

快速自适应方法是解决口音语音识别的主要方法之一,包括迁移学习(transfer learning)[5]、元学习(meta-learning)[6]和在模型结构中插入口音适配器[7-8]。上述方法使语音识别系统能在短时间内快速自适应到新的口音,从而提高口音语音识别的性能。近年来,研究人员开始将语音识别和口音识别任务放在同一模型框架下,解决多口音语音识别问题。文[9]通过在语音转录文本的开始或结束位置插入口音类别标签,可在同一模型框架下同时学习口音和语音内容信息。文[10]则通过领域对抗训练学习口音一致的声学表征,提高口音语音识别的鲁棒性。与上述方法不同,文[11-13]利用多任务学习(multi-task learning, MTL)[14]方法,通过共享部分底层神经网络和利用多任务的互补信息提高各任务的性能。文[11]探索使用口音嵌入和多任务学习改进口音语音识别,提出了一种多任务学习框架。该框架联合学习一个口音分类模型和口音声学模型,同时模型还引入了一个单独的网络提取口音嵌入,以增强语音声学表征。文[13]在多任务学习框架下,同时执行端到端(end-to-end, E2E)口音识别和语音识别任务,所建议的框架不仅更紧凑,而且可以产生与独立系统相当,甚至更好的结果。
综上所述,基于多任务学习的方法可以同时解决口音识别任务和语音识别任务,简化系统的复杂性,使模型更紧凑;同时,多任务之间的信息也可以互相补充,从而促进在各自任务上的性能提升。然而,这些方法也存在一些不足。一方面,未深入探索和分析不同编码器层包含的口音信息和对语音识别性能的影响;另一方面,未进一步探索口音识别与语音识别任务之间的相互作用,如利用语音识别信息辅助口音识别。
本文在ESPnet[15]环境下搭建口音识别和语音识别多任务学习框架。首先,通过共享部分编码器底层网络,同时对口音识别和语音识别进行建模,探索不同编码器层包含的口音信息和对语音识别性能的影响。其次,为进一步探索口音识别与语音识别任务之间的相互作用,本文对编码器隐层特征进行分析,发现口音特征大部分由空白帧组成,而更能反映口音差异的有效标签帧并未发挥主要作用,因此,本文在多任务学习优势下,提出基于连接主义时序分类(connectionist temporal classification,CTC)尖峰特征的口音识别方法,采用基于CTC的伪标签对齐方法[16],在线提取CTC伪标签对应的尖峰特征,并用于口音识别。
1 多任务学习方法
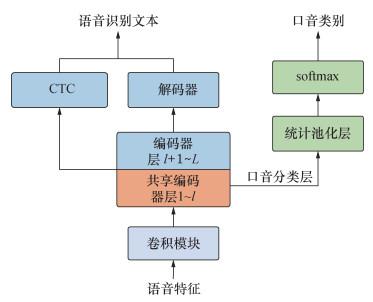
1.1 混合CTC-attention模型
混合CTC-attention模型结合了CTC和注意力模型的优点,显著提高了语音识别性能,因而被广泛关注。
CTC[18]是一种连接主义时序分类器,常用于序列到序列的学习方法,无须帧级别标注,在输出序列和最终标签之间增加了多对一的映射关系,并在此基础上定义了CTC损失函数,其训练过程实际上是自动对齐使损失函数最小化的过程。
基于注意力机制[19]的Encoder-Decoder模型是一种改进的序列到序列模型,通过在Encoder和Decoder之间加入注意力机制,通常称为交叉注意力(cross-attention),计算当前位置输出对编码器不同时刻输出的关注度;此外,其在编码器和解码器中引入了自注意力机制(self-attention),因此可计算当前位置对不同位置的关注度。注意力函数将查询(query)和一组键、值对(key-value)映射到输出。输出由值的加权和计算得到,其中分配给每个值的权重由查询与相应键的点积经过函数计算得到,权重和为1。常用的注意力函数为缩放点积注意力函数,表示如下:
其中:Attention为注意力函数;softmax为指数归一化函数;Q、K和V分别为查询、键、值向量组成的矩阵;dk为键的向量维度,对Q和K的点积进行缩放,防止将softmax函数推入梯度极小的区域。
多头注意力机制通过线性映射矩阵分别将查询、键、值映射到dq、dk和dv维度,多头注意力h决定映射次数。经过线性映射的多个查询、键、值并行经过注意力函数,产生dv维度的输出,将这些输出拼接起来再次经过线性映射得到最终的输出,多头注意力函数可表示如下:
其中:MultiHead为多头注意力函数;Concat为矩阵拼接函数;O为多头注意力函数的输出;head为其中一个注意力函数的输出;i为注意力头索引;$\boldsymbol{W}_i^Q \in \mathbb{R}^{d_{\text {model }} \times d_q}, \boldsymbol{W}_i^K \in \mathbb{R}^{d_{\text {model }} \times d_k}, \boldsymbol{W}_i^V \in \mathbb{R}^{d_{\text {model }} \times d_v}$, $\boldsymbol{W}^O \in \mathbb{R}^{h d_v \times d_{\text {model }}}$分别为查询、键、值、输出映射矩阵,dmodel为映射向量维度。多头注意力使模型能同时关注不同位置和不同特征子空间的信息,因此性能比单头注意力好。
混合CTC-attention模型最终的损失函数为CTC损失和注意力模型交叉熵损失的加权和,表示如下:
其中:$\mathcal{L}$ 为损失函数;$\mathcal{L}_{\mathrm{CTC}}$为CTC损失函数;$\mathcal{L}_{\mathrm{ATT}}$为注意力模块损失函数;λ为CTC损失的加权系数,0≤λ≤1;$\mathcal{L}_{\mathrm{ASR}}$为加权后的自动语音识别(automatic speech recognition,ASR)损失函数。
1.2 口音识别模型
基于深度学习的口音识别首先通过神经网络提取口音特征;其次,通过统计池化层获得句子级特征;再次,经过一层线性层和softmax层输出每种口音的概率分布;最后,利用交叉熵损失函数计算口音分类损失,表示如下:
其中:$\mathcal{L}_{\mathrm{AR}}$为口音识别(accent recognition, AR)损失函数;N为训练样本数;j为样本索引;p为输出的概率分布;y为真实标签的概率分布;Pooling为统计池化层;FC为全连接层;hl为编码器第l层的输出。
最终的多任务学习损失函数表示如下:
其中:α为口音损失的加权系数,0≤α≤1;$\mathcal{L}_{\mathrm{MTL}}$为最终的多任务损失函数。
2 基于CTC尖峰特征的口音识别方法
在口音识别和语音识别多任务学习框架的基础上,通过分析编码器的中间隐层特征,可发现大部分口音特征由空白(blank)帧组成,而更具有发音表征的非blank(即有效标签)帧未发挥主要作用,因此,本文提出了基于CTC尖峰特征的口音识别方法,可在训练过程中在线提取有效标签对应的尖峰特征。
2.1 CTC尖峰特性
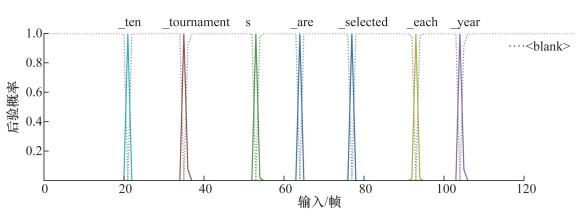
2.2 口音特征分析
通常情况下,口音识别直接使用编码器中间某一层的特征经过统计池化层获得口音特征向量,语音信号的每一帧特征均参与计算。为探索不同标签帧对口音识别的重要性,本文可视化分析了口音特征向量,包括非blank帧、blank帧和所有帧对应特征向量组成的口音特征。为获得相对准确的对齐信息和节省计算资源,本文采用与文[16]相同的对齐方法——直接利用CTC预测的伪标签获取对应的尖峰特征,CTC模块逐帧预测标签序列,包括blank,第n帧的伪标签表示如下:
其中:X为输入的语音特征,$\hat{y}$为输出对应的伪标签;pCTC为CTC输出标签的概率分布。
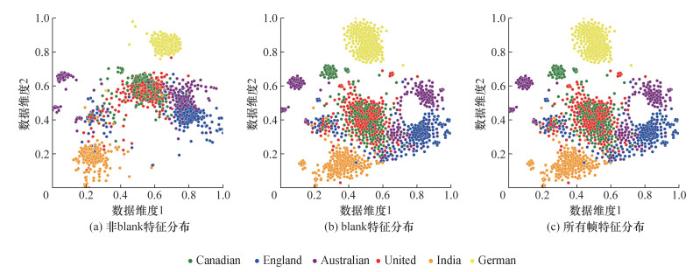
首先,本文从每种口音的测试数据中随机挑选200条;其次,提取每条数据的隐层编码特征;再次,计算CTC输出层的softmax概率,获得每一帧输出标签和对应位置索引;最后,根据上述获得的信息,分别计算编码器隐层特征非blank帧、所有blank帧、所有帧的统计池化特征,经过t分布随机邻域嵌入(t-distributed stochastic neighbor embedding,t-SNE)降维后进行可视化,分别如图 3a、3b和3c所示。经可视化分析可知,大部分口音特征由blank帧组成,其分布与所有帧特征分布基本一致,而更能反映口音差异的非blank特征未发挥主要作用,因此,本文将有效标签对应的尖峰帧作为口音识别的特征,以更好地区分不同地区口音的差异。
2.3 基于CTC尖峰特征的口音识别
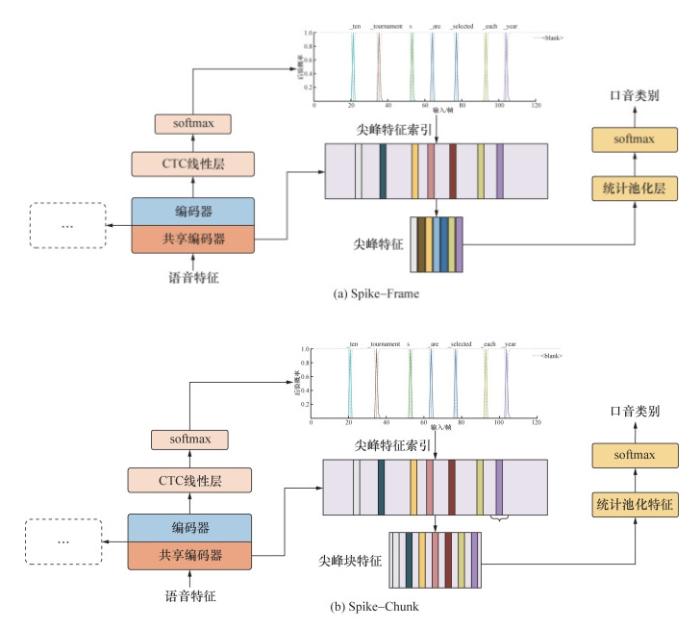
在语音识别和口音识别多任务学习框架下,本文首先使用在线提取非blank帧的方法,在模型训练前向计算过程中,计算CTC伪标签对齐信息;其次,通过非blank帧的索引获取对应隐层编码特征,并计算其统计池化特征,以作为最终的口音特征进行训练;最后,联合训练过程同步更新所有参数。由于语音序列的实际长度远大于文本序列,因此在提取口音特征时使用尖峰帧(Spike-Frame)和尖峰块(Spike-Chunk)特征进行试验,Spike-Chunk即在Spike-Frame索引左右各扩展一定帧数。口音特征提取过程如图 4所示。
3 试验结果与分析
3.1 试验数据及配置
表 1 试验数据 |
| 数据集 | 口音 | 缩写 | 语音数据时长/h | ||
| 训练集 | 验证集 | 测试集 | |||
| Common Voice 9.0 | Australian | AU | 365.80 | 92.40 | 50.77 |
| Canadian | CA | 124.82 | 31.20 | 17.28 | |
| England | EN | 104.39 | 26.01 | 14.66 | |
| German | GE | 59.16 | 14.62 | 8.22 | |
| India | IN | 50.79 | 12.84 | 7.07 | |
| United States | UN | 55.08 | 13.71 | 7.55 | |
| AESRC2020 | United Kingdom | UK | 18.50 | 1.54 | 2.21 |
| Russia | RU | ||||
| India | IND | ||||
| South of Korea | KR | ||||
| Japan | JPN | ||||
| China | CHN | ||||
| Portugal | PT | ||||
| United States | US | ||||
| Librispeech | — | — | 960.90 | 10.70 | 10.40 |
本文试验使用的语音数据的采样频率均为16 kHz,每个采样点均占16 bit,并使用窗长为25 ms、窗移为10 ms的汉明窗对语音信号进行分帧、加窗。在此基础上,对语音信号进行短时Fourier变换,并提取80维FBank(Filter Banks)特征用于神经网络模型的输入。本文试验的语音识别建模单元数为5 000,口音识别建模单元数为对应口音类别数。
模型采用基于注意力机制的编码器-解码器结构,语音特征经过2层卷积神经网络(convolutional neural network,CNN)进行4倍降采样,编码器包含12层Conformer[22]块,多头注意力维度为512,包含8个注意力头,前馈网络维度为2 048,卷积核大小为31,此外还利用批量标准化(BatchNorm)和Swish激活函数帮助训练深层次模型。解码器包含6层Transformer块,多头注意力维度为512,包含4个注意力头,前馈网络维度为2 048。在编码器的中间层添加口音分类损失,经线性映射输出对应口音类别,该模型总的参数量为116 M。
模型训练使用2张A100显卡,λ设为0.3,α设为0.1,优化器选择Adam,梯度更新设为4,学习率设为0.001,训练迭代50个epoch。为增强数据多样性,防止模型过拟合,本文试验对输入特征进行数据增强(SpecAug)[23],即分别对输入特征进行时间扭曲、频率掩码和时域掩码操作。
3.2 解码配置与评价指标
在解码阶段,本文提出的多任务学习方法支持同时输出口音分类结果和语音识别结果。口音分类取编码器第6层的特征输出,并对该特征进行统计池化,获得句子级别的口音分类特征,经过分类输出层,将概率最大的标签作为最终的口音输出。语音识别采用基于束搜索的标签同步解码算法,束大小设为20。试验分别将口音识别准确率(accuracy, Acc)和语音识别词错误率(word error rate, WER)作为口音识别和语音识别性能的评价指标。其中:Acc为对应口音识别正确的语音条数与该口音所有语音条数的比值,WER为字替换错误、删除错误、插入错误之和除以答案中的总字数,表示如下:
其中:accent_id为口音类型,Correct_Nums为正确语音条数,All_Nums为所有语音条数,Sub为替换错误字数,Del为删除错误字数,Ins为插入错误字数,Ref为答案中总字数。
3.3 试验结果分析
在口音识别和语音识别多任务学习框架下,选择不同的编码器层对口音识别和语音识别性能有一定影响。为探索不同层编码器特征包含的口音信息和对语音识别性能的影响,本文对不同层编码器特征进行消融试验,分别将编码器4—11层的特征用于口音识别,观察口音识别和语音识别性能的变化,试验在Common Voice数据集上进行,性能变化曲线如图 5所示。分析可知,口音识别性能的整体变化趋势是先上升后下降。由此可知,编码器浅层特征对口音识别的建模能力并不是很强,随着编码器层数的加深,更高层的编码器特征更倾向于识别与口音、说话人、信道等无关的文本序列,逐渐淡化了口音信息。编码器第6层输出特征包含的口音信息最丰富,用于口音识别时,口音性能最优。同时,在该层增加口音分类损失,对编码器特征进行增强,语音识别也取得了最优性能。因此,后续试验将编码器第6层输出特征用于口音识别,并在此基础上验证本文方法的有效性。
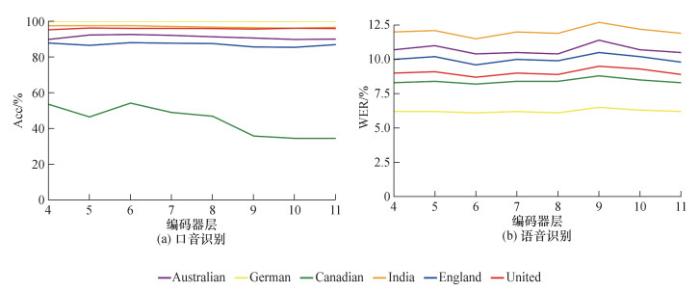
表 2 Common Voice数据集的WER |
| 训练方法 | AU | CA | EN | GE | IN | UN | 平均值 |
| ASR | 10.9 | 8.6 | 10.3 | 6.3 | 12.4 | 9.2 | 9.7 |
| AR+ASR | 10.4 | 8.2 | 9.6 | 6.1 | 11.5 | 8.7 | 9.1 |
表 3 AESRC2020数据集的WER |
| 训练方法 | UK | RU | IND | KR | JPN | CHN | PT | US | 平均值 |
| ASR | 16.8 | 21.9 | 21.7 | 17.4 | 18.9 | 23.5 | 18.7 | 19.7 | 19.7 |
| AR+ASR | 11.2 | 15.2 | 14.8 | 10.2 | 11.5 | 19.7 | 11.2 | 12.2 | 13.2 |
| ASR(Pretrain) | 2.5 | 11.9 | 9.1 | 7.6 | 9.2 | 11.5 | 6.9 | 6.0 | 7.8 |
| AR+ASR(Pretrain) | 1.8 | 11.1 | 7.3 | 7.0 | 8.7 | 10.1 | 5.8 | 4.8 | 6.8 |
在口音识别和语音识别多任务学习框架下,本文分别验证了Spike-Frame和Spike-Chunk方法在口音识别和语音识别任务上的性能。Common Voice和AESRC2020数据集上的试验结果分别如表 4和5所示,与基线多任务模型相比,Spike-Chunk方法的口音识别性能分别绝对提升了0.7%和1.9%,语音识别性能基本无损失。对比Spike-Frame与Spike-Chunk方法可知,与Spike-Frame相比,Spike-Chunk的口音识别性能虽略有提升,但变化不大。由此表明,有效标签对应的尖峰帧包含了大部分口音信息,周围blank帧可在一定程度上提升口音识别性能,但不明显。
表 4 Common Voice数据集上的口音识别和语音识别性能 |
| 任务 | 评价指标 | 训练方法 | AU | CA | EN | GE | IN | UN | 平均值 |
| AR | Acc | AR+ASR | 92.7 | 54.2 | 88.1 | 100.0 | 97.6 | 96.1 | 91.7 |
| Spike-Frame AR+ASR | 93.2 | 58.5 | 89.3 | 100.0 | 97.9 | 96.1 | 92.3 | ||
| Spike-Chunk AR+ASR | 93.5 | 58.5 | 89.2 | 100.0 | 98.2 | 96.2 | 92.4 | ||
| ASR | WER | AR+ASR | 10.4 | 8.2 | 9.6 | 6.1 | 11.5 | 8.7 | 9.1 |
| Spike-Frame AR+ASR | 10.3 | 8.1 | 9.6 | 6.2 | 11.5 | 8.7 | 9.1 | ||
| Spike-Chunk AR+ASR | 10.3 | 8.1 | 9.7 | 6.2 | 11.5 | 8.7 | 9.1 |
表 5 AESRC2020数据集上的口音识别和语音识别性能 |
| 任务 | 评价指标 | 训练方法 | UK | RU | IND | KR | JPN | CHN | PT | US | 平均值 |
| AR | Acc | AR+ASR(Pretrain) | 92.9 | 72.0 | 90.2 | 80.4 | 62.5 | 72.2 | 78.6 | 61.9 | 75.6 |
| Spike-Frame AR+ASR(Pretrain) | 93.0 | 69.8 | 91.5 | 84.3 | 69.5 | 74.6 | 79.8 | 62.8 | 77.5 | ||
| Spike-Chunk AR+ASR(Pretrain) | 93.0 | 70.8 | 91.3 | 83.5 | 69.1 | 75.1 | 80.1 | 62.4 | 77.5 | ||
| ASR | WER | AR+ASR(Pretrain) | 1.8 | 11.1 | 7.3 | 7.0 | 8.7 | 10.1 | 5.8 | 4.8 | 6.8 |
| Spike-Frame AR+ASR(Pretrain) | 1.8 | 11.1 | 7.1 | 7.1 | 8.7 | 10.1 | 5.8 | 4.8 | 6.8 | ||
| Spike-Chunk AR+ASR(Pretrain) | 1.8 | 11.2 | 7.2 | 7.0 | 8.7 | 10.2 | 5.9 | 4.8 | 6.8 |
3.4 所提方法与已有工作的对比
AESRC2020数据集上的对比结果如表 6所示,与单独训练口音识别(AR only)和语音识别(ASR only)的模型相比,本文方法的口音识别和语音识别性能提升较大。由此表明:口音识别任务可在一定程度上增强特定口音的声学特征,进而辅助语音识别任务;语音识别任务通过学习语音序列对应的文本忽略信道、说话人信息,降低信道和说话人对口音识别的影响,提升口音识别性能。对比文[9] 中的方法(method-1和method-2分别在语音识别标签开头和结束位置添加口音标签)发现,在语音识别任务上,口音信息同样可以辅助语音识别任务,但口音识别任务上的性能较差,表明本文方法有效。与文[24]中基于语言声学相似性偏移的方法相比,口音识别性能相近,但本文方法基于多任务学习框架,可以在线实时获取有效标签对应的尖峰帧,并可简化训练流程和节省存储空间。
4 结论
为进一步探索多任务学习框架下口音识别与语音识别任务之间的相互作用,本文提出一种基于尖峰特征的口音识别和语音识别多任务学习方法。在多任务学习框架下,本文首先探索了不同编码器层包含的口音信息和对语音识别性能的影响,结果表明,经过口音信息增强的编码器特征可进一步提升语音识别性能;其次,在线提取了基于CTC伪标签的尖峰特征,并用于口音识别,在Common Voice和AESRC2020数据集上的试验结果表明,提取的尖峰特征能更好地反映口音信息,并能摒弃冗余信息,一定程度上提升了口音识别性能,同时对语音识别性能基本无影响;最后,在AESRC2020数据集上对比了本文方法与现有方法的性能,结果表明,本文方法的口音识别和语音识别性能均较好。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}