其节能技术方案不仅仅是基础的可再生能源利用及新型热泵空调的运用,因此大大增加了增量成本,导致所构建模型的预测结果不准确。第3类(273.98~436.91元/m2)和第4类增量成本(436.91~739.61元/m2)预测准确率分别为20%和33.33%,因为测试集中处于这两个区间的样本占比较小,仅为10%左右,所以预测的随机性相对较大。
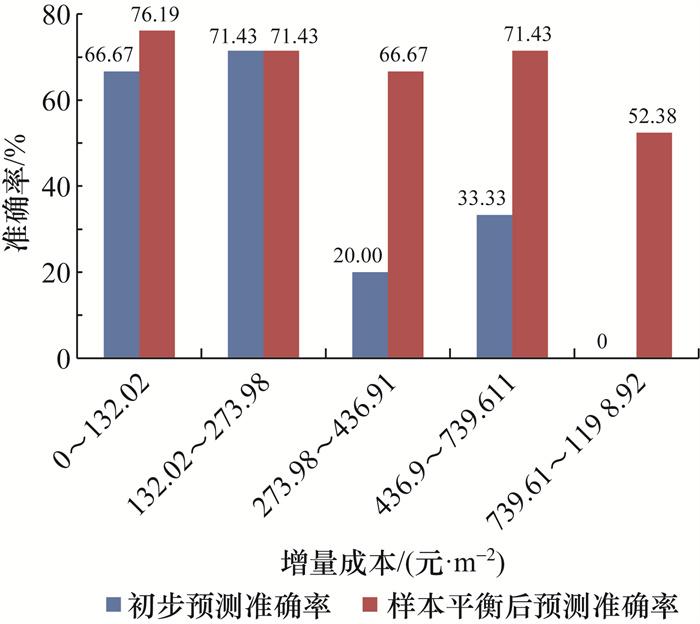
根据初步预测准确率,本研究进行如下调整:首先针对样本分布不平衡,利用合成少数过采样技术(synthetic minority over-sampling technique,SMOTE) 来平衡样本,使5类增量成本分布平衡;接着针对极值影响的问题,尝试利用标准化处理减弱极值的影响。通过以上处理得到最终结果如图 4所示,即第1类增量成本预测准确率最高,达到76.91%,第2类和第4类增量成本预测准确率均超过了70%,但第5类增量成本预测准确率仍不理想。这也说明业主的个性化要求和极值影响了增量成本预测准确率。
4 结论与展望
本文基于案例推理和机器学习技术提出了建筑节能方案智能决策模型,旨在提高绿色建筑技术选择的科学性和决策效率。通过将CBR方法与机器学习算法相结合,本研究构建了节能技术方案选择与增量成本预测的集成模型。该模型利用案例推理的优势,通过设计前期已知的8类条件属性检索历史案例,为目标建筑提供相似性较高的绿色建筑,并重用其节能技术方案,包括围护结构K值、窗墙比、可再生能源利用比例等指标。随后,利用机器学习算法对CBR输出的节能技术方案的绿色增量成本进行预测。结果表明,本研究所构建的集成模型整合了基于CBR的建筑节能方案决策与基于XGBoost算法的增量成本预测,不仅能够有效确定目标建筑的节能技术方案及其绿色增量成本范围,还能够达到72.14%的预测准确率。对于测试集,经过样本平衡和极值处理后,第1类增量成本预测准确率最高,为76.19%,第2类、第3类及第4类增量成本预测准确率也达到了70%左右,但由于受到业主个性化要求和极值的影响,第5类增量成本预测准确率仍不高,仅为52.38%。
本研究提出的智能决策模型为建筑节能方案的选择与实施提供了新的方法与视角。模型通过集成经验知识和数据驱动的分析方法,显著提高了节能方案选择的合理性和决策的精确性,提升了决策效率,减少了对专家经验知识的依赖。然而,目前的模型在数据处理和多源数据集成方面仍存在问题,未来研究需探索更多的数据挖掘技术,以期进一步提高节能技术方案确定及绿色增量成本预测的准确性。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}