

众所周知,有限域上的快速Fourier变换(FFT)可以降低RS码的编译码复杂度[3-4]。Lin等[5]于2014年提出了一种有限域上新的FFT算法(简称LCH-FFT),该算法首次在二元扩域上实现了O(2ℓ log2(2ℓ))的复杂度(2ℓ为FFT的尺寸)。目前,研究者们已围绕LCH-FFT在RS码的快速编译码算法设计方面开展了诸多研究。Lin等[6]将LCH-FFT应用于RS码的纠删译码,针对一个(n, k)RS码(n为码长,k为信息长度,k/n为码率,k/n≤0.5且k为2的幂次),提出了一种基于LCH-FFT的编码算法,其复杂度为O(n log2k);Lin等[6]还提出了一种基于LCH-FFT的纠删译码算法,其复杂度为O(nlog2n),尽管该纠删译码算法是在低码率RS码的背景下提出的,但也适用于文[7]中的高码率RS码。Lin等[7]针对一个(n, k)RS码(k/n≥0.5且(n-k)为2的幂次),提出了一种基于LCH-FFT编码算法,其复杂度为O(nlog2(n-k)),同时提出了一种基于LCH-FFT的RS码译码算法(其中求解关键方程部分使用扩展Euclid算法),该算法是首次在二元扩域上实现了O((nlog2(n-k))+(n-k)log22(n-k))复杂度的RS译码算法[3]。Tang等[8]在文[6]的工作基础上进一步推广,取消了对(n-k)为2的幂次的限制,提出了一种称为“局部FFT(partial FFT)”的LCH-FFT算法,用于处理一般参数情况下的编码;同时也对译码的关键方程进行了推广。Tang等[9]于2022年基于文[10]推导出了一种新的变体,称为模方法(modular approach,MA)算法;并在此基础上提出了频域模方法(frequency-domain modular approach,FDMA)算法和快速模方法(frequency modular approach,FMA)算法,其复杂度分别为O((n-k)2)和O((n-k)log22(n-k))。结果表明,基于LCH-FFT的译码复杂度显著低于其他现有的RS码译码算法。Han等[11]和Tang等[12]研究了基于LCH-FFT的RS码纠错纠删问题,并推广了文[7]中的关键方程。在求解关键方程方面,Han等[11]采用扩展Euclid算法,而Tang等[12]采用MA算法。
目前,基于LCH-FFT的编码方法主要适用于多项式求值形式的RS码。然而在实际标准应用中,RS码几乎均为(缩短的)循环码,这类码作为一种特殊的BCH码是基于循环码生成多项式构造的。因此,探讨LCH-FFT编译码方法是否适用于基于BCH构造的循环RS码非常重要。
1 LCH-FFT算法
二元扩域$ \mathbb{F}_{2^{m}}$ 可以视为$ \mathbb{F}_{2}$ 上的一个m维向量空间。设{νi}i=0m-1为$ \mathbb{F}_{2^{m}}$ 的一组基。令{ωi}i=02m-1表示$ \mathbb{F}_{2^{m}}$ 的元素,每个元素可表示为
其中ij∈{0, 1}是i的二进制表示,即i=i0+i1·2+…+im-1·2m-1。定义$ \mathbb{F}_{2^{m}}$ 的一个ℓ维子空间Vℓ为
Vℓ的子空间多项式(subspace polynomial)定义为
Lin等[5]提出了$ \mathbb{F}_{2^{m}}[x] /\left(x^{2^{m}}-x\right)$ 上一种新的多项式基,称为LCH基,定义为
其中:
LCH-FFT算法是一种快速的多项式多点求值算法,其结果表示为
其中$ \beta \in \mathbb{F}_{2^{m}}$ 中的任意元素。对应的逆LCH-FFT算法是多项式插值的快速算法,表示为


一个8点LCH-FFT和逆LCH-FFT算法的示例如图 3所示,体现出一种并行实现结构。由图可知,2种算法均是从左侧并行输入8个数据,计算分为3个阶段,每个阶段都需要23次加法和0.5×23次乘法,计算结果从右侧并行输出。
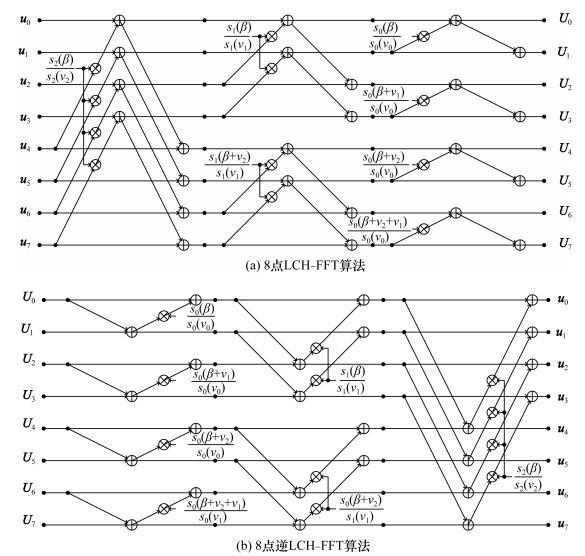
以下性质对于RS编码和译码至关重要。
定理1[6]:若$ \boldsymbol{U}=\mathrm{FFT}_{\overline{\mathbb{X}}}(\boldsymbol{u}, \ell, \beta)$ , 其中长度为2ℓ的u和U可分别写为
这里每个子向量ui和Ui的长度均为2b,0≤b≤ℓ,则下式成立:
2 RS码及其译码算法
2.1 RS码的定义
一个在$ \mathbb{F}_{2^{m}}$ 上的(n, k)RS码(n≤2m)的定义为
其中J={j0, j1, …, j2m-n-1}{0, 1, …, 2m-1},集合中的元素可以任意选定,无需传输由J索引的(2m-n)个零元素,因此C(n, k)实际上是长度为n的码。码的纠错能力为$ t=\frac{n-k}{2}$ 。
可以对k个消息符号采用如下的方法进行编码。假设d0, d1, …, dk-1是待编码的消息符号,令u(ωpi)=di表示一组信息位置{pi: 0≤i≤k-1, pi∉J}上的信息符号。由于u(x)的次数小于2m-(n-k),u(x)可以被{u(ωi): i∈{p0, p1, …pk-1}∪J}唯一确定。码字中的其余符号可以通过对u(x)求值确定。
该码的定义可以视为RS码原始定义的推广[13]。
因此,码C(n, k)是C(2m, k+(2m-n))的缩短码,缩短是通过对C(2m, k+(2m-n))码中由J索引的(2m-n)个符号设为零并将其删除来实现的。
2.2 RS译码
设(C0, C1, …, C2m-1)=(u(ω0), u(ω1), …, u(ω2m-1)) ∈C(n, k)为对应某个u(x)的传输码字,令(E0, E1, …, E2m-1)为错误模式,则接收字表示为
其中Cj=Ej=Rj=0, j∈J。设r(x)表示度数小于2m的插值多项式,使得
定义错误位置多项式为
其中$ \mathcal{E}$ 是错误位置的集合,表示为
则有
上式可等价于
其中:
因此,存在某个$ q(x) \in \mathbb{F}_{2^{m}}[x]$ ,使得
其中deg(q(x))<deg(λ(x)),子空间多项式sm(x)可以写为[6]
将r(x)除以$ \bar{X}_{2^{m}-2^{\ell}}(x)$ ,可得
其中:s(x)是商,且deg(s(x))<2ℓ,r0(x)是余式,且deg(r0(x))<2m-2ℓ。将式(20)和式(21)代入式(19),可得
通过提取式(22)右侧的第二项,定义
由于式(22)的左侧项的次数小于(2m-2ℓ+degλ(x))且$ \operatorname{deg}\left(\bar{X}_{2^{m}-2^{\ell}}(x)\right)=2^{m}-2^{\ell}$ ,则存在deg(z(x))<deg(λ(x))。依据$ s_{\ell}(x)=\prod\limits_{i=0}^{n-k-1}(x- \left.\omega_{i}\right)$ ,其中n-k=2ℓ,得到关键方程为
其中deg(z(x))<deg(λ(x))。
当且仅当s(x)为零多项式时,接收到的字为码字。解释如下:基于式(21),当且仅当deg(r(x))<2m-2ℓ时,s(x)为零多项式。依照RS码的定义,有r(ωj)=0, j∈J。基于式(10)中码的定义,$ r(x) \in \mathbb{F}_{2^{m}}[x]$ ,当且仅当(r(ω0), r(ω1), …, r(ω2m-1))为C(n, k)的码字,使得deg(r(x))<2m-2ℓ,且r(ωj)=0, j∈J; n-k=2ℓ。因此,s(x)可以看作是伴随式。
求解关键方程得到λ(x)后,利用Chien搜索可以找到错误位置。为计算错误值,对式(19)进行求导,得到:
对于错误位置$ i \in \mathcal{E}$ ,下式成立:
因此,位置$ i \in \mathcal{E}$ 处的错误值为
错误值还可以通过以下方法计算。
情况1:若$ i \in \mathcal{E}$ 且i≥n-k,则基于式(23)和式(27),存在
对式(23)的等式两边求导,可得
情况2:若$ i \in \mathcal{E}$ 且i<n-k,基于式(27)和式(29),得到
3 基于LCH-FFT的RS编码器设计
本章将阐述2种编码算法以及相应的架构。第一种编码算法基于定理1,直接从给定的消息符号计算出校验符号,由此提出一种新的删除译码算法,并基于此算法推导出第二种编码算法。
2种编码均为系统编码方法,且复杂度均为O(n log2(n-k))。不同之处在于第一种编码选择的信息位置是连续的,因而可基于定理1实现;第二种编码选择的信息位置是任意的k个位置,主要为适配传统循环RS码的编码。
3.1 Ⅰ型编码器
该编码器基于定理1,其中n-k=2ℓ且FFT的大小为2ℓ。设$ u(x)=u_{0} \bar{X}_{0}(x)+u_{1} \bar{X}_{1}(x)+\cdots+ u_{2^{m}-1} \bar{X}_{2^{m}-1}(x){\rm{且}}\operatorname{deg}(u(x))<2^{m}-(n-k)$ ,根据码定义,对应的码字由下式给出:
基于定理1,得到
对于系统编码,可以选择任意p(0≤p<2m-ℓ),使得(Cp·2ℓ, Cp·2ℓ+1, …, Cp·2ℓ+2ℓ-1)作为校验符号。其余已知符号为消息符号和缩短的零(若有)。因此,校验符号可以计算为
基于式(33)的编码方法修改了文[6]中的方法,其中p=0,即(C0, C1, …, C2ℓ-1)为校验符号。关于p的选取,若|J|<n-k,即缩短符号的数量少于校验符号的数量,则可以令{0, 1, …, n-k-1}为校验位置。因此,基于式(28)和式(30),消息位置和校验位置的错误值可以分别计算。基于式(28),若|J|≥n-k,可令{0, 1, …, n-k-1}为缩短位置以便处于消息位置和校验位置的错误值可以统一依据式(28)计算。
基于式(33)的Ⅰ型编码器架构如图 4所示。图中实例化了(2m-ℓ-1)个IFFT模块,支持部分和完全并行输入。在这种设计中,所有的乘法器均为常数乘法器。IFFT模块被安排为部分并行输入激活或停用。对应于缩短符号的IFFT模块不需要实例化。
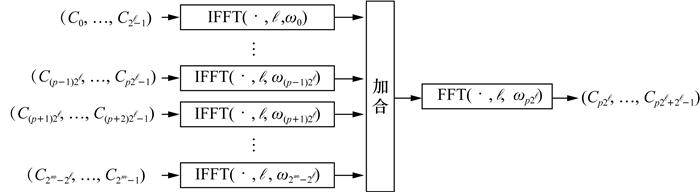
对于部分并行输入,另一种设计是实例化一定数量的IFFT模块以匹配输入吞吐量。每个IFFT模块执行具有不同β的IFFT(·, ℓ, β)计算。因此,IFFT模块中的乘法器是通用的。上述2种设计可能在面积和功耗消耗之间实现不同的权衡。
3.2 Ⅱ型编码器
基于LCH-FFT的纠错译码算法的推导过程(详见2.2节)表明其可用于纠删译码。为此设置Ri=0, $ i \in \mathcal{E}$ 。若$ |\mathcal{E}| \leqslant n-k$ ,即擦除的数量小于或等于校验的数量,存在一个唯一的码字,其与接收到的字在最多(n-k)个位置上不同。因此,译码算法可以唯一确定u(x)和q(x)。相应地,可以恢复传输的码字。
设:
则式(21)可推导出:
其中第二个等号的成立是基于定理1。之后可计算得
设$ z(x)=z_{0} \bar{X}_{0}(x)+z_{1} \bar{X}_{1}(x)+\cdots+z_{t-1} \bar{X}_{t-1}(x)$ ,基于式(24)得到
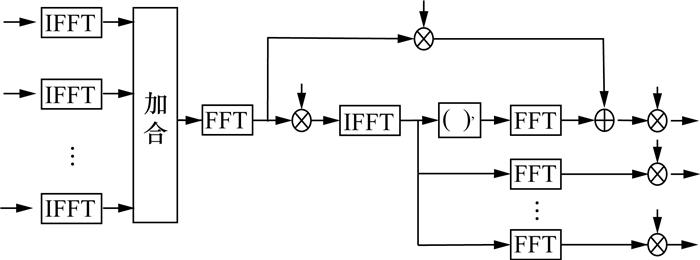
本研究提出了一种新的RS纠删译码算法,如图 5所示。初始化步骤为计算$ \left\{\lambda\left(\omega_{i}\right): i \notin \mathcal{E}\right\}$ 和$ \left\{\lambda^{\prime}\left(\omega_{i}\right): i \in \mathcal{E}\right\}$ ,基于快速Walsh-Hadamard变换,这可以以O(2mlog2(2m))的复杂度执行。其他步骤的总体复杂度为O(2mlog2(2ℓ))。形式导数$ z^{\prime}(x) =z_{0}^{\prime} \bar{X}_{0}(x)+z_{1}^{\prime} \bar{X}_{1}(x)+\cdots+z_{2^{\ell}-1}^{\prime} \bar{X}_{2^{\ell}-1}(x)$ 可以依据O(2ℓlog2(2ℓ))的复杂度计算[7]。

编码方面,考虑将k个消息符号和(2m-n)个缩短符号作为正确接收的符号,(n-k)个校验符号作为擦除符号。消息符号和校验符号的位置可以任意选择。由于校验位置集合是固定的,初始化步骤可以提前完成,因此对编码复杂度没有贡献。Ⅱ型编码器架构如图 6所示。
4 基于LCH-FFT的RS译码器设计
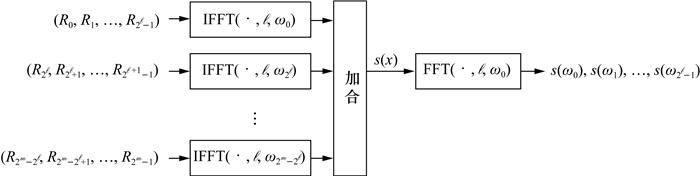
4.1 伴随式计算
伴随式计算(syndrome computation,SC) 模块计算频域伴随式向量(s(ω0), s(ω1), …, s(ω2ℓ-1))。类似于删除译码的推导,得到:
4.2 关键方程求解器
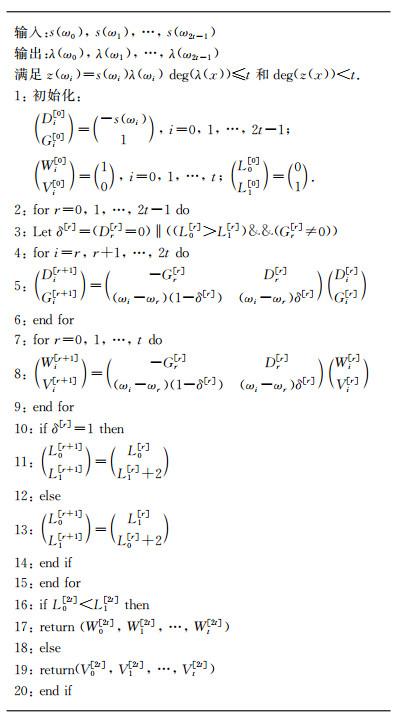
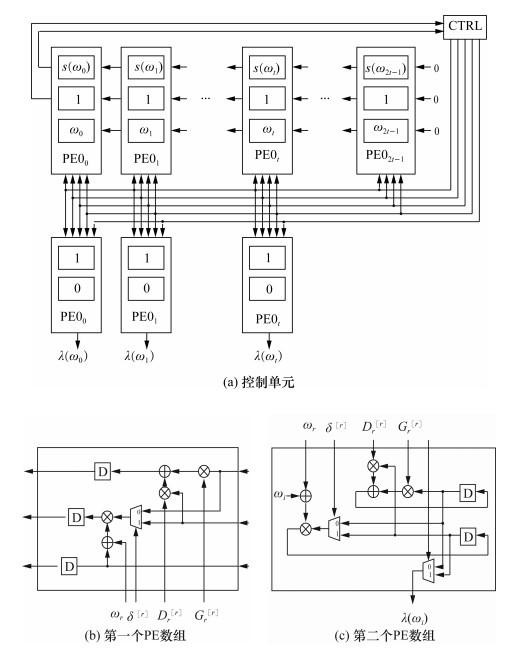
由于(Di[r], Gi[r])和(Wi[r], Vi[r])有相同的更新规则,此处使用异构设计,利用2个不同的PE结构实现更新。这主要基于如下考虑:
1) 将Dr[r]和Gr[r]作为广播信号输出,更新后的Di[r]和Gi[r]向左移动,以便Dr[r]和Gr[r]总是可以从最左边的PE0中取出。该设计可消除关键路径中选择Dr[r]和Gr[r]的电路,因此可改善关键路径。
2) 更新后的Wi[r]和Vi[r]不向左移动,而是留在原地,因此可节省功耗。
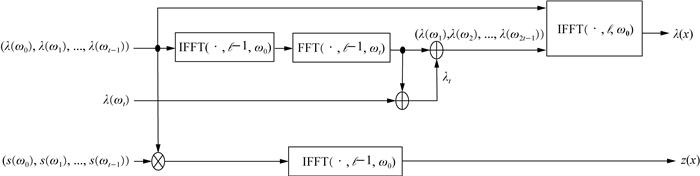
给定(λ(ω0), λ(ω1), …, λ(ωt)),λ(x)=$ \lambda_{0} \bar{X}_{0}(x)+\lambda_{1} \bar{X}_{1}(x)+\cdots+\lambda_{t} \bar{X}_{t}(x)$ 可计算为
基于定理1,存在:
通过在等式两边应用$ \mathrm{FFT}_{\overline{\mathbb{X}}}\left(\cdot, \ell-1, \omega_{t}\right)$ 得到:
式(40)中的λt被计算为右侧向量的第一个分量,其中λ(ω0), λ(ω1), …, λ(ωt)为已知。给定λt,利用式(40)计算(λ(ωt+1), …, λ(ω2ℓ-1))。接着可基于式(38)计算λ(x)。
进而,$ z(x)=z_{0} \bar{X}_{0}(x)+z_{1} \bar{X}_{1}(x)+\cdots+ z_{t-1} \bar{X}_{t-1}(x)$ 可计算为
λ(x)和z(x)的计算架构如图 10所示。
4.3 Chien搜索和错误评估
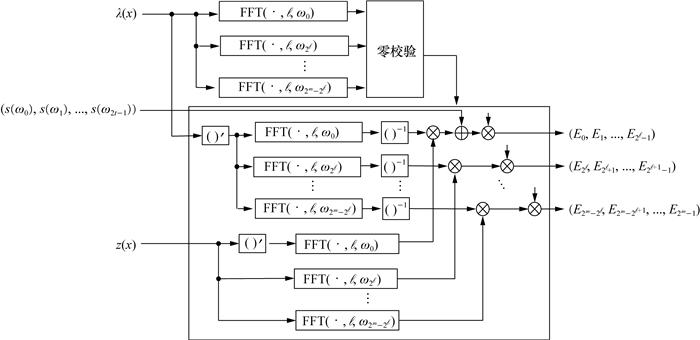
Chien搜索旨在找到λ(x)的根,这可通过首先计算式(42)然后检查哪些分量为零来实现。
Chien搜索和错误计算(Chien search and error evaluation,CSEE)模块的架构如图 11所示,FFT模块的实例化方式与编码器中的IFFT模块相同。
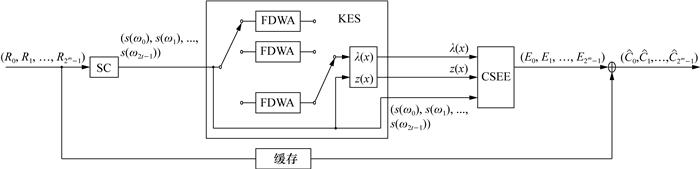
4.4 译码器的整体架构
将上述设计的SC、KES和CSEE集成到一个整体架构中,如图 12所示。这3个模块以流水线方式操作。为了匹配SC模块的输出速率,可以在KES模块中实例化多个FDMA模块。SC和KES之间的接口为频域伴随式(s(ω0), s(ω1), …, s(ω2t-1))。KES和CSEE之间的接口包括λ(x),z(x)和(s(ω0), s(ω1), …, s(ω2t-1))。
5 传统循环RS码的适用性证明
本节将证明基于LCH-FFT的编码方法可以应用于传统循环RS码。此处以本原循环RS码为例展开论述,相关证明结果可扩展至缩短的RS码和单扩展RS码。
本原循环RS码的码字可视为具有一组连续零频率分量的时域向量。令c(x)=c0+c1x+…+cn-1xn-1为向量(c0, c1, …, cn-1)的多项式表示。设$ \alpha \in \mathbb{F}_{2^{m}}$ 为一个本原元。$ \mathbb{F}_{2^{m}}$ 上的(n(n=2m-1), k)RS码可定义为
由于{α0, α1, …, α2m-2}={ω1, …, ω2m-1}=$ \mathbb{F}_{2^{m}} \backslash\{0\}$ ,此处定义一个置换:
使得向量(c0, c1, …, c2m-2)满足
由此获得定理2。
定理2:当且仅当(0, Per(α0c0, αbc1, …, α2m-2bc2m-2))∈C(2m-1, k)时$ \left(c_{0}, c_{1}, \cdots, c_{2^{m}-2}\right) \in \mathcal{R}_{\left(2^{m}-1, k\right)}$ ,其中J={0}体现在C(2m-1, k)的式(10)中。
证明:通过重写$ \mathcal{R}_{\left(2^{m}-1, k\right)}$ 为
将每个码字视为频域向量。定义集合
设$ f(x)=f_{0}+f_{1} x+\cdots+f_{2^{m}-2} x^{2^{m}-2} \in \mathbb{F}_{2^{m}}[x]$ 和$ F(x)=F_{0}+F_{1} x+\cdots+F_{2^{m}-2} x^{2^{m}-2} \in \mathbb{F}_{2^{m}}[x]$ 是一对Fourier变换则根据文[1]存在
其中第一个等号的成立是基于Fourier变换的平移性质[1]。
考虑由式(10)定义的RS码C(2m-1, k),其中J={0},
通过设置u(x)=xf(x),使得deg(f(x))<k,由此可见$ \left(f\left(\alpha^{0}\right), f\left(\alpha^{\prime}\right), \cdots, f\left(\alpha^{2^{m}-2}\right)\right) \in \mathcal{T}_{\left(2^{m}-1, k\right)}$ 当且仅当$ \left(0, \omega_{1} f\left(\omega_{1}\right), \cdots, \omega_{2^{m}-1} f\left(\omega_{2^{m}-1}\right)\right) \in \mathcal{C}_{\left(2^{m}-1, k\right)}$ 时成立。因此,$ \left(c_{0}, c_{1}, \cdots, c_{2^{m}-2}\right) \in \mathcal{R}_{\left(2^{m}-1, k\right)}$ 当且仅当$ \left(0, \operatorname{Per}\left(\alpha^{0} c_{0}, \alpha^{b} c_{1}, \cdots\right.\right.$ ,$ \left.\left.\alpha^{\left(2^{m}-2\right) b} c_{2^{m}-2}\right)\right) \in \mathcal{C}_{\left(2^{m}-1, k\right)}$ 时成立。
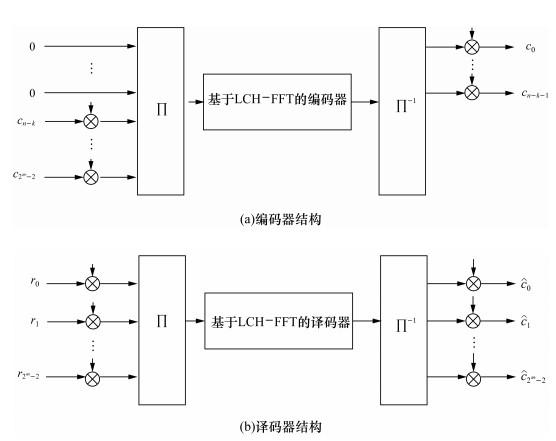
基于定理2,本文提出了一种用于本原循环RS码的高效编码器和译码器结构,如图 13所示。由图可知,内部的LCH-FFT编码器和译码器在长度为2m的码字上运行。对于缩短码,这可能在一定程度上削弱了其相对于在长度为n的码字上操作的常规设计的优势。此外,LCH-FFT编码器和译码器可以通过利用部分输入的零符号进行优化。
6 RS(544, 514)的FPGA实现
基于图 13给出的硬件架构方案,在Vivado平台上使用Verilog HDL语言进行编程,并对系统进行功能仿真以及资源评估,然后将其与传统的RS码编译码器做对比。所有测试均在Xilinx公司的XCVU9P-L2FLGA2104E芯片上做上板实测,并验证误码率性能。
不同并行度下RS编码器的资源评估结果如表 2所示。括号中的百分数表示LCH-FFT的RS编码器的顶层模块消耗的查找表(look up table,LUT)资源,与同并行度下的传统RS编码器相比降低的比例。由表可知,与同并行度的传统RS编码器相比,基于LCH-FFT的RS编码器模块所消耗的LUT资源更少;且并行度越大,资源优势越明显。并行度为32时LUT数减少了18.13%;并行度为128时LUT数减少了35.86%,全并行时则减少了66.24%,这与前人理论[9]相符。此外,在实现FFT和IFFT运算时为了保证较短的关键路径,无论并行度为多少,基于LCH-FFT的RS编码器都需要更多的寄存器用于打拍。
表 2 各并行度下编码器的资源评估结果 |
| 编码器类型 | 并行度 | LUT数 | 寄存器数 |
| 传统的RS编码器 | 32 | 7 408 | 627 |
| 128 | 27 370 | 2 264 | |
| 全并行 | 93 494 | 10 582 | |
| 基于LCH-FFT的RS编码器 | 32 | 6 065(18.13%) | 1 959 |
| 128 | 17 554(35.86%) | 5 125 | |
| 全并行 | 31 562(66.24%) | 18 926 |
不同并行度下RS译码器的资源评估结果如表 3所示。括号中的百分数表示LCH-FFT的RS译码器的顶层模块消耗的LUT资源,与同并行度下的传统RS译码器相比降低的比例。由表可知,与传统的RS译码器相比,基于LCH-FFT的RS译码器在低并行度时并没有取得资源上的收益,甚至是负收益(32路并行译码器的LUT数比传统译码器的LUT数多17.66%)。这一方面是因为基于LCH-FFT的RS译码器关键方程的形式已经改变,不再适用于资源更少的RiBM架构,另一方面是因为基于LCH-FFT的ChienEC模块更加复杂,多出来的这部分资源在低并行度时无法被采用FFT进行多点估值节省的资源抵消。但随着并行度的进一步提高,基于LCH-FFT的RS译码器的资源收益开始显现,且并行度越高,LUT资源的收益越明显。并行度为128时,LUT数减少了22.62%,全并行时更是减少了46.39%。这是因为随着并行度的提高,基于FFT的多点估值在资源上的优势越来越明显,这使得Syndrome模块和ChienEC模块的资源收益也越来越明显。因此高并行度时,虽然KES模块由于无法采用RiBM架构而使计算复杂度增加,但Syndrome模块和ChienEC模块由于采用FFT进行多点估值促使了计算复杂度的显著降低,因此基于LCH-FFT的RS译码器的总体计算复杂度比传统的RS译码器要低很多,且并行度越高,计算复杂度的优势越明显。此外,在实现FFT和IFFT运算时为了保证较短的关键路径,需要更多的寄存器用于打拍。
表 3 各并行度下译码器的资源评估结果 |
| 传统的RS译码器 | 基于LCH-FFT的RS译码器 | |||||||
| 并行度 | 模块名 | LUT数 | 寄存器数 | 并行度 | 模块名 | LUT数 | 寄存器数 | |
| 32 | Decoder(顶层) | 30 313 | 4 723 | 32 | Decoder(顶层) | 35 665(-17.66%) | 8 747 | |
| Syndrome | 8 696 | 306 | Syndrome | 6 093 | 1 624 | |||
| KES | 10 312 | 1 988 | KES | 14 215 | 3 161 | |||
| ChienEC | 10 975 | 2 093 | ChienEC | 15 333 | 3 541 | |||
| 128 | Decoder(顶层) | 142 785 | 14 786 | 128 | Decoder(顶层) | 110 481(22.62%) | 23 536 | |
| Syndrome | 46 503 | 304 | Syndrome | 15 876 | 2 576 | |||
| KES | 36 472 | 6 940 | KES | 46 269 | 9 705 | |||
| ChienEC | 58 522 | 6 248 | ChienEC | 48 314 | 9 899 | |||
| 全并行 | Decoder(顶层) | 559 879 | 31 642 | 全并行 | Decoder(顶层) | 300 129(46.39%) | 66 127 | |
| Syndrome | 200 187 | 2 516 | Syndrome | 27 916 | 15 708 | |||
| KES | 189 513 | 14 876 | KES | 207 735 | 43 197 | |||
| ChienEC | 164 731 | 13 210 | ChienEC | 59 315 | 1 713 | |||
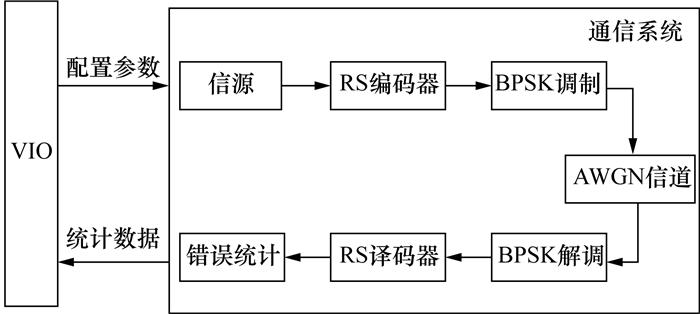
为了验证基于LCH-FFT的RS编译码器在FPGA上的误码性能,本文利用Vivado平台上的可定制IP核虚拟输入输出(virtual input output,VIO)对FPGA内部的信号进行实时的驱动和监视。系统的测试平台如图 14所示。由图可知,首先由VIO配置AWGN信道的方差,同时VIO给出开始信号控制信源产生伪随机序列,信源模块由串行的移位寄存器构成。之后信号经过RS编码器、BPSK调制、AWGN信道、BPSK解调、RS译码器以及错误统计模块后,将统计的信息传回VIO并实时显示,其中AWGN信道是通过Box-Muller方式产生噪声的。
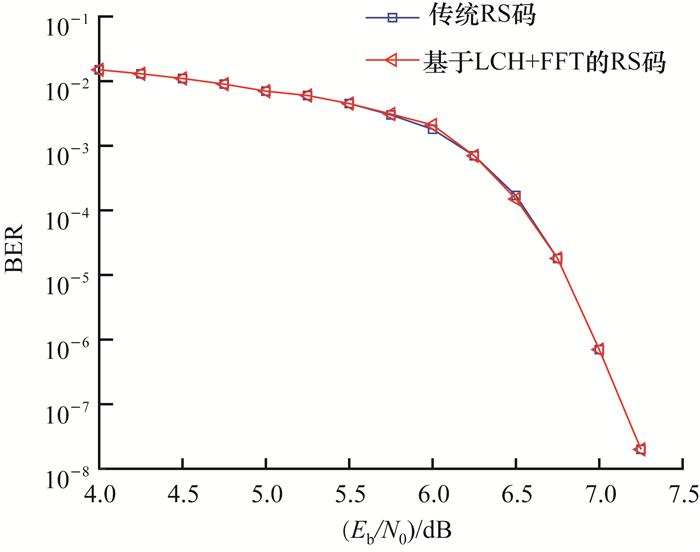
根据不同信噪比(Eb/N0)下VIO上抓取的统计数据计算误比特率并绘制误码率(bit error rate,BER)性能曲线。2种RS编译码器的通信系统的BER性能对比如图 15所示。图中每个信噪比下都测试了不少于100帧错误。由图可知,2条实测曲线基本吻合,这说明本文设计的基于LCH-FFT的编译码器能够正常工作,在不损失BER性能的基础上能够有效降低硬件实现的资源。
7 结论
基于LCH-FFT,本文设计了2种RS码系统编码器架构(Ⅰ型编码器和Ⅱ型编码器)和一种新的译码器架构;为FDMA算法设计了一种脉动阵列架构来解决关键方程。经证明,本文所提方法可对基于LCH-FFT的编译码方法进行预处理和后处理,也可以对常用的循环RS码(包括缩短码和单扩展码)实施快速编译码。基于FPGA的实现表明,基于LCH-FFT的编译码器非常适合高并行实现,未来有望在高速场景中实现关键性的应用。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}