

火灾是一种破坏力极大的灾害,研究火灾监测技术是防范和控制早期火灾,降低人员和财产损失的有效措施之一。随着深度学习领域的快速发展,目标检测方法在火灾监测中比传统方法展现了明显的成本和技术优势。
深度学习、卷积神经网络(convolutional neural networks, CNN)等概念的提出,为研究更加精确、高效的目标检测方法提供了新的理论基础[1]。目前,深度学习技术在目标检测领域主要有2种方法:二阶段目标检测和单阶段目标检测。前者的运算速度低于后者,但其准确度优于后者。
本文针对YOLOv5算法在小目标场景下预测能力较弱的问题,构建了一种基于改进YOLOv5算法的火灾目标检测模型YOLOv5s-SSS(swin transformer with soft-NMS for small target),对多尺度、密集分布条件下的小目标火焰图像检测模型展开研究。
1 数据集制备与再划分
1.1 数据集构建
1.2 数据集再划分

为了进一步测试模型在不同场景中的泛化性能,本研究对测试集进行了4次再划分,设置了4对环境条件互斥(不良照度-适宜照度、航拍视角-地面视角、室内环境-室外环境、林草火灾-其他火灾)的8组子数据集,子数据集的特征信息如表 1所示。
表 1 验证集子数据集特征信息 |
| 互斥环境条件组 | 数据比例 |
| 不良照度-适宜照度 | 238张(30.6%)∶540张(69.4%) |
| 航拍视角-地面视角 | 86张(11.1%)∶692张(88.9%) |
| 室内环境-室外环境 | 22张(2.8%)∶756张(97.2%) |
| 林草火灾-其他火灾 | 373张(47.9%)∶405张(52.1%) |
2 YOLOv5s-SSS模型
2.1 模型概述
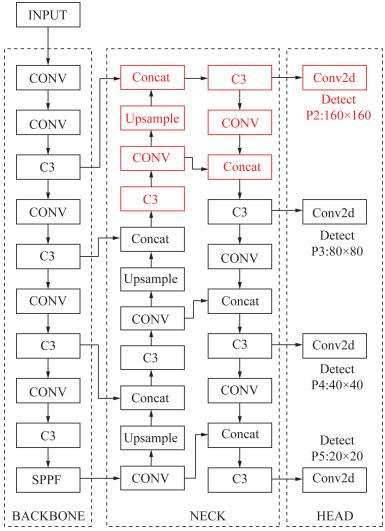
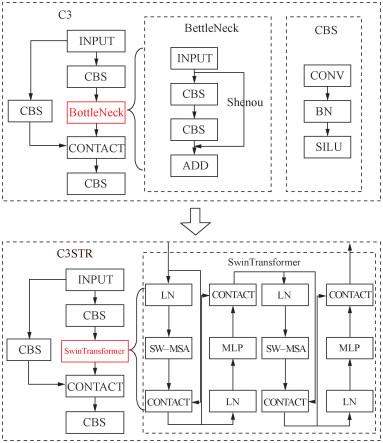
本研究对比了多种目标检测技术改进方案,结合火灾图像早期火焰目标尺寸小、分布密集等特点和YOLOv5算法分辨率欠缺、细节提取能力弱、密集目标预测效果不佳等问题,提出了基于YOLOv5算法的火灾目标检测模型YOLOv5s-SSS(swin transformer with soft-NMS for small target)。本研究选取YOLOv5算法下的轻量版本模型YOLOv5s,以该模型的基础代码集成实现改进方案,主要针对算法的输出端结构、骨干网络模块以及后处理损失函数3个方面进行改进。YOLOv5s-SSS模型的总体架构如图 2所示,主要改进结构由红框标出。由图可知,在输出端,YOLOv5s-SSS模型将YOLOv5s模型多尺度检测层的3层结构拓展为4层结构,将骨干网络底层的2个C3模块嵌入swin transformer模块[15]后得到C3STR模块;将损失函数由原本的NMS(non maximum suppression)改进为soft-NMS [16]。以下针对3方面的改进进行逐一介绍。
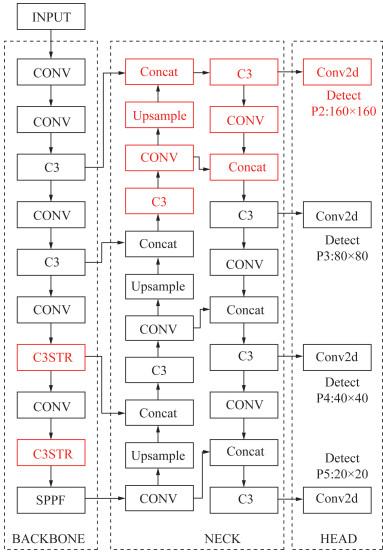
2.2 拓展多尺度检测层
早期火灾发生时,火焰在采集到的图像中常以小目标的形式呈现。YOLOv5s模型一般将输入图像的尺寸统一转化为640像素×640像素后输入模型,经多次卷积处理提取特征后,即使分辨率最高的检测头也对图像进行了8倍下采样,这表明YOLOv5算法很难在图像内尺寸小于或接近8像素×8像素的目标上提取到有效的特征信息,导致漏检问题。
为解决此问题,本研究在YOLOv5s模型的多尺度检测层结构中添加了一个4倍下采样探测头,可额外得到尺寸为160像素×160像素的微小尺度感受野特征图,提升感受野分辨率,以支撑小目标火焰图像检测。本文将新增的探测头依照结构原有顺序命名为P2,添加P2检测头后的YOLOv5s模型整体网络结构如图 3所示,主要改进结构由红框标出。
2.3 嵌入swin transformer模块
在早期火灾中,受风向、可燃物等条件影响,图像中小目标场景火焰常伴随相似尺寸甚至相对尺寸偏大的火焰的出现,存在火焰形状与颜色特征单一、火焰大小不一的特点,常出现漏检、目标分割紊乱等问题,为密集分布和多尺度检测带来挑战。
注意力模块对处理密集分布预测任务和提升模型多尺度特征提取能力有一定作用,本研究将swin transformer模块嵌入YOLOv5s模型的C3模块中。swin transformer模块是一种注意力模块,由Liu等[15]于2021年提出,其主要思路为以分层级的方式设置不同尺寸的感受野,以解决目标尺度差异较大与固定的检测头感受野之间的矛盾;利用滑动窗口遍历图像,将自注意力计算限制于不重叠的窗口之中以减少计算量。
2.4 优化后处理函数
早期火灾图像往往呈现出火点密集分布、图像堆叠遮挡等问题,在野外火灾中,由于可燃物分布较为集中,这一现象更为显著。YOLOv5s模型使用的后处理函数是NMS算法,其会将模型为目标生成的邻近置信度较低的预测框全部置零删除,当目标密集分布或遮挡重叠出现时,使用YOLOv5s模型可能会带来较大的漏报率,邻近的火焰目标易被漏检。
适合的损失函数能帮助模型在训练中更高效地实现收敛,提升检测准确率。2017年,Navaneeth等[16]基于NMS算法改进出soft-NMS算法。soft-NMS算法在处理重叠预测框时与NMS算法不同,其可根据各预测框与最佳预测框的距离,赋予各预测框一个较低的分数进行再次判断,通过循环逐步降低重复框的置信度直至被剔除,从而更多地保留可能存在的重叠目标预测框,更准确且低冗余地检测目标位置。这与本研究提升小目标场景火灾的精确率的目标相符,因此本研究将YOLOv5s模型的NMS算法替换为soft-NMS算法。
3 实验与验证
3.1 实验环境配置
实验运行环境配置情况如下:图形处理器为NVIDIA GeForce RTX 4060 Laptop GPU,显存为8 GB;中央处理器为AMD Ryzen 97945HX,内存为16 GB;操作系统为Windows 11;编译环境为Python 3.8.19,PyTorch 2.2.1,CUDA 11.8。代码运行参数配置情况如表 2所示。
表 2 代码运行参数配置 |
| 参数名称 | 实验配置 |
| 初始学习率 | 0.01 |
| 迭代次数 | 300次 |
| 批次大小 | 4张 |
| 优化器 | SGD |
| 无增长提前终止轮数 | 100轮 |
| 网络输入尺寸 | 640像素×640像素 |
3.2 评价指标
为方便定义各指标,将检测目标分为正样本和负样本,若正样本被正确识别为正样本则称为真阳性(true positives,TP),若正样本被错误识别为负样本则称为假阴性(false negatives,FN),即漏检;若负样本被正确识别为负样本则称为真阴性(true negatives,TN),若负样本被错误识别为正样本则称为假阳性(false positives,FP),即错检。各指标的定义如下:
1) 精确率P,表示被预测为正样本的结果中真正是正样本的比例,计算公式为
2) 召回率R,表示被预测为正样本的结果中预测正确的占所有实际为正样本的比例,计算公式为
其中:TP、FP、FN分别为真阳性、假阳性、假阴性的样本数。
P和R具有较强的相关性,绘制P-R曲线可以直观展现二者关系。在理想条件下,P和R均接近于1时表明模型的精确率高、漏检率低。
3) 平均精确率AP,表示在不同R条件下P的均值,数值上对应为P-R曲线的面积积分,表示正确预测某一类目标的概率(精确率)。
4) 平均AP值mAP,表示所有预测类别的AP的平均值,反映了整个模型的检测效果。
3.3 消融实验
本研究首先设计了4组消融实验,用于测试提出的3方面改进对模型AP值的提升效果。下文将拓展多尺度检测层简称为改进a、嵌入swin transformer模块简称为改进b、优化后处理函数简称为改进c,对消融实验过程和结果进行分析。
由于实验数据集中各场景包含的小目标主要为火焰图像目标,故以下实验主要以火焰图像目标检测的平均精确率AP2作为比较标准,以烟雾图像目标检测的平均精确率AP1和模型的mAP作为模型对正常尺寸目标检测能力的参考标准。
针对改进a,本文以YOLOv5s模型为对照组,添加P2检测头后的YOLOv5s模型作为实验组,由表 3可知,添加P2检测头后,模型的AP2较YOLOv5s模型提升了0.3%。
表 3 检测层消融实验结果 |
| 实验方案 | AP1(烟雾) | AP2(火焰) | mAP |
| YOLOv5s | 0.343 | 0.186 | 0.264 |
| YOLOv5s+P2检测头 | 0.325 | 0.189 | 0.257 |

表 4 模块消融实验结果 |
| 实验方案 | AP1(烟雾) | AP2(火焰) | mAP |
| YOLOv5s | 0.343 | 0.186 | 0.264 |
| 在特征融合网络(NECK)中替换Biformer [17] | 0.352 | 0.170 | 0.261 |
| 在骨干网络(BACKBONE)中替换Biformer [17] | 0.313 | 0.171 | 0.242 |
| 在全网络替换C2f [18] | 0.336 | 0.180 | 0.258 |
| 在特征融合网络(NECK)中替换C2f [18] | 0.354 | 0.176 | 0.265 |
| 在骨干网络(BACKBONE)中替换C2f [18] | 0.334 | 0.184 | 0.259 |
| 在骨干网络(BACKBONE)中替换swin transformer[15] | 0.341 | 0.209 | 0.275 |
各类改进所得模型的预测效果如图 6所示,红色虚线框为本组实验用于预测效果对比的火焰目标,红色实线框为模型预测的烟雾目标;粉色实线框为模型预测的火焰目标;Real为火焰、烟雾目标真值分布情况;fire 0.42表示模型预测该目标为“火焰”的置信度为0.42,smoke 0.48表示模型预测该目标为“烟雾”的置信度为0.48,依此类推。由图可知,嵌入swin transformer模块后,模型对目标的漏检率更低,且定位范围更加精确。

针对改进c,本研究选取了2种目前针对小目标数据集的后处理函数,并直接以模块优化后的最优实验结果作为对照组展开消融实验,结果如表 5所示。由表可知,将后处理函数替换为soft-NMS算法后,模型在小目标火焰图像目标检测上的性能表现以及整体性能都有较大幅度的提升,AP2比未改进的YOLOv5s模型增长了13.1%。该函数的工作特点与实验数据集中大量存在的密集分布小型火源点的特征十分契合,因此可实现密集分布和多尺度火焰目标检测精确率的提升。

为验证YOLOv5s-SSS模型的整体改进效果,本文以YOLOv5s模型作为对照组,以改进a、改进a+改进b、改进a+改进b+改进c作为实验组开展消融实验,结果如表 6所示。由表可知,随着改进方面的增多,改进方案的AP2相对于YOLOv5s模型AP2的增长值逐步上升,且改进c对YOLOv5s-SSS模型性能提升起主要作用。最终得到的YOLOv5s-SSS模型在各方面的AP均明显优于YOLOv5s模型,AP2提升了15.3%,证明了本研究改进方案是有效的。
表 6 整体改进消融实验结果 |
| 实验方案 | AP1(烟雾) | AP2(火焰) | mAP |
| YOLOv5s(无改进) | 0.343 | 0.186 | 0.264 |
| YOLOv5s+改进a | 0.325 | 0.189 | 0.257 |
| YOLOv5s+改进a+改进b | 0.321 | 0.208 | 0.264 |
| YOLOv5s+改进a+改进b+改进c(YOLOv5s-SSS) | 0.403 | 0.339 | 0.371 |
3.4 YOLOv5s-SSS模型性能实验
首先,通过调整参数使模型达到最佳性能。依据实验数据集特点,参数调优围绕模型的iou阈值展开,本组实验赋予YOLOv5s模型和YOLOv5s-SSS模型一组相同的iou阈值,通过输出的数据观测模型性能。由表 7可知,当iou阈值达到0.20后,YOLOv5s-SSS模型相对YOLOv5s模型AP2的增长值不再变化,且此时YOLOv5s-SSS模型对于正常尺寸目标对象的检测能力相对抑制程度较小,相对YOLOv5s模型的AP2提高了16.3%,整体性能表现更佳。因此,本研究选择iou阈值为0.20条件下的YOLOv5s-SSS模型作为最终改进方案。
表 7 参数调优实验结果 |
| iou阈值 | 测试模型 | AP1(烟雾) | AP2(火焰) | mAP |
| 0.60 | YOLOv5s | 0.343 | 0.186 | 0.264 |
| YOLOv5s-SSS | 0.403 | 0.339 | 0.371 | |
| 0.40 | YOLOv5s | 0.352 | 0.227 | 0.290 |
| YOLOv5s-SSS | 0.402 | 0.346 | 0.374 | |
| 0.30 | YOLOv5s | 0.340 | 0.240 | 0.290 |
| YOLOv5s-SSS | 0.402 | 0.346 | 0.374 | |
| 0.20 | YOLOv5s | 0.320 | 0.247 | 0.283 |
| YOLOv5s-SSS | 0.402 | 0.349 | 0.376 | |
| 0.10 | YOLOv5s | 0.309 | 0.248 | 0.278 |
| YOLOv5s-SSS | 0.402 | 0.349 | 0.376 | |
| 0.05 | YOLOv5s | 0.307 | 0.249 | 0.278 |
| YOLOv5s-SSS | 0.402 | 0.349 | 0.376 |
表 8 互斥环境条件对比实验结果 |
| 组别设置 | 子数据集名称 | AP1(烟雾) | AP2(火焰) | mAP |
| 实验组一 | 不良照度 | 0.419 | 0.317 | 0.368 |
| 适宜照度 | 0.411 | 0.355 | 0.383 | |
| 实验组二 | 航拍视角 | 0.401 | 0.391 | 0.396 |
| 地面视角 | 0.403 | 0.336 | 0.370 | |
| 实验组三 | 室内环境 | 0 | 0.400 | 0.200 |
| 室外环境 | 0.401 | 0.338 | 0.369 | |
| 实验组四 | 林草火灾 | 0.368 | 0.344 | 0.356 |
| 非林草火灾 | 0.434 | 0.336 | 0.385 | |
| 对照组 | 基线数据集 | 0.403 | 0.339 | 0.371 |
注:基线数据集为1.2节中构建的完整的小目标火焰图像数据集。 |
3.5 可视化验证
本研究通过设计可视化评价实验为模型性能补充定性评价。以改进a、改进a+改进b、改进a+改进b+改进c作为实验组,针对一组相同的图像进行检测,获得带有预测框的检测结果,直观对比不同模型在林草火灾、不良照度、航拍视角和室内环境等条件下的检测性能。结果如表 9所示,红色虚线框为本组实验用于预测效果对比的火焰目标,红色实线框为模型预测的烟雾目标;粉色实线框为模型预测的火焰目标;fire 0.39表示模型预测该目标为“火焰”的置信度为0.39,smoke 0.30表示模型预测该目标为“烟雾”的置信度为0.30,依此类推。
表 9 可视化评价结果 |
| 工作条件 | 模型种类 | |||
| YOLOv5s | YOLOv5s+改进a | YOLOv5s+改进a+改进b | YOLOv5s+改进a+改进b+改进c | |
| 1-适宜照度的林草火灾 |  |  |  |  |
| 2-不良照度的非林草火灾 |  |  |  |  |
| 3-航拍视角的林草火灾 |  |  |  |  |
| 4-不良照度的室内火灾 |  |  |  |  |
注:fire 0.39表示模型预测该目标为“火焰”的置信度为0.39,smoke 0.30表示模型预测该目标为“烟雾”的置信度为0.30,依此类推。拓展多尺度检测层简称为改进a、嵌入swin transformer模块简称为改进b、优化后处理函数简称为改进c。 |
由表 9可知,在第1类工作条件下,本研究提出的YOLOv5s-SSS模型在适宜照度的林草火灾监测任务中,能够更为清晰全面地划分密集分布的火焰图像目标;在第2类工作条件下,YOLOv5s-SSS模型能够减少在不良照度下的非林草火灾监测任务中,密集分布小目标火焰图像目标的漏检现象;在第3类工作条件下,YOLOv5s-SSS模型能够使航拍视角的林草火灾监测任务中的小目标火焰图像的定位范围缩小;在第4类工作条件下,YOLOv5s-SSS模型能够缩小不良照度的室内火灾监测任务中火灾图像的定位范围。以上改进有利于提升火点精确定位、扑救方案设计等应用场景的工作效率。
将可视化验证结果与3.4节中参数调优实验结果进行对比,可以发现:YOLOv5s-SSS模型比YOLOv5s模型的AP2提升了16.3%,在常规尺寸烟雾图像上的AP1也提升了5.9%,但存在一定程度的漏检问题,对于混叠、低照度对象的处理解决也有待进一步提升。这可能是由于室内环境图像数据过少。
4 结论
火灾监测技术中现有的目标检测方法,针对以小尺寸图像形式出现的火灾早期火焰的识别能力不强,本研究提出一种基于改进YOLOv5的小目标火灾检测模型,并制备了测试该类任务检测效果的小目标火焰图像数据集。提出的YOLOv5s-SSS模型拓展了YOLOv5s模型的多尺度检测层以提升感受野分辨率;嵌入了swin transformer模块以提升模型多尺度特征提取能力并有效减少检测的整体计算量,使用了soft-NMS算法优化后处理函数以保留更多可能存在的重叠或邻近目标。
由消融实验和模型性能实验可知,本研究构建的YOLOv5s-SSS模型能有效提升YOLOv5算法在小目标火焰图像上的识别精确率,对小目标火焰图像的平均精确率提升了16.3%;对常规尺寸烟雾图像的平均精确率提升了5.9%。YOLOv5s-SSS模型比YOLOv5s模型在缩小火灾目标定位范围、减少小尺寸及密集分布火灾目标漏检和清晰划分密集或重叠分布火灾目标等方面表现出更优的效果,可为森林火灾的早期火点精确定位、大范围火灾遥感监测等的效率提升提供参考。
目前采用的测试集仅包含小目标火焰图像,因此模型总体准确率偏低,有待后续改进,以达到实际工业应用的要求。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}