

中国特高拱坝建设逐步向高寒和高海拔地区转移,这给建造和运营带来了新的挑战[1-5]。在建设阶段,由于施工过程复杂且多变,常会遇到各种安全隐患,如设备伤人、高空坠落等,极易引发严重工程事故[6-7]。特高拱坝施工隐患的及时排查对减少工程事故、保障工程安全意义重大,制定有效的施工隐患排查策略可以大大降低安全隐患的发生概率[8-9]。隐患往往具有隐蔽性和多样性,初期阶段难以通过常规检查手段察觉。因此,系统化的排查线索在隐患的及时识别中至关重要,可以帮助管理人员准确地发现潜在的工程风险,并作出及时的判断和应对。现场碎片化的历史隐患记录文本为排查线索的发掘提供了条件,这些历史安全隐患信息是了解隐患分布情况的窗口[10],可以成为制定隐患排查策略的有效补充。然而,传统基于人力的隐患分析方法往往面临效率低、信息整合困难等问题[11-12],难以在海量数据中获得全面、准确的排查线索。当前,自然语言处理技术在文本分析中应用广泛[13],为大坝安全的智能化管理提供了新方法[14-16],合理运用这些技术对于了解隐患的分布情况、识别潜在风险和获取系统化的排查线索至关重要。
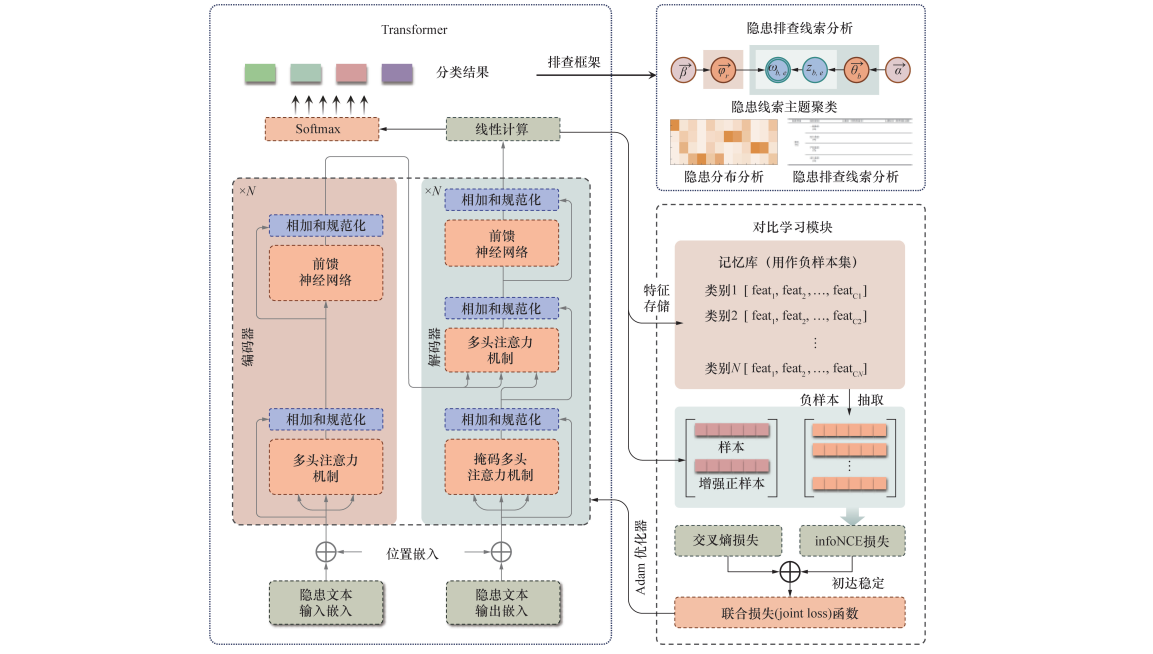
为构建系统化的特高拱坝施工隐患智能排查方法,本文提出了基于文本分类与主题聚类的隐患排查线索挖掘方法。首先,开发了一种基于增强半监督对比学习的隐患文本多分类模型,识别碎片化隐患记录文本的隐患类别与等级,并用于隐患排查框架构建。然后,引入记忆库(memory bank)解耦训练批次提高了半监督对比学习效果。最后,基于主题模型实现不同条件下隐患排查线索分析,构建不同隐患特征下的隐患排查表。本文为特高拱坝施工安全隐患的系统化排查提供了新方法。
1 研究现状与主要问题
1.1 特高拱坝施工隐患分类
隐患排查框架的制定是系统化隐患排查的基础,即通过对各种隐患的分类,为排查工作提供结构化的指导。文本分类任务在工程中可将大量的混杂文本按照特定类别划分,为工程现场碎片化信息的进一步应用提供保障[17-18]。Tian等[19]提出一种基于图结构的混合深度学习方法,用于大型工程施工安全隐患类别分类; 王仁超等[20]提出融合预训练模型的卷积神经网络(convolutional neural network,CNN),用于水电工程施工安全隐患类别智能分类; Moon等[21]使用基于Transformer的双向编码器表示技术(bidirectional encoder representations from transformers,BERT)对合同风险信息进行分类,有助于改善建筑项目的施工规范审查和风险管理过程; Wang等[22]提出一种基于可解释机器学习的施工缺陷智能分类识别方法,用于工程施工缺陷的实时分析; Wilkho等[23]提出基于集成学习的BERT方法用于山洪事故的多致因识别。近年来,Transformer在文本分类中表现出良好的效果,模型采用具有编码器-解码器结构的自注意力层将输入数据转换为向量表示[24-25],可以探究文本序列内部语义结构,建立文本序列内部单词间依赖关系并提高对文本的特征表示能力。廖才波等[26]提出一种基于Transformer的缺陷文本识别方法用于风险评估及辅助检修决策,为文本分类在工程中的应用提供了借鉴。然而,特高拱坝安全隐患文本通常具有多重类别属性如隐患类别、隐患等级等,当前研究主要存在以下问题:1) 传统多标签分类方法难以有效处理多属性间复杂的互斥关系,经特征工程表示在向量空间中距离相近的文本可能同时具有相悖的多属性标签。2) 现有单标签分类方法常通过堆叠特征提取模块以适应不同特异性的分类情况,在处理复杂多类的隐患分类任务时存在局限性。针对上述问题,将多标签任务分离为多个单标签任务,独立训练每个属性类别可以减少互斥关系带来的模型性能影响[27]。然而,单标签文本分类方法很少利用类间关系来增强模型对整个数据集的表征能力,这导致潜在语义信息未得到充分挖掘,从而影响了模型在处理复杂分类任务时的性能。
1.2 对比学习
类间关系的利用对提升模型性能和泛化能力具有重要作用。特别是在分类任务中,标签类别关系的有效利用可以对模型分类效果提升起到重要作用。对比学习思想为类间关系的利用提供了可能,Li等[28]采用对比学习思想动态调整短文本聚类任务,解决聚类空间稀疏的问题; Wang等[29]融合对比学习与对抗训练进行文本分类,通过扩大类间关系提高了模型泛化性能。作为自监督学习的典范,对比学习方法的目的在于学习正样本对的相似表示和正负样本间的差异表示[30],通过扩大向量空间中不同类别样本之间的距离,提高模型对类别差异的敏感度[31],有望显著改善分类模型在隐患类别和等级分类中的效果。此外,部分学者采用融合自监督学习和有监督学习的方法扩大分类模型效果。Liu等[32]提出一种融合数据增强和半监督对比学习的命名实体识别方法; Xie等[33]提出一种基于监督对比学习的媒体文本分类方法。这些方法通过充分结合标签信息与类间关系,进一步提升了模型对文本的分类效果,为隐患识别提供了更为精准的支持。
常见的对比学习通常为端到端的方法,即将自身样本视为正样本,而将同一训练批次中的其他样本作为负样本。然而这种方法存在几点显著问题:首先,对比学习通常将向量空间中的余弦相似度作为样本距离,以自身为正样本缺乏意义; 其次,同类别的样本有时会被误分类为负样本,从而影响模型的训练效果; 最后,在对比学习中,负样本的数量对于效果提升至关重要,但端到端的对比学习中负样本的数量受批次大小的限制,不利于对比学习效果的提升。为了克服这些问题,记忆库是一种有益的尝试,Bulat等[34]构建了增强样本的记忆库用于无监督的图像特征提取; Huang等[35]开发了一个基于对比损失的类感知的记忆库用于人体动作识别。然而,这些方法常用于图像识别任务中,并且在负样本筛选过程中缺乏对标签信息的考虑。为此,需要探索如何有效地利用现有的标签信息优化负样本的选择和生成过程,并将其与记忆库结合,以改进传统端到端的负样本采样方法,从而解决样本混淆和不足的问题。
1.3 特高拱坝隐患排查线索挖掘
文本分类任务为隐患排查框架的定制提供了条件,但各类别隐患下存在不同的隐患特征,如“高处坠落”存在“工人未佩戴安全带” “临边未设置防护装置”等原因。如何将分类框架与碎片化文本内容深度结合,进而获得完整的隐患排查线索,仍是亟待解决的问题。主题模型提供了解决办法,隐含Dirichlet分布(latent Dirichlet allocation,LDA)主题模型由Blei等[36]提出,能够从文本数据中自动发掘潜在的主题语义结构[37]。李明超等[38]基于改进LDA开展水电工程进度信息智能挖掘,实现了12个进度主题的主副关键工序提取。如何在海量隐患记录文本中提取出进一步的排查主题和线索细节,并将其与排查框架结合形成一个完整且系统的排查表,尚待研究。
2 研究方法
2.1 研究框架
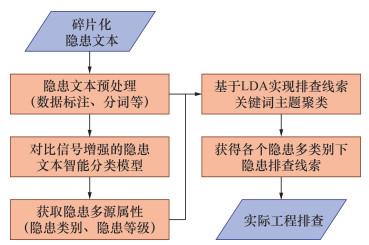
特高拱坝施工安全隐患排查是确保施工安全和工程质量的重要环节,为此提出特高拱坝施工安全隐患智能排查方法,如图 1所示。该方法构建了基于Transformer和改进对比学习模块的隐患文本多分类模型,用于碎片化隐患记录文本的隐患类别、等级识别,建立系统化隐患排查框架; 进一步,依据识别结果进行隐患分布分析,并通过LDA主题模型实现各条件下隐患排查线索分析,建立不同隐患类别和等级下的隐患排查表,辅助管理人员实现隐患的智能排查。

2.2 Transformer模型
2.2.1 多头注意力机制
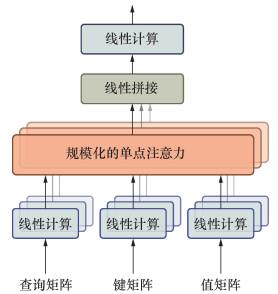
Transformer使用多头注意力(multi-head attention,MHA)机制来刻画词语间的依赖关系[39]。MHA通过并行计算多个自注意力头,能够在不同的子空间中捕捉多种关系,增强特征表达能力[40](见图 2)。自注意力(self-attention,SA)机制主要用于探究文本序列内部语义结构,建立文本序列内部单词间依赖关系[41],动态地为每个单词分配不同的权重,更精确地捕捉到上下文信息。SA把1个词的意义特征通过3个全连接神经网络映射成3个维度相同的向量,即查询(query)、键(key)和值(value)矩阵。接着利用缩放点积模型,计算嵌入矩阵Q、K之间的相似度,得到注意力得分值,并利用Softmax函数归一化文本语义特征的注意力得分值,得到注意力概率分布,序列中第i个词语的注意力系数为
其中:Q、K为文本特征线性变换获得的嵌入矩阵,Ki为K中第i个词语的键向量,d为Ki的维度。
计算输入序列中每个语义特征的注意力系数,获得注意力权重矩阵,将注意力权重矩阵与值矩阵V求积,生成新的文本序列语义特征,实现文本语义特征强化,第i个单词在SA机制处理后新生成的深度语义特征为
其中Vi为V中第i个词语的值向量,d也为隐患文本截取长度。
与单头自注意力机制不同,MHA将K、Q、V进行多次线性投射并计算各自的注意力输出,将这些输出拼接再进行线性投射,生成融合了多种注意力模式的新向量,从而增强模型对复杂语义关系的捕捉能力。序列中第i个词语的新生成的语义特征为:
其中:m为多头注意力机制的头数,concat(·)表示将多头注意力的输出线性拼接,W、WQ、WK、WV为线性投射矩阵。
2.2.2 编码器和解码器
编码器(encoder)和解码器(decoder)是Transformer模型的重要组成部分[42]。其中,编码器由单个或多个相同的编码器层堆叠而成,每层包含2个子层,即MHA和前馈神经网络(feed-forward network,FFN)。FFN层对输入的特征向量进行非线性变换,将经过MHA后的特征向量映射成同等维度的向量。为了维持训练的稳定,在2个子层后面分别加入了相加和规范化(add & norm)。解码器由单层或多层堆叠而成,每个解码器层由3个子层构成,即掩码MHA、MHA和FFN。解码器的输入信息为样本序列以及对应的输出值(类别信息),掩码MHA确保解码器在生成每个位置的词语时仅依赖于当前及之前的词语。MHA将编码器的输出作为键和值,进一步整合编码器提供的上下文信息。最后,特征经FFN层后进入分类器,实现安全隐患文本类别识别。
2.3 记忆库改进的半监督对比学习模块
2.3.1 半监督对比学习损失
对比学习使模型更加关注样本类别之间的差异,从而促进分类性能的提升[43]。通过构造相似与不相似的实例,可以获得一种表示学习模型,使得相似实例在投影空间中的距离较近,而不相似实例的较远。与此同时,交叉熵损失通过利用数据真实标签,确保模型在分类任务上的准确性。两者结合形成的联合损失函数既保证了数据集对于模型训练的约束,又通过自监督信号改进了数据特征表示,保证了模型良好的拟合能力和泛化性能。
对比学习的本质是通过模型运行结果实现对模型参数的优化,因此本文构建了含有对比学习损失的模块实现模型分类效果提升。对比学习模块中包含了自监督训练的损失函数即对比学习损失,以及有监督训练的损失函数。在自监督训练部分,采用信息噪声对比估计(information noise contrastive estimation,infoNCE)损失作为对比学习损失,以特征自身为正样本,自身外的相反标签为负样本,为特征q构建正样本和负样本。infoNCE损失计算如下:
其中:k+为q的正样本,kj为负样本,n为负样本个数,τ为温度系数。q和正样本越相似,与负样本越偏离,损失值越小。
在有监督训练部分,采用交叉熵(cross entropy)损失作为损失函数:
其中:$L_{\mathrm{CE}}\left(\hat{p}_{x}\right)$为第x句有监督训练部分的交叉熵损失,L为标签个数,p(cxy)为第x句文本中第y个标签的实际值,$\hat{p}\left(c_{x y}\right)$为预测值。
为了充分了解数据的特征,提高编码器的质量,耦合infoNCE损失和交叉熵损失构建对比学习模块。采用平均值建立联合损失来计算损失并训练编码器:
2.3.2 记忆库
在对比学习中,负样本的数量对模型性能有着决定性的影响。在传统端到端的对比学习方法中,负样本来源于同批次的训练数据,通常需要扩大批容量来增加负样本的数量,导致计算消耗显著增加。记忆库是一种有效的解决方案,以队列结构来存储前批次中的样本特征。当队列达到容量上限时,最初始样本特征出队,最新样本的特征入队。对比学习所需的负样本将从该队列中抽样产生,通过解耦批次界限避免端到端对比学习方法的算力问题。
记忆库按类别存储样本特征,在增大对比信号的同时实现了负样本的动态更新。第l个类别在第t批次的记忆库为
其中:Ml(t-1)表示第l个类别在第(t-1)批次的记忆库,zlt表示第t批次中第l个类别的文本特征,enqueue(Ml(t-1), zlt)表示将当前批次中的样本特征zlt添加到上一批次产生的记忆库Ml(t-1)中。当记忆库Ml未达到最大容量时,直接向其中增加样本特征; 当记忆库Ml达到最大容量时,则移除最旧的样本特征后再补充最新样本特征,以保持容量限制。
2.3.3 对比学习模块
该模块由正样本扩充、记忆库构建和损失值计算3个步骤构成,详细流程如图 3所示。
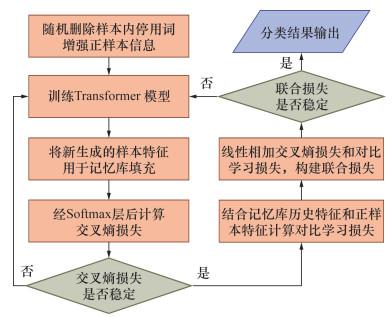
1) 正样本增强:由于对比学习以自身为正样本计算所得的相似度始终为1,无法体现正样本意义。因此通过样本内无关信息随机删除的方式实现正样本增强,以提高关键信息在句中的权重。在批容量为N的模型中,样本通过Python中jieba库分词后以p=0.5的概率随机删除无关停用词,将这N个原始样本扩充为2N个正增强样本。
2) 记忆库构建:设定容量、特征维度与指针,根据式(8) 构建各个类别的记忆库。在模型的初始计算阶段,样本量不足以完全填充记忆库,在此由系统随机生成样本并填充记忆库。指针初始位置为0,当每个批次样本特征计算完成后,将替换记忆库中原有的随机样本并更新指针位置。
3) 损失值计算:在记忆库首轮替换阶段仅采用交叉熵损失函数进行模型优化。若在记忆库首轮更新完成前采用联合损失函数优化模型,会出现样本与随机数进行对比的情况,这会导致训练过程受到干扰,从而使模型难以收敛。在记忆库首轮更新完成后,样本以随机删除生成的新样本为正样本,以其他类别的记忆库为负样本,根据式(5)计算对比学习损失。并根据式(7)计算联合损失函数以实现模型优化。
2.4 记忆库改进的半监督对比学习模块
基于Transformer和改进半监督对比模块的隐患文本分类模型包含隐患文本输入、编码与解码、模型分类与模型优化4个主要步骤。文本数据经预处理并标注后,在Transformer层通过MHA有效捕捉其中的语义特征及位置关系; 模型经几轮迭代后,在交叉熵损失初达平稳时引入对比学习损失,并与交叉熵损失共同构成联合损失函数继续优化模型; 在每轮迭代中构建了各类别的记忆库,用于记录每个类别的样本; 计算对比学习损失时,利用记忆库中来自不同类别的样本作为负样本,并通过标签信息过滤负样本属性,从而增强模型对样本之间差异的敏感性。具体步骤如下:
1) 隐患文本输入:整理特高拱坝施工安全隐患描述文本,针对第f条隐患文本,获得以句子为单位的输入数据,融合文本的输入嵌入与位置编码获得Transformer的输入Sf:
其中:wg为第g个位置的输入表示,Eg和Pg分别为第g个位置的嵌入向量和位置编码向量。
2) 编码与解码:融合文本嵌入和位置向量的信息将作为Transformer的输入,特征经编码器和解码器后实现深层特征提取。编码器、解码器分别输出的特征矩阵Hf、zf为
其中:Hf为第f条隐患文本经编码器得到的输出,Tf为第f条隐患文本目标序列嵌入和位置编码之和。
3) 模型分类:针对获得的句子特征,解码器计算获得特征经线性运算后映射到词表大小。选取softmax函数作为归一化函数。文本在每个标签上的概率为
其中:W为特征矩阵到词表大小映射的权重矩阵,b为偏置向量,F为本批次训练文本个数,$\hat{p}_{f}$为第f个隐患文本的softmax函数归一化结果。
4) 模型优化:模型优化包括对比学习模块和优化器选取2个方面。在对比学习模块中,构建的损失值由infoNCE损失、交叉熵损失2部分融合组成,计算方法见2.3节。选择自适应矩估计(adaptive moment estimation,Adam)优化器作为模型优化器,该优化器可以根据历史梯度信息来自适应地调节学习率,将对比学习模块生成的联合损失值反馈于模型中,不断优化模型参数。
2.5 基于LDA主题模型的隐患智能排查
2.5.1 LDA主题模型
LDA主题模型是一种三层递阶Bayes模型,包含单词-主题-文档三层结构[36]。该模型是一种无监督模型,可以在大规模文档中自动发现主题,在确定主题数目和文本语料集后自动提取相同主题的单词。模型认为每个文档由多个主题组成,对于每个文档,首先为其选择多个主题,然后根据主题生成单词。
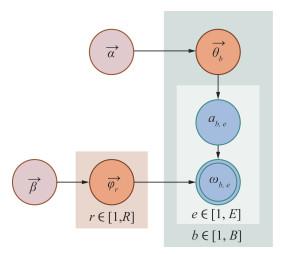
LDA主题模型认为文档由2个步骤生成(见图 4):1) $\vec{\alpha} \rightarrow \vec{\theta}_{b} \rightarrow a_{b, e}$,生成文档的主题分布。$\vec{\theta}_{b}$为第m篇文章主题分布,$\vec{\alpha}$ 为$\vec{\theta}_{b}$的参数,ab, e为第b篇文档中的第e个主题。2)$\vec{\beta} \rightarrow \vec{\varphi}_{r} \rightarrow \omega_{b, e} \mid r=a_{b, e}$,在确定单词分布的条件下生成文档中的单词。$\vec{\varphi}_{r}$为第r个主题的单词分布,$\vec{\beta}$ 为$\vec{\varphi}_{r}$的参数,ωb, e为第b篇文档生成的第e个单词。LDA主题模型的联合概率分布为
其中:R、B和E分别为主题数、文档数和单词数。
在LDA主题模型中,Dirichlet分布中的先验参数α和β一般由经验确定,需要求解的参数为θ和φ,通常采用Markov链Monte Carlo(Markov chain Monte Carlo,MCMC)方法对复杂分布模型进行表示,并采用Gibbs采样求解MCMC高维分布。通过Gibbs采样算法得到了文档中每个主题的生成概率以及主题中每个单词的生成概率,并将同一主题的关键词归类,以达到挖掘文档中的隐含主题信息的效果。
2.5.2 隐患排查线索分析流程
隐患排查线索分析流程如图 5所示。在收集碎片化隐患文本后对其进行预处理,构建隐患文本智能分类模型并获取隐患类别、隐患等级。进一步将已分词和去停用词的隐患描述输入至LDA模型进行主题分析。在各隐患类别和等级的条件下,通过LDA主题模型提取多个主题的关键词表,这些主题能够揭示当前隐患类别和等级中存在的潜在风险。随后,将获得的主题关键词与后续识别的主题相结合,形成隐患排查线索,通过识别出最佳排查重点来指导后续的实际工作。在后期工程中,依据隐患的类别、等级下存在的排查重点,对施工隐患进行逐条排查与分析,管理人员能够有针对性地聚焦在高风险隐患上,从而提高排查的效率和准确性,确保施工安全。
3 工程实例
3.1 工程背景及数据来源

表 1 特高拱坝施工安全隐患数据集 |
| 隐患描述 | 隐患类别 | 隐患等级 |
| 电焊机直接放在仓内钢筋上,未绝缘保护 | 触电 | 严重隐患 |
| 风机警戒标志反光锥沾满灰尘倒地,过往车辆易因误视有撞击风机的危险 | 车辆伤害 | 严重隐患 |
| 竖井长期流水,井壁存在坍塌可能。车辆从竖井下部通过存在安全隐患 | 坍塌 | 重大隐患 |
| 六层廊道交通洞废渣堆积,影响人员车辆通行 | 文明施工 | 一般隐患 |
| 3#尾调通气支洞口砂轮机防护罩脱落,存在安全隐患 | 机械伤害 | 严重隐患 |
| 左导2交通洞内变压器旁放置油桶、乙炔瓶,易产生火灾,存在安全隐患 | 火灾 | 较大隐患 |
| 加工车间内,使用安全性能较低的液化气瓶代替乙炔瓶,且未设置回火阀 | 爆炸 | 严重隐患 |
| 左侧岩壁梁排架上一施工人员未戴安全帽 | 三违行为 | 一般隐患 |
| 修复平台后未把剩余钉子清理干净,有从狭缝掉落到尾水伤人危险 | 物体打击 | 严重隐患 |
| 14#引水上平洞内积水严重,水泵出现故障未及时处理,存在安全隐患 | 淹溺 | 一般隐患 |
| 1#场地汽车吊起重作业时,运砖汽车违规进出起吊作业区域 | 起重伤害 | 较大隐患 |
| 左岸水垫塘边坡模板平台防护栏杆倾斜,存在坠落风险 | 高处坠落 | 重大隐患 |
监理环节通常记录了可直接获得的隐患属性(如类别、位置),但没有明确标记安全隐患等级。安全隐患等级是衡量安全隐患致灾程度的重要指标,可以帮助管理人员快速了解安全隐患的严重性。这些隐患等级通常需要极富经验的管理人员识别。为保证隐患等级判定的客观性,在标注过程中充分依据了相关规范制度和工程实践经验。结合《水利水电工程施工安全管理导则SL721-2015》[44]与工程单位的安全隐患排查治理制度,将安全隐患划分为4个等级:重大隐患、较大隐患、严重隐患、一般隐患[45]。这些等级由极富工程经验的工程安全监理人员进行判定,并且这些判定结果直接应用于施工生产中。根据安全隐患内容,共标注2 088条隐患等级文本,特高拱坝施工安全隐患等级数据集如表 1第3列所示。
3.2 实验方案与评价指标
以隐患描述-类别数据集为数据集Ⅰ,隐患描述-等级数据集为数据集Ⅱ。将2个数据集文本划分为训练集、验证集以及测试集3个部分。其中训练集中数据集Ⅰ为26 981个文本数据,数据集Ⅱ为2 088个文本数据; 验证集中数据集Ⅰ为4 108个文本数据,数据集Ⅱ为699个文本数据; 测试集中数据集Ⅰ为4 108个文本数据,数据集Ⅱ为699个文本数据。本实验的计算环境为Python 3.7,CPU为IntelⓇ CoreTM i5-10700K,GPU为NVIDIAⓇ GeForce GTXTM 1650,利用PyTorch框架构建模型。
为评价模型分类实验结果,选取准确率(accuracy)、精确度(precision)、召回率(recall)、F1分析实验结果。
其中,TP、TN、FP、FN分别为真阳性、真阴性、假阳性、假阴性样本数量,用于评价模型在文本标签预测中的预测效果。
在模型训练过程中,当批次(epoch)进行到6时引入联合损失函数,每迭代100次记录训练集及验证集的损失值及准确率,以验证集损失值最低且准确率最高时的模型参数为最优参数,并当迭代次数到达30 000次没有出现更优验证集损失时停止模型迭代。在本实验中模型参数选择情况如表 2所示。
表 2 实验参数选择 |
| 参数 | 说明 | 数据集Ⅰ | 数据集Ⅱ | 参数 | 说明 | 数据集Ⅰ | 数据集Ⅱ | |
| embedding_size | 输入向量维度 | 100 | 100 | pad_size | 句长 | 32 | 32 | |
| dropout | 随机失活 | 0.1 | 0.1 | learning_rate | 学习率 | 0.001 | 0.001 | |
| num_encoder | 编码器个数 | 6 | 2 | num_decoder | 解码器个数 | 1 | 1 | |
| num_head | MHA头数量 | 5 | 5 | temperature | 温度系数 | 0.07 | 0.07 | |
| MB_size | 记忆库容量 | 960 | 800 | batch_size | 迭代批容量大小 | 96 | 16 |
3.3 多分类结果评价
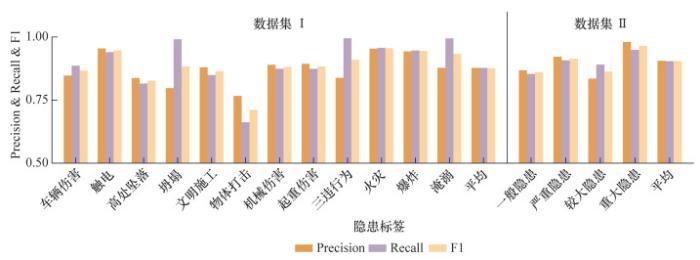
确定实验参数后,依据本模型对安全隐患的类别及等级信息进行识别,分类模型的性能如图 7所示。模型整体在2个数据集的加权平均F1值分别为0.8759和0.9045,平均准确率分别为0.8776和0.9040。在数据集Ⅰ中10个类别的F1值大于0.85,“物体打击”类别因在实际工程中多存在与其他类别重合的现象,因此识别准确率较低,除“物体打击”外其他类别的加权平均F1值可达0.90。在数据集Ⅱ中4个类别的F1值均大于0.85,“严重隐患”和“重大隐患”的F1值达到0.90以上。结果证明了类间关系的应用在多个数据集类别识别中均可达到较好效果。另外,2个数据集在训练量级上有所不同,也说明了本文模型在不同量级训练文本中均能保持优良性能。
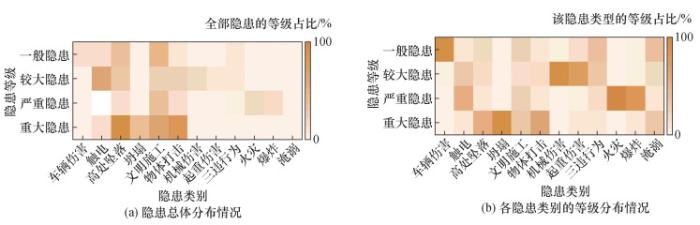
通过对隐患数据进行多维度分析,能够有效揭示各类隐患所对应的风险水平,并深入探讨其内在关联性。在工程实践中,不同类别的隐患通常具有各自特定的隐患等级分布,探索这些关系对于管理人员发现隐患排查线索至关重要。因此采用分类算法对隐患描述进行隐患类别和隐患等级的分类识别。本文分析了该特高拱坝2015年11月至2017年6月份记录的安全隐患情况,隐患分布情况如图 8所示。由图 8a可知,“高处坠落”、“文明施工”和“物体打击”在工程中出现频率极高,并且常以重大隐患形式出现; 由图 8b可知,“高处坠落”、“坍塌”和“物体打击”主要集中在重大隐患,“触电”、“火灾”和“爆炸”主要集中在严重隐患。因此“触电”“高处坠落”“坍塌”“文明施工”“物体打击”“火灾”“爆炸”几类隐患需要着重管理。特别突出的是,“高处坠落”、“文明施工”和“物体打击”因其频繁出现且危害性较大,理应成为管理人员的重点关注对象。
3.4 隐患排查线索分析
表 3 隐患线索排查表 |
| 隐患类别 | 隐患等级 | 主题词(排查线索词) | 主题信息(排查线索主题) |
| 高处坠落 (20.4%) | 一般隐患 (20.5%) | 临边、警戒、警示、缺失、设置、警戒线、损坏、坠落 安全带、未系、作业、作业、绳、施工人员、坠落、佩戴 栏杆、坠落、风险、爬梯、缺失、损坏、通行、发生 排架、坠落、跳板、竹条、绑扎、缺失、封闭、伤害 | 临边警戒缺失风险 工人安全设施缺失 防护栏杆缺失风险 竹条绑扎不足风险 |
| 较大隐患 (18.2%) | 马道、模板、缺失、栏杆、临边、坠落、防护、防护栏 破损、吊车、吊篮、作业、危险、防护、工人、措施 坝肩、水垫塘、高空作业、坠落、安全带、母线洞、备仓施工、高处 平台、堵头、封闭、模板、安全、跟进、防护、隐患 | 马道防护缺失风险 吊车吊篮危险作业 工人高空作业风险 堵头暂未封闭风险 | |
| 严重隐患 (9.1%) | 发生、作业、排架、坠落、操作、易、搭设、风险 尾水、尾水洞、吊篮、防护、连接管、不足、块石、调压 临边、隐患、护栏、水垫塘、大盘、伤害、缺失、坠落 盖板、孔洞、警示、坠落、过大、跳板、坠落、风险 | 排架作业坠落风险 尾水防护缺失风险 临边防护缺失风险 孔洞防护缺失风险 | |
| 重大隐患 (52.2%) | 台车、坠落、栏杆、高空、风险、马道、临边、变形 夹板、坠落、踏翻、断裂、水垫塘、风险、马道、施工现场 安全防护网、振捣、倾翻、平台、坝肩、马脖子、进水塔 竖井、临边、井口、井盖、损坏、变形、坠落、警示 | 台车高空坠落风险 夹板破损坠落风险 振捣平台倾翻风险 竖井变形坠落风险 |
注:隐患类别中百分数为该隐患类别占总体隐患的比例,隐患等级中百分数为对应隐患类别下各等级隐患发生比例。 |
在提取主要排查主题词后,结合线索词在文本中的语境,确定出每个排查线索主题的含义,从而获得完整的隐患排查线索表(见表 3)。通过该表,管理人员可以在实际工程监理中实施针对性的隐患排查。在隐患排查过程中,如遇高处坠落高发位置,如坝体结构施工平台及附属工程,需重点关注的重大隐患有“台车高空坠落风险”“振捣平台倾翻风险”等,严重隐患有“排架作业坠落风险”“临边防护缺失风险”,除此之外,还需关注“马道防护缺失风险”“工人高空作业风险”等。
该方法保证了管理人员更关注重点隐患,优化了资源配置,提高了排查效率。通过智能算法与实际工程的深度结合,提升了历史碎片化文档的应用水平,辅助管理人员识别潜在隐患。而为增强实际应用水平,后续研究中可将本方法与隐患管理平台、虚拟现实(virtual reality,VR)技术、VR眼镜、推荐算法等相结合,根据隐患排查线索辅助管理人员动态感知周围隐患,并实时判断隐患属性,为管理人员提供决策信息,提高特高拱坝安全隐患排查方法的实际应用水平。
另外,考虑到安全隐患的发生在整个施工生命周期中是动态变化的,可以选取近期收集的隐患文本进行及时分析。此举保证了数据分析的时效性,从而为后续阶段的管理决策提供有针对性的支持。
4 讨论
4.1 参数分析与消融实验
表 4 数据集Ⅰ记忆库大小对比 |
| MB_size | Precision | Recall | F1 |
| 192 | 0.868 3 | 0.865 9 | 0.864 1 |
| 480 | 0.871 1 | 0.869 3 | 0.867 7 |
| 960 | 0.877 4 | 0.877 6 | 0.875 9 |
| 1 920 | 0.872 0 | 0.869 3 | 0.867 0 |
| 4 800 | 0.876 2 | 0.874 6 | 0.873 0 |
表 5 数据集Ⅱ记忆库大小对比 |
| MB_size | Precision | Recall | F1 |
| 80 | 0.886 7 | 0.881 1 | 0.882 0 |
| 160 | 0.895 2 | 0.892 6 | 0.893 5 |
| 400 | 0.898 3 | 0.888 3 | 0.890 0 |
| 800 | 0.905 6 | 0.904 0 | 0.904 5 |
| 1 600 | 0.895 5 | 0.894 0 | 0.894 6 |
采用消融实验以验证本文模型各个模块的有效性,以Transformer(Trm)、记忆库(MB)、数据增强(SE)、对比学习(CL)进行组合,共设置5组模型实验(见表 6)。为保证模型对比的准确性,主要参数与本文模型设置一致。消融实验结果表明,MB、SE和CL的引入提升了分类效果,合适的数据增强和记忆库对于对比学习性能的提升有促进作用。本文模型F1值比传统Transformer模型在2个数据集上分别提升了4.9%和3.3%,验证了类间关系的利用对模型表征能力和泛化性能的积极影响。
表 6 消融实验 |
| 模型名称 | 数据集Ⅰ | 数据集Ⅱ | |||||
| Precision | Recall | F1 | Precision | Recall | F1 | ||
| Trm+MB+CL+SE | 0.877 4 | 0.877 6 | 0.875 9 | 0.905 6 | 0.904 0 | 0.904 5 | |
| Trm+CL+SE | 0.870 6 | 0.867 1 | 0.866 0 | 0.897 5 | 0.895 4 | 0.896 2 | |
| Trm+CL | 0.837 9 | 0.835 7 | 0.835 5 | 0.882 3 | 0.882 5 | 0.882 3 | |
| Trm+SE | 0.850 9 | 0.845 7 | 0.845 9 | 0.880 7 | 0.881 1 | 0.880 4 | |
| Trm | 0.839 1 | 0.836 4 | 0.834 8 | 0.875 5 | 0.875 4 | 0.875 2 | |
4.2 对比学习模块有效性分析
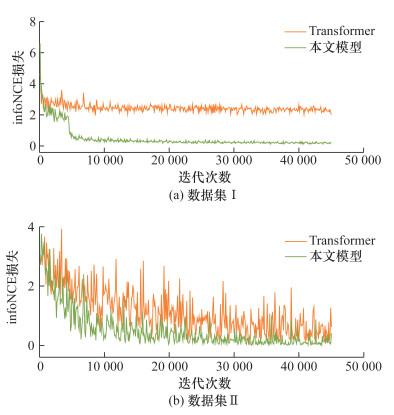
本文模型中对比学习模块通过infoNCE损失实现模型参数优化。为了验证对比学习损失在训练过程中是有效的,对比了本文模型与Transformer在infoNCE损失上的表现。其中,Transformer仅在模型迭代过程中计算infoNCE损失,而不进行前馈优化。图 10记录了模型迭代过程中infoNCE损失的变化情况,infoNCE损失在本文模型中下降更快且更多,并且在模型稳定后处于较低水平,即相同类别样本在向量空间中样本更接近、不同类别样本更为远离,可以证明对比学习在训练过程中是有效的。
4.3 模型间效果对比
为验证本文模型相比其他常用模型具有一定的优越性,以BERT、RCNN(recurrent convolutional neural network)、BiLSTM(bidirectional long short-term memory)、CNN、RNN(recurrent neural network)、FastText等深度学习算法作为对比模型。为保证模型对比的准确性,主要参数与本文模型设置一致,其他参数参考已有研究中的最佳参数值。表 7结果显示,本文模型在整体效果上均优于其他文本分类模型,验证了本文模型在施工隐患多分类任务中的良好表现。
表 7 模型间分类效果对比 |
| 模型名称 | 数据集Ⅰ | 数据集Ⅱ | |||||
| Precision | Recall | F1 | Precision | Recall | F1 | ||
| 本文模型 | 0.877 4 | 0.877 6 | 0.875 9 | 0.905 6 | 0.904 0 | 0.904 5 | |
| BERT | 0.863 5 | 0.862 7 | 0.861 2 | 0.892 6 | 0.887 4 | 0.887 4 | |
| RCNN | 0.835 7 | 0.847 5 | 0.833 0 | 0.876 7 | 0.872 5 | 0.874 1 | |
| BiLSTM | 0.835 6 | 0.834 5 | 0.832 3 | 0.880 5 | 0.871 1 | 0.872 2 | |
| CNN | 0.821 0 | 0.812 3 | 0.810 1 | 0.877 6 | 0.876 8 | 0.876 8 | |
| RNN | 0.817 9 | 0.830 9 | 0.814 8 | 0.878 7 | 0.873 9 | 0.875 2 | |
| FastText | 0.783 7 | 0.774 1 | 0.771 4 | 0.800 5 | 0.802 3 | 0.797 6 | |
4.4 工程应用拓展性讨论
本文通过分类算法和主题模型构建了特高拱坝隐患排查线索表,这为后续工程建设中的监理活动提供了依据和帮助。值得注意的是,对于工程早期缺乏足够的施工隐患排查数据时,可以借鉴其他相似工程的隐患记录与工程经验。通过采用本文方法分析相似工程早期施工隐患记录,并结合工程实际情况与监理人员施工隐患排查经验进行修正,获取早期隐患排查线索。另外,尽管本文以特定工程为案例进行实例分析,但该工程作为当今世界在建规模最大、技术难度最高的特高拱坝,具有较强的代表性和典型性。因此,研究结果不仅适用于该项目的后续建设,也可推广到其他相似类型的特高拱坝项目。通过本文方法,工程经验可以最大程度地反馈至新工程建设中,并覆盖工程的各个阶段,从而为隐患排查提供更全面、精准的指导。
5 结论
本文提出了特高拱坝施工隐患智能排查方法。基于半监督对比和记忆库的隐患文本分类模型,实现了隐患类别和等级的智能识别。模型以Transformer和对比学习为主体架构,有效获得隐患描述的语义特征及位置关系,构建对比学习模块捕捉隐患文本间的类间关系,通过自监督信号扩大异类样本的差别。引入记忆库改进对比学习模块,通过存储历史样本特征实现负样本的全面采集,增强模型对样本之间差异的敏感性。然后,结合隐患类别和隐患等级识别结果,通过主题模型提取多个主题的关键词表,揭示当前隐患类别和等级中存在的潜在风险并获得完整的隐患排查线索表。管理人员可通过该表实施针对性的隐患排查,优先关注高风险区域,确保人力和物资合理分配,提高隐患识别和排查能力,进一步提高工程监理工作效率。
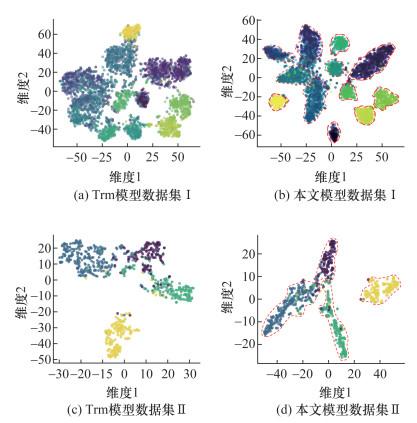
在2个数据集上对本文模型的验证可知模型性能良好。主要表现为:1)讨论了不同尺寸记忆库对模型性能的影响,体现了记忆库解耦批次和负样本数的重要性; 2)采用消融实验验证了各个模块对于模型效果提升的有效性; 3)采用t-SNE方法实现分类样本的降维聚类,可视化地验证了对比学习模块的聚类能力; 4)对比本文模型与Transformer在infoNCE损失中的表现,验证对比学习模块在实际模型训练中的有效性; 5)与常见分类模型进行效果对比,本文模型在整体效果上取得了显著优势。
下一步,针对分类方法,将继续优化对比学习负样本的采样方法,动态地构建样本一致性更强的字典,从而提高对比学习的稳定性。针对特高拱坝隐患排查线索分析,将进一步细化排查线索表构成,增加空间、时序等信息; 同时,将结合隐患管理平台、VR眼镜等设备,并借助智能推荐技术,推动隐患智能排查的实际应用。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}