

火灾是生命财产安全的重大威胁。据应急管理部统计(https://www.119.gov.cn/qmxfxw/mtbd/wzbd/2025/48022.shtml),中国2024年火灾导致的伤亡人数约4 700人,直接经济损失达77.44亿元。火灾的早期预警可以大大降低人员伤亡与财产损失。烟雾作为火灾初期最显著的可视化特征,对烟雾进行精准检测对于缩短应急响应时间至关重要。相较于传统传感器受限于探测范围与环境干扰,基于视频图像的烟雾检测技术凭借非接触、大范围覆盖的优势,已成为智慧消防领域的核心研究方向。
在传统的视频烟雾检测方法中,图像处理技术依赖于图像的灰度、纹理、边缘等特征,通过阈值分割、边缘检测等手段识别烟雾区域[1-5]。尽管这些传统方法在特定环境下可以取得一定效果,但在处理低对比度、高噪声、复杂背景等场景时,其表现往往不尽如人意。随着深度学习方法的发展,基于深度神经网络的目标检测方法逐渐成为烟雾检测研究的趋势。YOLO(you only look once)系列等[6-10]一阶段算法以高效的检测速度和实时性,成为许多实际应用的首选方案,但其锚框机制对小目标烟雾敏感度不足[11]。相比之下,检测变换器(detection transformer,DETR)系列算法[12-17]具有全局图像建模能力和较强的目标感知能力,凭借无锚框的设计与全局注意力机制,在烟雾形态多变场景中展现出更优的尺度适应性[18]。
尽管现有方法在提升烟雾检测可靠性方面取得了一定进展,但仍面临以下挑战:1) 初期烟雾尺寸小且纹理稀疏,浅层网络难以捕捉有效特征;2) 烟雾边界模糊,灰度与背景接近,导致对低对比度区域的检测性能差;3) 烟雾形态不定、局部结构不明显,导致远距离建模能力不足。这些问题不仅影响了检测精度,也限制了烟雾检测在复杂场景中的应用。
针对这些挑战,本文提出一种融合空间感知与显著性建模的烟雾检测算法(multi-scale dynamic saliency detection transformer,MDS-DETR)。首先,为解决烟雾尺度多样性导致的特征表达局限,设计了一种多尺度并行卷积特征提取机制,通过层次化集成不同感受野的局部纹理与上下文信息,在抑制背景噪声的同时强化稀疏烟雾的特征表征。其次,针对烟雾与低对比度干扰物的灰度重叠问题,提出动态范围自适应的注意力重构方法,基于像素强度分布构建跨区域特征关联,增强烟雾边界的显著性差异。进一步,为应对烟雾扩散过程中的形态断裂与局部渐变特性,引入显式空间衰减约束的注意力机制,结合Manhattan距离权重与局部上下文增强模块,在降低冗余计算的同时提升断裂烟带连续性感知能力。实验结果表明,本文方法在自建的多场景烟雾数据集中实现了94.0%的平均精度(average precision,AP),比实时检测变换器(real-time detection transformer,RT-DETR)基准模型的平均精度提升5.5%。本文方法通过引入动态范围统计与显式空间衰减机制,提升了复杂环境下的鲁棒性检测能力。
本文主要贡献如下:1) 针对烟雾检测中尺度多样性导致的小目标特征稀疏问题,提出多核并行卷积模块(multi-kernel parallel convolution module, MKPCM),通过集成多尺度深度卷积与跨感受野特征融合,显著增强小目标特征的纹理表达能力;2) 针对烟雾与低对比度干扰物的灰度混淆问题,设计动态直方图轴向交互模块(dynamic histogram axial interaction module,DHAIM),基于动态范围分箱统计与跨区间注意力重构,缓解低对比度干扰;3) 针对烟雾形态断裂与局部渐变特性,构建空间衰减残差模块(spatial decay residual block,SDRB),通过Manhattan距离约束的注意力衰减与局部上下文增强,提升烟雾形态连续性建模能力。
1 相关工作
1.1 DETR系列目标检测算法的发展
随着深度学习的发展,基于Transformer的目标检测方法逐渐受到关注。DETR系列算法作为基于Transformer的目标检测框架,具有全局建模的优势,成功地摆脱了传统目标检测方法依赖区域候选框的束缚。DETR由Facebook团队于2020年提出[12],通过全局自注意力机制直接根据图像的原始像素生成预测信息,无须依赖锚框或候选区域生成网络。这使得DETR在处理复杂场景时,能够有效地捕捉长距离的依赖关系。
尽管这些改进使得DETR在目标检测领域取得了较好的平衡,但在一些特定应用场景中,仍然存在小目标检测难、复杂背景下适应性不足等问题。针对这些挑战,本文提出了一种基于RT-DETR的改进框架,旨在通过引入多尺度特征提取、动态范围建模及显著性增强等技术,进一步提升复杂场景下火灾早期烟雾检测的精度和鲁棒性。
1.2 注意力机制与显著性建模
传统的卷积神经网络通过局部感受野提取特征,但在面对复杂场景时,局部特征往往不足以捕捉全局上下文信息。为了弥补这一不足,注意力机制应运而生,通过对不同位置的特征赋予不同的权重,提升模型的表达能力。
此外,显著性建模[22]也是提高模型性能的重要方法。显著性通常指的是图像中具有突出特征的区域,这些区域往往对目标检测至关重要。通过显著性建模,模型能够关注到图像中的关键区域,抑制不相关的信息,从而提高检测的准确性。在目标检测中,显著性建模通常与注意力机制结合使用,以进一步提高特征的选择性和表达能力。
在烟雾图像检测中,烟雾的边界往往模糊,且在不同场景中呈现的形态特征有所不同,因此如何准确捕捉到烟雾的显著性区域,成为提升检测性能的关键。为此,本文通过引入自适应注意力机制和显著性增强模块来提升烟雾检测方法在复杂场景下的准确性和鲁棒性。
1.3 动态范围与空间感知理论
动态范围与空间感知理论是近年来在图像处理和目标检测中兴起的研究方向。动态范围指图像中像素值的变化范围。对于低对比度图像或受噪声干扰的图像,动态范围的处理尤为重要。Sun等[23]提出动态范围直方图注意力,通过分箱统计与跨区间特征交互恢复退化区域。烟雾作为一种低对比度、高透明度的气溶胶,其边界模糊且易受到背景干扰,因此有效处理图像的动态范围,成为提升烟雾检测性能的一个重要突破方向。
在目标检测中,动态范围和空间感知的结合能够提升模型在复杂背景、低对比度区域和强烈噪声干扰下的鲁棒性。近年来,许多研究提出了基于动态范围和空间感知的增强方法,以提高模型在极端场景下的性能。
2 MDS-DETR方法
为增强对稀疏、低对比度、模糊及尺度多变的烟雾目标的检测能力,本文从网络结构、局部上下文建模、显著性增强和空间建模4个方面设计了烟雾检测方法MDS-DETR。
2.1 整体网络结构
本研究以RT-DETR作为基础模型。RT-DETR作为一种基于Transformer的目标检测算法,具有较强的全局建模能力,但在处理小尺寸烟雾目标时存在一定的局限性。为此,本研究提出了一种基于空间感知与显著性建模的烟雾检测框架MDS-DETR,其整体结构如图 1所示。
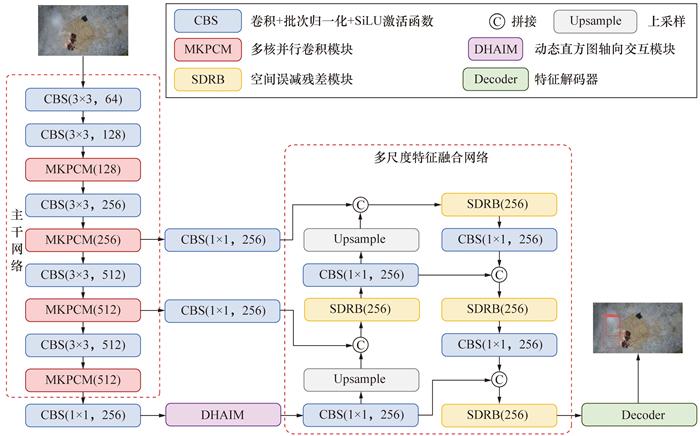
MDS-DETR主要包括3个部分:主干网络、多尺度特征融合网络和检测头。在主干网络中,原始残差模块被替换为MKPCM,通过多分支深度可分离卷积增强局部纹理建模能力,并引入跨阶段轻量连接降低计算冗余。在多尺度特征融合网络部分,将原始轴向注意力替换为DHAIM,通过分箱统计与跨区域关联提升烟雾与背景的灰度可分性。在检测头部分的RepC3模块中嵌入SDRB,利用Manhattan距离约束注意力权重分布,增强断裂烟雾区域的连续性建模,从而完成对烟雾目标的精确检测。
2.2 多核并行卷积模块
RT-DETR的原始主干网络基于连续3×3卷积堆叠构建特征金字塔,这种方式在烟雾检测任务中存在两个显著缺陷:1) 单一尺寸的卷积核难以覆盖烟雾目标从稀疏扩散到密集聚集的尺度多样性;2) 卷积层连续堆叠的结构在复杂场景下易出现特征退化现象,导致小目标烟雾的纹理信息丢失。为此,本文提出多核并行卷积模块,通过层次化多尺度特征融合,提升主干网络的特征提取能力。
MKPCM由多核并行卷积层、上下文锚点注意力机制与残差融合3部分组成,其结构如图 2所示。该模块首先通过1×1卷积对输入特征Fin进行通道升维,按通道维度进行拆分后再使用1×1卷积提取局部特征,生成中间特征Fhid。随后,并行执行5组深度可分离卷积,卷积核尺寸分别为3×3、5×5、7×7、9×9、11×11,以提取不同感受野下的局部特征。然后,将所有卷积路径的输出在通道维度上拼接,并通过逐点卷积进行融合,得到融合后的特征FPCM。
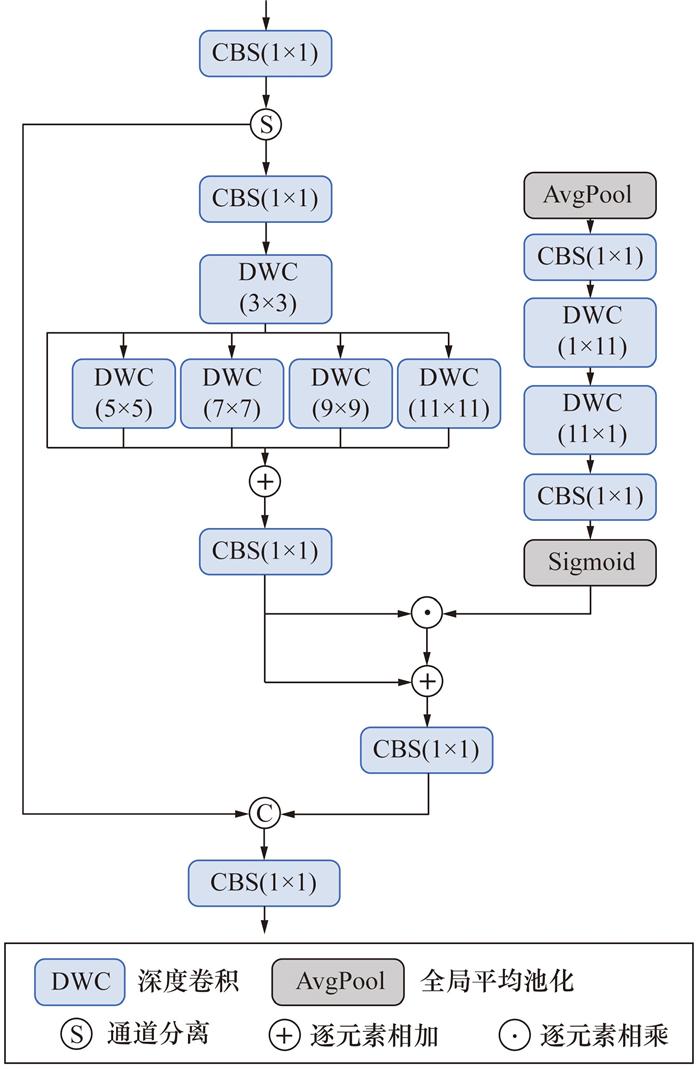
为进一步增强烟雾边缘的显著性,引入上下文锚点注意力(context anchor attention,CAA)机制模块。该模块通过对每个空间位置进行卷积操作,捕捉图像中的长程依赖关系,并通过一个Sigmoid门控机制输出加权图,从而增强模型对重要特征的注意力。CAA模块的输出与原特征进行加权融合,进一步提升了网络的表现。然后,使用残差连接,将输入特征与处理后的特征进行加权融合,以防止信息丢失并保证梯度的有效传播。其输出通过后续的卷积层处理,得到最终的特征FMKPCM。
传统卷积神经网络仅使用固定大小的卷积核堆叠,而MKPCM引入多尺度卷积核并行结构,能更充分地覆盖烟雾扩散的尺度变化。同时,嵌入的上下文锚点机制对不同空间区域赋予权重,在复杂背景下更具空间感知优势。基于MKPCM重构主干特征提取网络,通过最初的2次标准卷积,将特征图尺寸降至原来的一半,并逐步扩展通道数。随后,在每个阶段中,使用MKPCM模块在输入特征上应用多个不同尺度的卷积核来捕捉丰富的空间信息。最后,通过逐层的卷积操作和残差连接,确保网络能够在训练中有效传播梯度,从而提高目标检测的精度。
2.3 动态直方图轴向交互模块
RT-DETR的基于注意力的尺度内特征交互(attention-based intra-scale feature interaction,AIFI)模块通过全局自注意力建模特征间长程依赖。但是,在烟雾检测任务中,烟雾与低对比度背景的灰度重叠导致注意力权重分布混乱,大量背景区域可能被误激活。为此,本文提出DHAIM,通过引入基于直方图的注意力机制来增强局部特征与全局上下文信息的交互,从而增强烟雾区域的灰度可分性,如图 3所示。
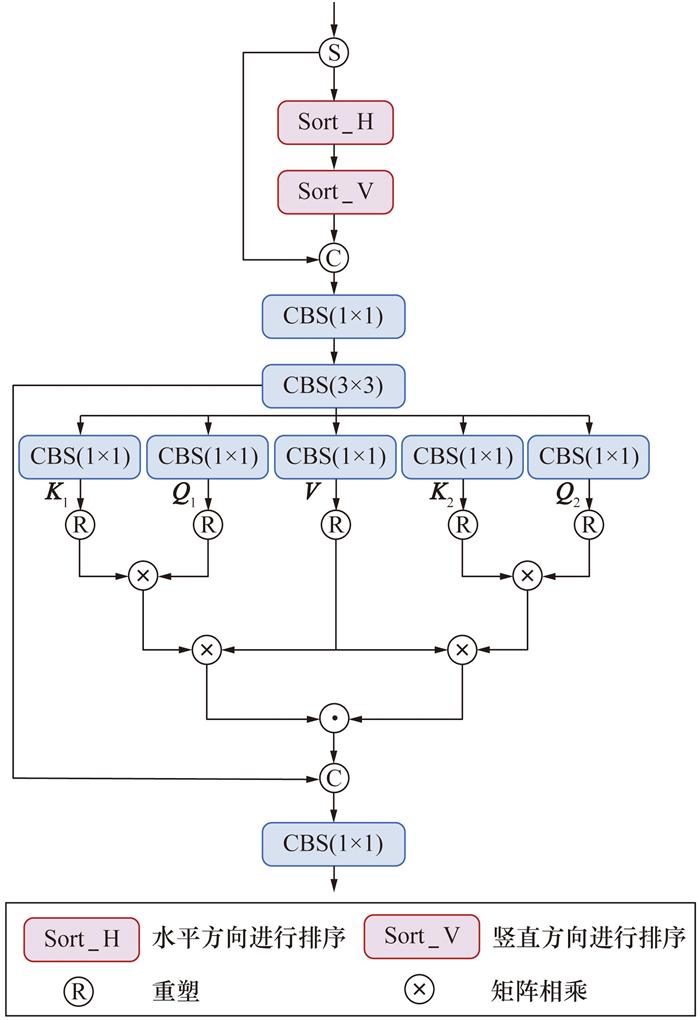
DHAIM借鉴了直方图变换模块(histogram transformer block,HTB)的设计思想,针对烟雾图像中退化特征的动态分布进行了改进。相比于传统的通道或空间注意力机制,通过动态直方图分箱的方式对特征图进行处理,将其划分为高对比和低对比区域,并分别对两者应用不同的注意力策略。这样的设计能显著提高低对比度区域的特征提取能力,从而提升图像中细节部分的检测效果。通过结合局部与全局的注意力机制,DHAIM能够更好地处理具有模糊边界的烟雾区域,避免了单一注意力机制带来的特征丢失或过度聚焦问题。
DHAIM首先通过动态范围卷积对输入特征图进行重排,从而增强对高低灰度差异区域的关注能力。对于输入特征Fin,首先将其沿通道维度拆分为F1与F2 2个分支。对F1分支在水平方向进行排序,对排序结果在垂直方向上再次排序,以突出灰度差异度较大的区域。随后将排序后的F1与原始的F2进行通道维度拼接并送入卷积模块,使后续注意力模块能够精准地捕捉烟雾干扰区域与背景之间的特征差异。
将卷积模块输出特征Fhid经过1×1投影卷积得到值特征V与2对查询-键特征(Q1, K1)、(Q2, K2)。基于值特征V的灰度排序索引d,对查询-键特征进行同步重排以保持空间一致性。随后,采用分箱统计策略构建全局分箱与局部分箱2类注意力。进行全局分箱注意力计算时,将特征划分为B个箱,每箱包含hw/B个像素,从而对烟雾大范围扩散模式进行建模,计算全局权重Aglobal; 进行局部分箱注意力计算时,以箱内像素为基本单位进行处理,从而捕捉烟雾边缘的碎片化细节,计算局部权重Alocal。其中:h为图像的高度,w为图像的宽度,单位为像素。
其中:WV、WQi、WKi为可学习参数,RB与RF分别表示全局分箱与局部分箱的重塑操作。双路注意力通过逐元素相乘融合以及分箱统计,自适应分配注意力权重,强化烟雾区域内部关联,同时抑制背景误激活。将融合后的注意力特征A基于排序索引d逆变换至原始空间位置,增强长距离空间建模能力,然后通过残差连接保留动态卷积提取的原始特征,提升检测小尺寸烟雾目标的能力。
2.4 空间衰减残差模块
RepC3模块通过融合技术和残差结构,在保持高性能的同时,优化了模型的推理速度,广泛应用于高效的特征提取与上下文建模任务。然而,在烟雾图像探测中,低对比度的烟雾区域与背景常常呈现出渐变式的局部特征,传统卷积结构的上下文建模能力无法充分捕捉这些精细的边缘变化。为了增强模型处理这些具有“边缘渐变”特征的图像的能力,本研究提出了一种空间衰减残差模块SDRB替代RepC3。该模块通过引入空间衰减感知机制,有效增强了近邻区域的权重分配,从而引导注意力集中于具有局部形变一致性的区域。
空间衰减注意力机制的核心思想是根据空间位置的距离调整注意力权重,模拟烟雾在图像中扩散的自然过程。SDRB通过Manhattan距离指数衰减生成水平和垂直方向的注意力掩码矩阵,使得模型在特征图中能够重点关注局部连续结构,同时有效抑制远距离像素对特征图的干扰。这种空间建模方法,相比于通道注意力机制(squeeze-and-excitation networks,SE-Net)和混合注意力机制(convolutional block attention module,CBAM) 的全局或局部加权方式,更能突出烟雾区域的空间拓扑特征,尤其适用于边界模糊、形态不规则的烟雾场景。因此,SDRB能够提供更强的空间感知能力,从而提升火灾烟雾图像的对比度。
SDRB的结构如图 4所示。对于输入特征Fin,首先通过1×1卷积进行通道升维,然后利用3×3深度卷积进行局部特征提取,通过残差连接得到Fhid。
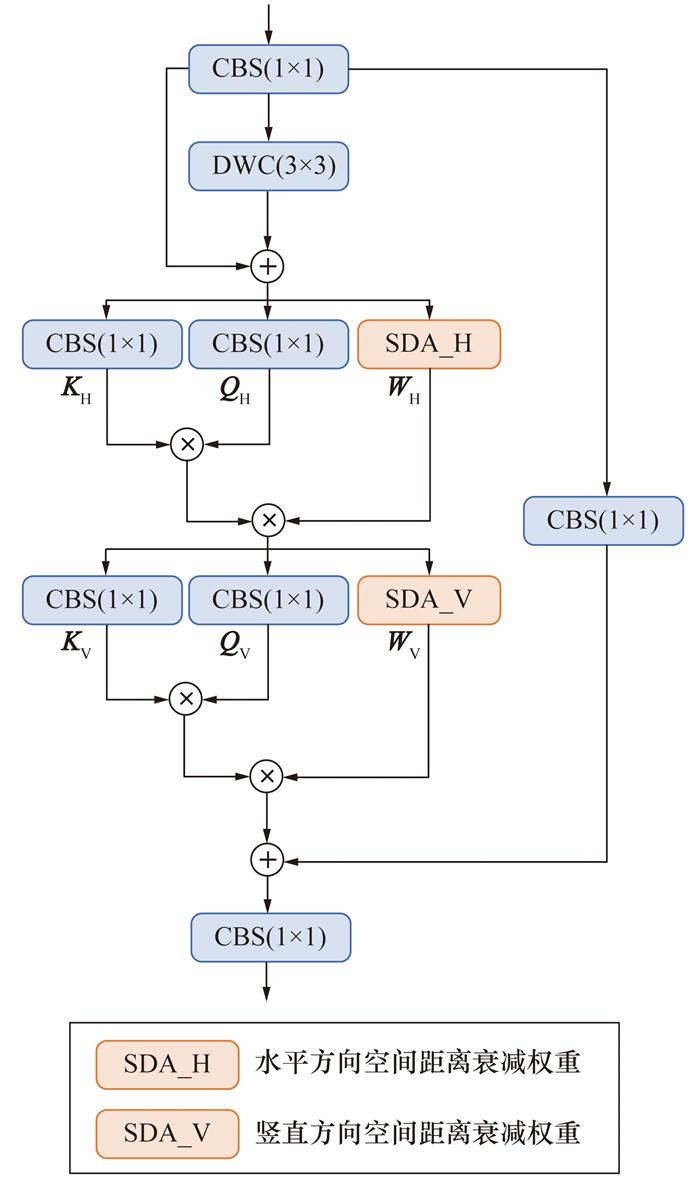
针对Fhid构造衰减权重矩阵WH、WV,其元素W(i, j)表示位置(xi, yi)对(xj, yj)的注意力贡献权重,由Manhattan距离指数衰减计算。
其中λ为衰减强度控制参数,强制注意力机制聚焦邻近区域,抑制远距离背景噪声(如树木、建筑边缘)对烟雾检测的干扰。为降低计算复杂度,将全局注意力分解为水平与垂直方向独立计算,二者分别沿行、列方向执行掩膜加权。
其中: QH、KH与QV、KV由输入特征Fhid生成,通过水平-垂直方向解耦注意力以线性复杂度建模烟雾的渐变与断裂模式,从而突破传统卷积的固定感受野限制。为弥补注意力机制对局部细节的忽略,模块引入深度可分离卷积构建局部上下文增强分支,通过残差连接融合方向注意力与原始特征,形成全局-局部互补的特征表达。
3 实验及结果分析
3.1 数据集建立
本研究从不同的公开数据集中收集烟雾图像数据,包括KMU(http://cvpr.kmu.ac.kr/)、VisiFire (http://signal.ee.bilkent.edu.tr/VisiFire/Demo)以及一个基于快速自适应背景差分算法的研究中使用的数据[26]。此外,本文作者在不同地点进行了多次点火实验,并拍摄了大量的烟雾视频。实验地点包括黄山、大兴安岭、紫蓬山、中国科学院大学西区校园、标准燃烧室等;使用的燃料包括棉绳、烟雾弹、柴油和山毛榉等。在从视频中提取图像时,每隔4 s提取1帧图像,以确保2个相邻样本之间有足够的差异。最终,构建了一个包含20 607张图像的烟雾数据集。图 5展示了其中一些烟雾图像。本研究以PASCAL视觉对象分类数据集(PASCAL visual object classes,PASCAL VOC)为模板,使用LabelImg标注图像中的烟雾。

3.2 实验环境
本研究的实验环境配置如下:CPU是Intel i5-113600KF,主频为3.50 GHz;内存为32 GB;GPU为Nvidia GTX4070 Ti,系统安装了CUDA 12.6和CUDNN。训练策略采用带动量的随机梯度下降法,并使用余弦衰减策略调整学习率,使用马赛克、混合和随机翻转等传统的数据增强。初始学习率设置为0.01,输入图像大小统一为640×640像素,迭代训练次数设置为100,批次大小为4。
3.3 评价指标
为了评估算法的性能,本研究引入了精确率(Precision)、召回率(Recall)以及AP。此外,检测帧率也是衡量视频推理速度的重要性能指标。Precision、Recall和AP的计算方式如下:
其中:TP表示被正确识别为正样本的数量,FP表示错误识别为正样本的数量(即误报),FN表示未被检测出的正样本数量(即漏报)。在测试过程中,根据实际需求对测试结果进行判断。为使本文提出的算法能够快速识别监控画面中的所有烟雾目标,通过检测框辅助相关人员定位起火点。当检测框与烟雾目标的真实框交并比(intersection over union,IoU)大于0.5时,判断为检测成功,否则即判断为漏报。
3.4 消融实验
为验证本文方法中各结构模块在烟雾检测任务中的有效性,基于RT-DETR-18基准模型进行了消融实验,主要检验3个核心改进模块:用于主干网络的MKPCM、用于多尺度特征融合网络的DHAIM及SDRB。消融实验在各模块分别独立引入以及全部联合引入的条件下进行,性能指标包括Precision、Recall、AP及推理速度。实验结果如表 1所示。
表 1 各结构模块消融实验结果统计 |
| 改进点 | 评价指标 | |||||||||
| MKPCM | DHAIM | SDRB | Precision | Recall | AP | 推理速度 | ||||
| % | % | % | 帧·s-1 | |||||||
| 86.2 | 81.4 | 88.5 | 56 | |||||||
| √ | 87.8 | 83.3 | 90.1 | 46 | ||||||
| √ | 87.3 | 83.9 | 89.8 | 63 | ||||||
| √ | 87.2 | 84.6 | 90.7 | 48 | ||||||
| √ | √ | √ | 91.5 | 86.7 | 94.0 | 46 | ||||
首先,将主干网络中的关键卷积结构替换为MKPCM模块。实验结果显示,MKPCM的引入使AP由88.5%提升至90.1%,Precision提升至87.8%,Recall提升至83.3%,尽管推理速度下降至46帧/s,但检测准确性得到显著提升。这表明MKPCM在应对烟雾类目标在图像中尺寸不一、形状模糊等挑战时具有积极作用。
接下来评估DHAIM模块替代原有AIFI模块后的性能表现。在保持模型整体结构轻量化的前提下,DHAIM将AP提升至89.8%,Precision提升至87.3%,Recall提升至83.9%,推理速度更是提升至63帧/s。这表明DHAIM在提升检测精度的同时,具有更优的速度性能,适用于对实时性要求较高的场景。
随后,本研究考察SDRB模块对特征融合的影响。相比于传统残差结构,SDRB能够更准确地恢复烟雾在复杂背景中的形态特征。实验结果表明,该模块将AP提升至90.7%,Recall提升至84.6%,Precision提升至87.2%,推理速度略降至48帧/s。这表明SDRB在提升边缘结构感知能力方面具有独特优势。
将MKPCM、DHAIM和SDRB 3个模块同时引入模型后,模型性能得到全面提升,Precision提升至91.51%,Recall提升至86.7%,AP提升至94.0%,比基准模型提升了5.5%,推理速度维持在46帧/s,满足大多数应用的实时性要求。该结果表明,3个模块在功能上具有高度互补性,MKPCM增强了特征提取的尺度适应性,DHAIM提升了目标特征聚合的灵活性,而SDRB则强化了边缘结构的表达一致性。这种模块间的协同优化显著提升了模型在多尺度、不规则、边界模糊等典型烟雾场景中的检测鲁棒性与精度。
图 6为消融实验中各模型的训练情况。epoch(轮次)表示模型完成对整个训练数据集完整遍历的次数。训练开始之后,各模型的性能随迭代次数逐步提升,添加改进模块后的模型性能始终优于基准模型。消融实验结果充分说明了所提出结构模块的有效性与实用性,尤其是在保持合理推理速度的前提下,模型实现了对烟雾类弱目标的准确检测,为后续工业部署和安全监控等实际应用提供了基础。
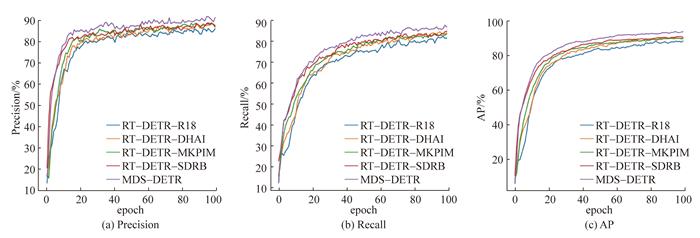
3.5 对比实验
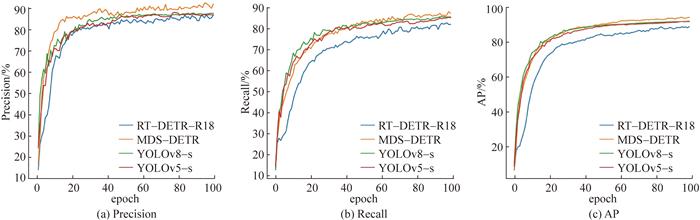
作为一款轻量化DETR模型,RT-DETR-18在基础模型设置下取得了88.5%的AP和56帧/s的推理速度,在保持端到端检测优势的同时,具备一定实时性。然而,其结构在处理细粒度纹理与边缘模糊特征时仍存在感知不足的问题,在训练过程中各项指标均为最低,最终的Precision与Recall分别为86.2%和81.4%,因此在实际消防任务中存在一定漏报与误报风险。
与之相比,YOLOv5-s作为经典一阶段检测器,凭借其高效的特征提取路径与良好的工程优化能力,达到了91.5%的AP与223帧/s的推理速度。YOLOv8-s在结构上进一步整合了RepVGG分支与轻量注意力机制,在不显著增加浮点运算次数(floating point operations,FLOPs)的前提下,将AP提升至91.7%,推理速度高达235帧/s,Precision和Recall分别为87.1%和84.9%。然而,两者均未对烟雾类目标的模糊边界、自适应尺度与断裂特性进行针对性建模,在复杂环境下的识别鲁棒性仍存在提升空间。
相比之下,本研究所提出的模型通过引入MKPCM、DHAIM与SDRB等结构模块,从多尺度交互、动态特征聚焦与边缘衰减建模3个方面增强了模型的感知能力,在不显著增加计算量(FLOPs为51.2×109)的情况下,实现了94.0%的AP,Precision高达91.5%,Recall达到86.7%;尽管推理速度略低于YOLO系列模型,但在烟雾图像这类高模糊、低对比、形态不规则的图像识别任务中展现出了更强的检测稳定性与细节识别能力。与YOLOv5-s相比,AP提升了2.49%,Recall提升了2.13%;与YOLOv8-s相比,AP提升2.3%,Precision提升4.4%。这些结果表明,本研究提出的方法在保持较高检测效率的同时,显著提升了对烟雾目标复杂特征的提取能力。


综合考虑检测精度、推理速度与模型复杂度等因素,本研究提出的方法在真实复杂场景下的安全监控与灾害预警系统中,具有较强的实用性与扩展潜力。
4 结论
本文提出了一种名为MDS-DETR的烟雾检测方法,在基准模型RT-DETR-18的基础上,通过引入MKPCM、DHAIM以及SDRB模块,有效增强了对烟雾图像中复杂背景、细节和边缘模糊区域的感知能力,提升了烟雾目标的检测精度。在处理烟雾这种典型的低对比度、模糊边缘和不规则形态的目标时,本文方法展现了更强的鲁棒性和精度。实验结果表明,所提方法在多个指标上均优于现有的主流检测算法。相比于YOLOv8-s,本文方法在AP上提高了2.3%,在Precision上提高了4.4%。尽管本文方法在推理速度上相较于YOLO系列算法有所下降,但其火灾早期烟雾的检测性能显著增强,且适用于复杂环境中的烟雾探测任务,因此在火灾预警和消防安全领域,具备了更强的实用性和扩展潜力。
尽管本文方法在烟雾检测任务中已取得较好的性能,但仍然存在一些问题。未来将进一步优化模型在推理速度和计算量上的平衡,以提高模型在实时应用中的适应性。同时,通过将本文方法扩展至其他目标检测任务,探索其在不同领域中的应用潜力,并结合其他先进的注意力机制,进一步提升检测精度与效率。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}