

情感分析是自然语言处理的一个重要子任务,其核心是挖掘句子中的情感方面和情感极性对并进行相关分析,主要分为显式情感分析(explicit sentiment analysis,ESA)和隐式情感分析(implicit sentiment analysis,ISA)。目前,ESA在情感分析任务中占主导地位,其评论句子中同时显式地包含了情感片面词和情感极性。与显式情感分析不同,隐式情感分析更具挑战性,因为在评论句中并没有显式地表明情感观点,需要深层语义理解才能获取到。如图 1中“Case#1”和“Case#2”分别是关于情感片面词“笔记本”的显式和隐式情感的例句。其中,“Case#1”中的“The battery life of laptop is amazing”,情感方面(橙色标注的“battery life”)和情感极性(绿色标注的“amazing”)同时出现,这样的例句只需构建情感关系对捕获模型便可以很好地进行情感分析。相反,“Case#2”中的“It didn't work if the battery was low”,仅包含了情感方面(“battery”),并没有显式地给出情感观点词,这就需要研究者通过建立深层语义理解模型进行情感极性的预测。在ESA的早期研究中,研究者们通过构建各种神经网络模型显式地捕获情感词和情感极性对并进行相关分析。这些方法主要分为:1) 基于序列化模型。主要结合注意力机制或语言模型BERT与序列化模型(如CNN、LSTM等)来挖掘情感对,如ATAE-LSTM[1]、DT-LSTM[2]、RAM[3]及ABSA-BERT[4],这些方法存在处理情感词和情感观点距离较远的句子时情感片面词和情感极性对错位的问题,不能准确地捕获二者的相关信息。2) 基于树结构模型。句法信息对情感对的捕获有着十分重要的影响,故不少研究者通过建模短语树或依存树来捕获情感极性对,如PhraseRNN[5]、SynATT[6]、CDT[7]等。与序列化模型相比,这类句法结构模型较好地提升了ESA分析的准确率,相关实验证明了句法知识在情感分析中的重要性,但其准确率受到句法树解决工具准确率的影响。随着图神经网络的不断发展,“树”可以作为一种特殊的图,同时,依存关系能较好地挖掘出句子中修饰词与被修饰词之间的关联,且与二者的距离无关。研究者们纷纷构建了基于句法树尤其是关系图的图神经网络模型,如ASGCN[8]、SD-GAT[9]、RGAT[10]、DGEDT[11]、DualGCN[12]。相比句法树模型,这些图神经网络模型对ESA分析的准确率有了较大的提升,主要原因是图结构比树结构能更好地挖掘出词的全局信息。这些图神经网络模型的准确率也受句法解决工具包准确率的影响。针对此问题,有些研究者提出利用强化学习和注意力机制如dotGCN[13]构建片面词的诱导树进行情感预测,其准确率得到了较大幅度的提升。然而,这些ESA的模型并不适合ISA,需要构建深层语义理解模型进行ISA研究。

近年来,随着大语言模型(large language models,LLM)迅速的发展,语言模型再次成为各种自然语言处理任务的焦点,这些任务主要通过预测词在句子中出现的概率进行语义分析,并在许多下游任务中表现了出色的性能。研究者们纷纷尝试利用LLM进行ISA研究,如Fei等[14]使用T5大模型,通过3次(情感方面-观点-极性)的思维链提示提问,巧妙地将情感分析问题拆分成思维链提示问题,但其运行效率不高,难以在小规模模型上取得良好的效果。尽管这些方法展示了LLMs强大的上下文泛化能力,但即使是最大的语言模型,在面对多个推理步骤的复杂任务时也难以进行处理和分析[15],例如基于线索的思维链(chain of thought,CoT)推理方法依赖于包含数千亿个参数的模型[16-17],计算量大,推理成本高,难以大规模部署。更重要的是,大型语言模型中的信息不足以满足所有下游任务。而在小模型中实现复杂推理可使其在大规模的部署和应用上更具可行性。
因此,本研究提出了一种基于教师-学生大模型的隐式情感推理框架(reasoning implicit sentiment with teacher-student prompting,RI-TSP)。首先通过使用大语言模型结合三层思维链的方法生成推理样本,其中三层思维链分别用来提问句子的情感方面、观点和极性;其次,应用小规格的学生模型微调训练生成的推理样本,这样有助于小模型更好地理解样本的语义信息,同时也提高了训练的效率;最后,利用小规模样本的语义信息推理情感极性。
1 相关工作
1.1 思维链
思维链是一种通过逐步思考解决问题的方式,在解决复杂推理任务上展现出良好的性能,近年来受到自然语言处理领域的广泛关注[16]。思维链也被广泛应用于下游任务如数学推理、常识推理、逻辑推断等,并取得了良好的效果,其主要思想包含思维链构造方法、结构变体以及增强方法等。从思维链构造的角度来看,现有的工作可以分为3种方式:手动思维链构造、自动思维链构造以及半自动思维链构造。手动思维链构造中,示例中的推理链由人工标注,少样本思维链率先通过手动构造演示自然语言形式的基本原理[17];为进一步提升推理的准确性,PAL[18]、PoT[19]以及NLEP[20]方法可处理并减少推理路径和答案之间的不一致性,利用编程语言作为注释的基础,将问题求解转换为可执行的程序;Mathprompter方法使用零样本思维链提示生成多个答案,可以相互验证,提高结果的可靠性[21]。手动构建推理链条具有较高的数据质量,缺点在于需要较大的人力成本开销,并且会遇到示例选择难以优化、跨任务迁移困难等问题。自动思维链示例中的推理链无须人工标注,零样本思维链通过特定的提示文本(“Let's think step by step”)激发模型,使模型在没有示例的情况下生成推理链[17];自动思维链(automatic chain of thought,Auto-CoT)方法利用前者零样本生成的推理链结合示例选择策略,通过少样本学习的方式生成推理链[22];COSP方法引入结果熵来论证示例选择的正确性[23],例如Wang等[24]提出Reprompt,通过Gibbs迭代抽样挖掘出有效的思维链提示。同时,推理链中的一些错误来自缺步错误,Wang等[25]通过计划和解决(plan-and-solve,PS)策略将整个任务划分为较小的子任务进行执行,从而将零样本思维链扩展为计划和解决(plan-and-solve,PS)提示。自动思维链构造减少了人工成本,由于无须针对任务设定示例,在不同任务间可以方便迁移,但由于缺少高质量数据,其性能通常较差,时常会出现事实错误、逻辑错误等问题。半自动思维链构造结合了前二者,在推理性能和人力成本间达到了平衡。Shao等[26]提出了合成提示(synthetic prompts),即利用少量人工注释的示例来提示模型生成更多的示例,并选择有效的示例引出更好的推理,从而缓解Auto-CoT方法中缺乏人为对齐的问题。
从思维链的结构变体来说,起初的思维链是链式结构,以自然语言词序描述中间推理过程。这种链式结构忽略了语言表述中词之间的隐式句法信息,一定程度上限制了其在复杂任务上的能力。为了更好地挖掘语言内在句法结构信息,不少研究者对思维链的结构进行了探索。现有工作主要可分为链结构变体、树结构变体以及图结构变体。其中,PAL[18]和PoT[19]方法基于链式结构通过引入编程语言描述实现推理过程。chain-of-symbol方法在规划过程中利用浓缩符号链表示复杂环境,从而降低了仿真环境的复杂性[27]。实验结果表明这种链式的思维链在一定程度上限制了广度,因此一些学者结合树结构对推理路径进行了尝试,如引入了回溯、自我评估、剪枝等步骤的思维树(tree of thought,ToT)方法[28-29],在复杂任务上表现优异。在中间步骤中额外引入了不确定性评估的tree of uncertain thought方法[30],一定程度上缓解了由不确定性带来的推理级联错误。图结构比树结构引入了更复杂的拓扑结构,思维图(graph of thought,GoT)方法[31]在推理中通过环结构引入了自我修复,并根据图拓扑结构引入了信息聚合。与树结构遇到的问题相同,图结构针对任务选择有较大的局限性,必须针对任务具体设计指令内容。
在思维链的应用上,与本研究最相关的是思维链蒸馏[32]。已有研究证明了思维链是大模型的一种涌现能力,而这种能力在一些规模较小的模型上并不是很显著,限制了小模型在推理时的表现[15]。故需要依靠具有较强思维链能力的大模型输出推理链,再蒸馏传送给小模型,从而让小模型也具备一定的推理能力。如STaR模型使用自循环引导策略来提高语言模型推理能力[33],同时符号化思维链蒸馏(symbolic chain of thought distillation,SCoTD)模型研究证明了针对每个样本采样多种推理路径能提高小模型的推理性能[34],而Scott模型通过对比解码和反事实推理的方式进一步提升思维链质量,缓解小模型从学习到推理过程走捷径的问题[35]。现有的思维链相关工作用于推理问题较为广泛,少有研究将其应用于隐式情感分析中,针对上述这些问题,本研究结合大模型、思维链、知识蒸馏等对评论句子的隐含情感极性进行分析和推理。
1.2 情感分析
现有的情感分析针对句子中缺乏情感词的问题,提出细粒度情感分析的相关研究,该研究也成为自然语言处理的重要研究方向之一。已有工作可分为基于图神经网络模型、提示学习以及大语言模型的知识增强3部分。
针对图神经网络模型,在进行情感分析时,基于知识的图神经网络能有效地从不同角度分析句子/文本的具体情感,这些知识主要包括句法知识、语义知识、上下文知识和专业领域知识等。T-GCN模型在GCN基础上对边缘节点采用了注意力机制并集成了多种依存关系,能更好地获取上下文信息[36],而Hier-GCN模型构建2个子层的GCN,其中下层用于学习方面词之间的内部交互,上层用于学习方面词与情感之间的相互作用,两者都将重心聚焦于上下文的关系和信息获取上[37]。R-GAT模型基于一种基于关系注意力的GCN,编码面向方面词的依存树,从而进行情感分析[10];HL-GCN模型从基本依存树出发,构建全局依存树和局部依存树,优化句法知识的表示[38];PD-RGAT模型通过在短语依存图上引入节点和边的多头注意力机制,更好地表达了短语和依存关系的信息[39],这三者均在句法表示上取得了巨大突破。有学者使用图神经网络融合跨语言知识,更好地分析了中文语言数据的情感[40],也有融合情绪知识对案件微博评论进行情绪分类的研究[41]。上述模型集中运用一个或两个方面的知识内容,往往会忽略其他方面的知识,如领域知识或常识知识,缺乏全面分析的能力。
随着大规模语言模型和提示学习的迅速发展,图神经网络模型在学习和挖掘知识方面的问题得到一定程度的改善。其中提示学习需要构建提示的模板,才能使用语言模型进行学习训练。构建模板的方式有手动和自动2类,构建手动的提示模板可以处理各种各样的任务包括问答、翻译和常识推理任务等[42],也有在文本分类和条件文本生成任务的少样本学习设置中使用预定义的模板[43-44],虽然手动构建模板的策略是直观的,并能够准确地解决各种任务,但这种方法也存在一些问题:1) 创建和验证这些提示模板需要时间和经验,特别是一些复杂的任务,如语义解析[45-46]等;2) 即使是经验丰富的模板设计者也可能无法手动设计出最佳提示模板[47]。Autoprompt方法提出一种基于梯度的模板搜索方案,实现了机器自动构建提示模板,解决了手动设计的困难[48]。基于思维链的提示能充分利用大语言模型的知识,Auto-CoT方法通过采样丰富的问题并生成相应的推理链来构建提示模板[22],而Mathprompt方法使用零样本思维链生成多个代数表达式或Python函数,以不同的方式解决同一个数学问题,从而提高输出结果的置信度[21]。Auto-CoT和Mathprompt方法融合思维链的方式进行提示学习,解决了不同种类的推理问题,在提示学习领域取得了巨大的进展。
在大语言模型的知识增强方面,Ho等[49]使用零样本思维链通过大语言模型得到推理样本,将较小规模的模型在各类推理下游任务上进行训练并取得了良好的效果;而Magister等[50]使用类似的方法进行了少样本的测试,验证了该方法在不同规模数据上的可行性。Fei等[14]首次将思维链推理用于隐式情感分析上,通过3次(情感方面-观点-极性)的思维链提示提问,一步步诱导大模型对句子情感进行更深层次的分析,取得了突破性的成果。前两者并未将大模型-小模型的结构推广到除了推理任务以外的任务,如情感分析;后者使用的大模型耗费了较大的时间和运算成本,在学习效率上有所不足。本研究融合了文[14]和文[49]的方法,不仅将大模型-小模型的知识蒸馏结构运用于情感分析任务上,而且对于思维链提示作情感分析的步骤做了优化。
2 基于思维链提示的教师-学生模型
本研究提出的RI-TSP模型主要分为教师-学生模型和情感极性提示推理2部分。其中,教师-学生模型运用思维链蒸馏,使用大模型(教师模型)生成推理样本提供给小模型(学生模型)进行微调训练;情感极性提示的推理部分使用思维链3次提示大模型输出推理样本,并将其最终组合成一个完整的包含情感极性提示过程的推理样本。
2.1 教师-学生模型
本研究提出一种基于大模型-小模型迁移学习的教师-学生模型(teacher-student prompting, TSP),其结合思维链提示微调分析句子的隐含情感。主要思想为大模型(教师模型)通过结合零样本思维链生成推理样本,使用生成的推理样本对小模型(学生模型)进行提示微调。这种方法保留了基于提示的思维链方法的推理性,同时一定程度上减少了推理的成本和对于大模型训练的依赖。为了使教师模型的推理成本最小,选择在教师模型上使用不需要任何推理示例或长推理上下文的零样本提示方法生成推理样本。
作为学生模型的T5模型是一个经典的encoder-decoder模型,其将所有的NLP问题转换为文本-文本(text-to-text)格式。T5模型的强泛用性能在不同的NLP任务上使用相同的模型、损失函数和超参数,这些任务包括机器翻译、文档摘要、问答和分类任务等。不同于BERT或GPT模型仅使用Transformer结构的一部分,T5的基准模型直接采用标准的Transformer encoder-decoder结构,以便在生成任务和分类任务中取得不错的效果。由于T5模型将任务转化为文本-文本的形式,适用于思维链的多次提示微调,因此采用T5模型作为学生模型。教师模型采用Flan-T5模型,与T5模型相比,Flan-T5模型在1 000多个额外任务上进行了微调,通过观察其在多任务语言理解(massive multitask language understanding,MMLU)基准测试中的表现,与更大的模型相比具有很强的竞争力和良好的效果。使用Flan-T5模型作为教师模型的推理成本可以得到降低,并且Flan-T5模型在指令微调方面比T5模型有较大提升。
具体来说,本研究提出的教师-学生模型训练主要步骤可以分为以下3步:推理样本生成、样本筛选以及提示微调,如图 2所示。

2.1.1 推理样本生成
首先,利用教师模型为给定的文本句子生成CoT推理解释样本。假设存在第i句文本句子si及其情感极性pi组成的标准样本Si,其中i表示原始样本的序号。使用零样本以及多次的CoT提示教师模型生成推理情感的每一步解释,以分析文本句子si的情感极性。生成过程参考文[14],每一步推理过程都会询问模型的详细理由。而由于学生模型的规模较小,对于长文本的理解能力有限,因此在本文中省略了详细理由的生成,推理的样本只包含情感目标、方面及观点的信息。生成的最终文本形式为“Given the sentence < si>, ..., What is the polarity towards above sentences? The polarity is < pi> ”。
2.1.2 样本筛选
对生成的推理样本进行筛选。筛选过程参考文[33],将教师模型预测的情感极性pi与实际的情感极性p进行比较,对pi ≠ p的样本数据进行去除,但这种筛选会导致部分样本的损失,在小样本情况下可能导致精度下降。因此本研究中pi ≠ p时仍保留原始样本,只将样本构成基本的Prompt-tuning形式:“Given the sentence < si>, What is the polarity towards above sentences? The polarity is < pi> ”;当pi = p时,将si和pi封装为一个推理样本提示对(si, pi),其中si包含情感极性的提问。
2.1.3 提示微调
在组成的推理样本上使用经典的Prompt-tuning方式[51]通过提示模板构建、提示推理、情感观点库构建的方法微调一个预训练的学生模型。
2.2 情感极性提示
推理样本生成(详见2.1.1节)采用的思维链提示,参考文[14],可进一步细分如下:
1) 情感方面的提示。使用以下提示模板提示教师模型,得到句子中的方面a:
C1 [Given Sentence S], which specific aspect of t is possibly mentioned?
其中:C1为第一跳提示的上下文,t为情感目标(target)。这一步可以表示为A =argmax(a | S, t),A为显式提及方面a的输出文本。
2) 情感观点的提示。基于第一步的S、t、a和A,采用以下提示模板提示教师模型:
C2 [C1, A]. Based on the common sense, what is the implicit opinion towards the mentioned aspect of t, and why?
其中:C2为第二跳提示的上下文,由C1和A简单先后拼接而成。这一步可以表示为O =argmax(o | S, t, a),O为包含观点(opinion)信息的回答文本。
3) 情感极性的提示。使用完整的情感框架(S、t、a和o)作为上下文,向教师模型提问情感极性。
C3 [C2, O].Based on the opinion, what is the sentiment polarity towards t?
其中C3是第三跳提示的上下文,C3与第二步相同,由C2和O简单先后拼接而成。这一步最终可得到2.1.1节中的文本句子si。
3 实验及分析
3.1 数据集
表 1 实验数据集样本数量 |
| 数据集 | 训练集 | 验证集 | 测试集 |
| Laptops | 2 163 | 150 | 638 |
| Restaurants | 3 452 | 150 | 1 120 |
3.2 实验配置
模型配置。本实验使用Hugging Face网站在Github上开源的自然语言处理库中的模型,其中教师模型选用Flan-T5-xl(3 B)和Flan-T5-xxl(11 B),学生模型选用T5-base(250 M)和T5-large(780 M),M和B为表示模型参数量的数量级,分别为106和109。不使用同一种模型可以有效避免知识的重复使用。
超参数设置。RI-TSP模型在Laptops和Restaurants数据集上的实验参数如下:轮次(epoch)设置为10,句子最大长度为300,暂退(dropout)率为0.5,学习率为1×104。此外,实验结果采用准确率(accuracy)和宏F1值(macro F1-score)这2个评价指标对本研究提出的RI-TSP模型的性能进行评估。
软硬件配置。本研究所有实验均采用GPU NVIDIA(A40)显卡进行训练和测试,使用PyTorch 2.1框架在Jupyter Notebook环境下运行,详细代码实现见 https://github.com/zufeyuxj/RI-TSP。
3.3 基准模型
为了更加公平地验证本研究提出的RI-TSP模型的性能,主要选择了基于语言模型增强的模型(RGAT、BERT+SPC、BERT+ADA、BERT+RGAT)和基于提示学习的模型(T5+Prompt)作为基准模型,与本研究建立的RI-TSP模型进行比较。接下来详细介绍基准模型的基本原理。
RGAT[10](relational graph attention network)2020版构建了依存关系图的神经网络来获取情感极性对,并对情感片面词的情感极性进行预测。
BERT+SPC[53](BERT text pair classification model)2018版利用预训练语言模型BERT来捕获评论句子的隐含语义信息并对其情感极性进行分类。
BERT+ADA[54](BERT with domain adaptation)2019版通过使用跨领域计算方法,采用跨领域适应的BERT语言模型对下游任务进行训练。
BERT+RGAT[10](BERT with relational graph attention network) 2020版提出一个依存关系图注意网络模型来编码新的依赖树,以解决ABSA模型的长依赖问题。
BERT+CEPT[52](BERT with supervised contrastive pre-training) 2021版是一种基于监督对比预训练的方面情感分析,挖掘句子中的隐式情感信息。
T5+Prompt[14](Prompt-tuning using text-to-text transfer transformer model)2023版使用T5模型进行指令微调训练,使用提示学习来捕捉句子的情感信息。
3.4 实验结果分析
实验结果如表 2所示,其中,Acc-SA为准确率,F1-ISA为ISA的宏F1值,F1-ESA为ESA的宏F1值。由表可知,在教师模型参数量为3 B,学生模型参数量为250 M的情况下,各数据集均出现隐式情感分析能力较弱的情况,这可能是教师模型的参数量不够多,因此不具备很强的分析能力,同时由于使用零样本提示生成推理样本,因此给出的具有思维链提示知识的数据对于隐式情感的挖掘不够,丢失部分重要信息,具有局限性。各数据集的准确率和整体情感分析的F1值偏低,可能是由于学生模型参数量较少,自身学习能力不足,获取到的推理样本知识有限,难以做出精准的预测和判断。针对上述问题,进一步将教师模型参数量从3 B增大为11 B,学生模型参数量从250 M增大为780 M,这种同步的扩大可保证教师模型和学生模型参数量的比例基本不变,有利于模型结构的稳定。
表 2 RI-TSP与基准模型在测试集上的实验结果 |
| 模型 | 测试集 | ||||||
| Laptop | Restaurant | ||||||
| Acc-SA /% | F1-SA | F1-ISA | Acc-SA /% | F1-SA | F1-ISA | ||
| RI-TSP(3 B-250 M) | 82.60 | 78.09 | 71.12 | 84.46 | 78.04 | 68.25 | |
| RI-TSP(11 B-780 M) | 84.33 | 81.41 | 78.02 | 87.95 | 81.72 | 72.53 | |
| T5+Prompt(250 M) (2023版) | 82.45 | 79.03 | 74.70 | 86.88 | 80.26 | 69.62 | |
| T5+Prompt(780 M) (2023版) | 82.76 | 79.66 | 75.72 | 87.14 | 81.41 | 71.07 | |
| BERT+Prompt(110 M)(2023版) | — | 78.58 | 75.24 | — | 81.34 | 70.12 | |
| BERT+SPC (2018版) | 78.22 | 73.45 | 69.54 | 83.57 | 77.16 | 65.54 | |
| BERT+ADA (2019版) | 78.96 | 74.18 | 70.11 | 87.14 | 80.05 | 65.92 | |
| BERT+RGAT (2020版) | 78.21 | 74.07 | 72.99 | 86.60 | 81.35 | 67.77 | |
| BERT+CEPT (2021版) | 81.66 | 78.38 | 75.86 | 87.50 | 82.07 | 67.79 | |
注:Acc-SA为准确率,F1-ISA为隐式情感分析(implicit sentiment analysis,ISA)的F1值,F1-SA为包含隐式情感分析和显式情感分析的F1值;3B-250 M表示教师模型和学生模型的参数量为3B和250M,11 B-780 M依此类推。 |
调整后的实验结果如表 2所示,其中3 B-250 M表示教师模型和学生模型的参数量为3B和250M,11 B-780 M依此类推。由表可知,在Laptops测试集上,与基准模型中实验效果最好的T5+Prompt(780 M)模型相比,本研究建立的RI-TSP(11 B-780 M)模型的准确率提升了2.67%,整体F1值以及F1-ISA值分别提高了3.03%和2.16%;而在Restaurants测试集上,与T5+Prompt(780 M)模型相比,RI-TSP(11 B-780 M)模型的准确率提升了0.45%,整体F1值以及F1-ISA值分别提高了0.31%和4.74 %。对于隐式情感的分析,本研究建立的RI-TSP模型具有良好的分析能力;对于显式情感的分析,由于句子中会出现明显的情感词(如图 1“Case#1”中的“amazing”),而教师模型给出的推理样本并不会直接提示,所以会出现一些重复和无用的推理知识,分析结果存在一定的不确定性。
由表还可知,与基于Prompt的模型相比,在Laptops数据集上RI-TSP(11 B-780 M)模型的准确率平均提高了1.72%,整体F1值以及F1-ISA值分别平均提高了2.32%和2.80%;而在Restaurants数据集上,RI-TSP(11 B-780 M)模型的准确率平均提高了0.94%,整体F1值以及F1-ISA值分别平均提高了0.72%和2.26 %。对于Restaurants数据集,RI-TSP模型在显式情感分析上有较高的提升。在加入教师模型的推理知识后,学生模型的训练变得更加准确和高效,且进一步增强了指令微调的效果。
此外还可以发现,提示学习的效果比基准模型中的RGAT、BERT+SPC、BERT+ADA、BERT+RGAT有一定程度的提升,这是因为提示学习能充分利用语言模型在学习大规模语料后得到的知识和模式,并具备文本生成能力,所以可在训练数据很少的情况下精准地完成各类下游任务。与提示学习模型(如T5+Prompt)相比,本研究提出的RI-TSP模型融入思维链推理知识,帮助模型更好地挖掘出句子隐含的情感信息,因此,对F1-ISA值的提升效果较为显著。
3.5 案例分析
本研究提出的RI-TSP模型通过融入思维链推理知识,能更好地挖掘句子中隐含的情感信息。为了详细分析思维链推理知识的作用,通过3个实验案例进行具体分析,如图 3所示。由图可知:1) 使用RI-TSP模型时,在推理样本生成的过程中所产生的情感观点(opinion),在推理信息中均含有一定的情感词,如案例1中的负向情感词“not satisfied”和案例3中的正向情感词“good”。2) 对于案例2,虽然整个句子的情感极性为负向,但是其文本中却出现了“perfectly”和“satisfied”这类正向情感词,对于一般的提示学习来说,难以判断其极性。但经过思维链推理后,能够得出“battery life is not enough”的负向观点,进而推理出该句子为负向情感句。因此,通过思维链知识的融入能够更好地挖掘出句子中的隐含情感词,且能推理出一些容易混淆情感极性的隐式情感文本的观点。

3.6 训练迭代次数对比
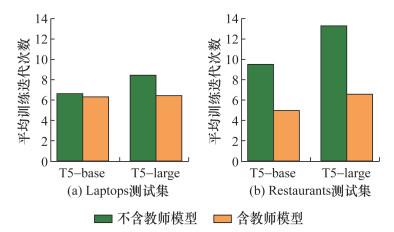
针对训练迭代次数,将基准模型中的T5-Prompt模型和本研究提出的RI-TSP模型进行对比,随机进行10次训练,并记录每次在Laptop和Restaurants测试集上达到最好效果时的迭代次数,以迭代次数的平均值作为评价指标,结果如图 4所示。由图可知,在Laptops测试集上,使用教师模型后对学生模型进行训练,T5-base和T5-large的平均迭代次数分别下降了3.0%和25.0%;而在Restaurants测试集上,分别下降了47.3%和50.0%。训练时使用的样本具有经教师模型提示后的推理知识。在学生模型训练过程中效率得到提升,与直接进行指令微调相比,减少了一定的时间消耗。
4 结论
本研究提出了一种基于思维链提示的教师-学生模型(reasoning implicit sentiment with teacher-student prompting, RI-TSP),在教师大规模语言模型的使用上,构建了一种情感极性提示方法来生成推理样本,利用思维链以及提示学习方面的知识,有效地生成了具有思维链推理过程的样本。此外,还通过知识蒸馏将具有推理知识的样本在小规模的学生模型上指令微调,进而实现了情感极性的推理。在公开数据集Laptops和Restaurants上的实验结果显示,RI-TSP模型具有较高的准确率并降低了模型的运行成本。
下一阶段,可将更多的大模型如多模态大语言模型(multimodal large language models,MLLM)作为一种融合多种类知识的工具,同时结合思维树(tree-of-thoughts, ToT)或思维图(graph-of-thoughts, GoT)构建深度全局决策推理范式,并将其在其他自然语言处理任务中进行验证和优化。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}