

与传统图像数字处理相比,深度学习算法能自动适应复杂裂缝,避免了手工设计特征提取器,是计算机视觉的核心[8]。裂缝识别定位算法分为2类:基于区域卷积神经网络(region-based convolutional neural network,R-CNN)的两阶段算法,如Fast R-CNN、Faster R-CNN和Mask R-CNN等,通过区域网络生成目标候选区域,进行裂缝的分类和边界框回归,输出裂缝的类别和准确位置[9];基于你只看一次(You Only Look Once,YOLO)的单阶段算法,如YOLOv1至YOLOv8等版本,通过放弃区域提取步骤,将检测任务作为回归问题解决,直接获得图像中裂缝的位置和类别信息,提高裂缝识别效率,已广泛应用于裂缝识别领域[10]。Yu等[11]针对无人机无法实时监测桥梁裂缝的问题,提出了融合焦点损失和剪枝模型(focal loss and pruning model,FLPM)损失函数的YOLOv4-FPM深度学习模型,可在提高模型精度的同时降低模型大小和参数量,不仅能实时处理图像,还能识别不同尺寸的桥梁裂缝。Kumar等[12]提出一种基于边缘算法的YOLOv3模型,并部署在六轴无人机上,解决了超高层建筑损伤的实时识别问题,实现了超高层建筑外表面损伤的实时健康监测。Yang等[13]用W-PAN网络替换YOLOv5主干网络,通过GhostC3和ShuffleConv模块优化原有网络的C3和Conv模块,提高了沥青路面非变形病害检测的精度和速度。Teng等[14]基于YOLOv3深度学习算法,通过引入迁移学习模型和数据增强技术,提高模型的特征提取性能和鲁棒性,实现了桥梁表面裂缝和钢筋裸露在不同图像分辨率下的精确高效识别。Wu等[15]提出了一种改进的YOLOv8深度学习模型,该模型结合了轻量级主干网络和高效的原型掩膜分支,降低了模型的复杂度,并保持模型的精度不变,完成了对大坝和桥梁结构裂缝的实时像素级检测。有关学者已对YOLO算法进行了改进,结合无人机数据采集,满足了算法轻量化、准确率提升、复杂环境裂缝识别、实时处理的需求。无人机安全距离的限制和裂缝过小导致桥梁裂缝检测过程中的小目标特征信息提取困难,进而导致小目标裂缝被误检漏检,这为桥梁运营带来巨大的安全隐患。因此,需要一种算法对桥梁中的小目标裂缝进行准确识别。
本文在YOLOv8算法的基础上提出一种基于多尺度融合的EfficientVit-LSKNet-BiFPN-YOLOv8算法。首先,该算法用高效视觉变换器(efficient vision transformer, EfficientViT)替换YOLOv8主干网络,增强算法提取图像局部特征的能力;其次,引入大型选择性核网络(large selective kernel network, LSKNet)注意力机制,融合C2f模块,降低运行参数,减少计算复杂度;最后,利用双向特征金字塔网络(bidirectional feature pyramid network, BiFPN)融合P2小目标检测层,增加不同尺度特征图之间的信息耦合和小目标裂缝的检测头。该算法实现了对小目标特征信息的提取,提高了小目标裂缝检测的准确率。
1 裂缝智能检测算法
1.1 YOLOv8算法
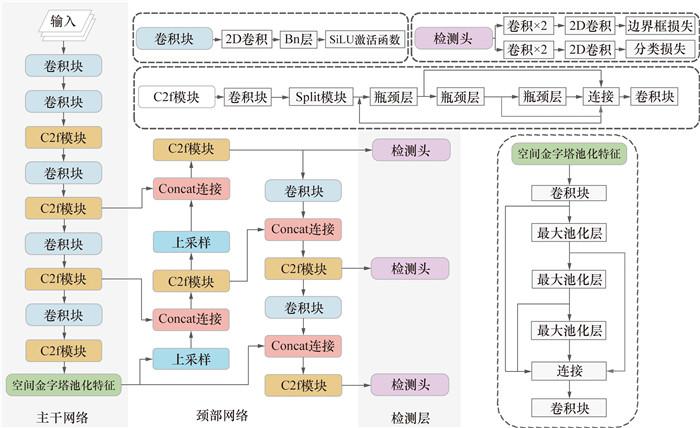
YOLOv8在Backbone部分使用了更强大的视觉主干网络,并使用梯度流更丰富的C2f替换原本的C3模块,以增强卷积神经网络的特征融合能力和推理速率[16];Neck采用了简洁高效的FPNLite,能较好地融合不同层次的语义和位置信息[16];Head使用了新的解耦头,将目标检测头从Anchor-Based变为Anchor-Free,同时将分类头和检测头分离[16];在数据增强部分,YOLOv8借鉴了YOLOX的方法,在最后10个训练过程中关闭Mosaic增强数据集,有助于提高模型的泛化能力和精度。YOLOv8的数据预处理依然采用YOLOv5的策略,同时采用Mixup、random_perspective和HSV这3种数据增强手段;YOLOv8改变了以往的交并比(intersection over union,IoU)匹配策略或者单边比例的分配方式,利用Task-Aligned Assigner动态分配和匹配样本[17];此外,YOLOv8目前有YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x等5个版本,可供相关研究人员在不同条件下使用。
1.2 改进网络优化
1.2.1 EfficientViT网络结构
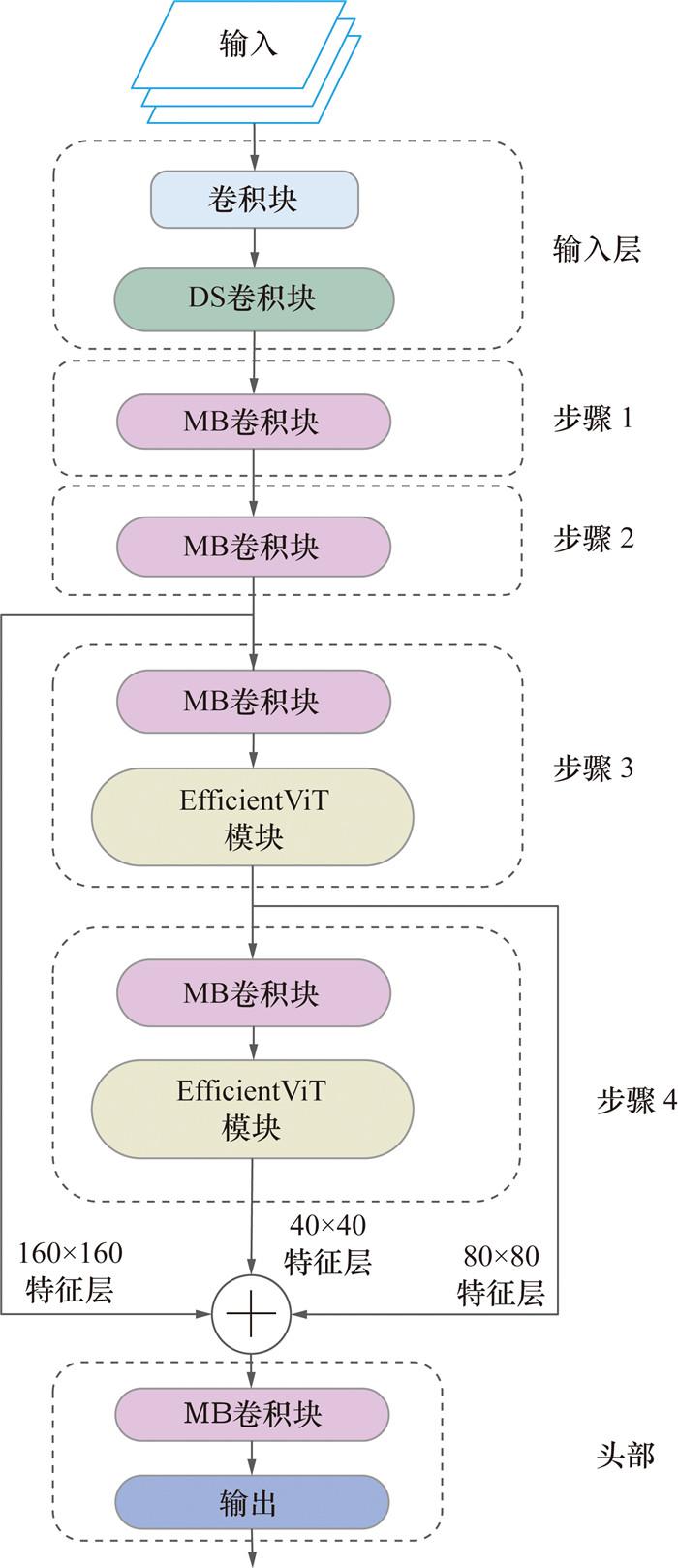
EfficientViT是Cai等[18]于2023年提出的一种在运算能力有限的设备上部署深度学习模型的轻量级多尺度线性主干网络,其结构如图 2所示。EfficientViT是一种高效的视觉Transformer模型,与传统的Transformer模型相比,视觉转换器(vision transformer,ViT)模型将Transformer模型的自注意力机制应用于计算机视觉任务,将任意大小和比例的图像划分成网格,并视为输入值,不必像卷积神经网络一样,必须输入固定尺寸的图像[19];在构架融合方面,EfficientViT采用backbone-head结构,并在backbone结构后期插入了轻量级多尺度注意力模块,用于捕获上下文信息,提供良好的上下文感知能力;在注意力机制方面,EfficientViT引入了基于修正线性单元(rectified linear unit,ReLU)的全局注意力机制,利用矩阵的关联性和ReLU全局注意力,将计算复杂度从二次关系降至线性关系,以减少计算冗余;在特征表示方面,EfficientViT用可学习的线性层生成特征图代替传统的图像编码过程,并与多尺度小卷积核和ReLU全局注意力结合,实现了多尺度特征学习;在主干网络方面,EfficientViT采用具有深度可分离卷积的移动翻转瓶颈卷积及其变种分布移位卷积等轻量级的卷积操作,可减少参数量,并保持可观的特征学习能力。
1.2.2 LSKNet注意力机制
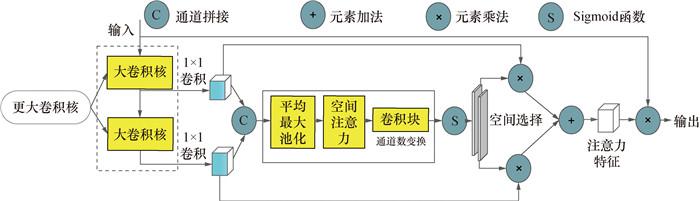
2023年,Li等[20]提出针对遥感图像目标检测任务的轻量级深度神经网络LSKNet,旨在通过调整大感受视野,适应遥感图像中不同的物体,其注意力机制结构如图 3所示。LSKNet基于自注意力机制和卷积核选择技术设计,可动态调整感受视野大小,并可针对性地捕获和建模遥感图像中目标周围复杂多样的背景信息。LSKNet采用大型可调卷积核,大大减少了网络参数,降低了计算复杂度,提高了在移动终端等资源受限环境下的实际应用的计算效率。LSKNet通过动态调整特征提取主干网络中的卷积核尺寸,并融合暗通道先验的传统去雾算法,提出了一种局部敏感关键点绝缘子图像去雾算法,显著提高了绝缘子目标检测的精确度。将LSKNet融合C2f注意力机制模块,弥补因非结构化环境造成的精度损失,选择性调整卷积核尺寸,降低运行参数,并减少计算复杂度,提高YOLOv8算法注意力机制的运行效率。
1.2.3 BiFPN融合P2小目标检测层
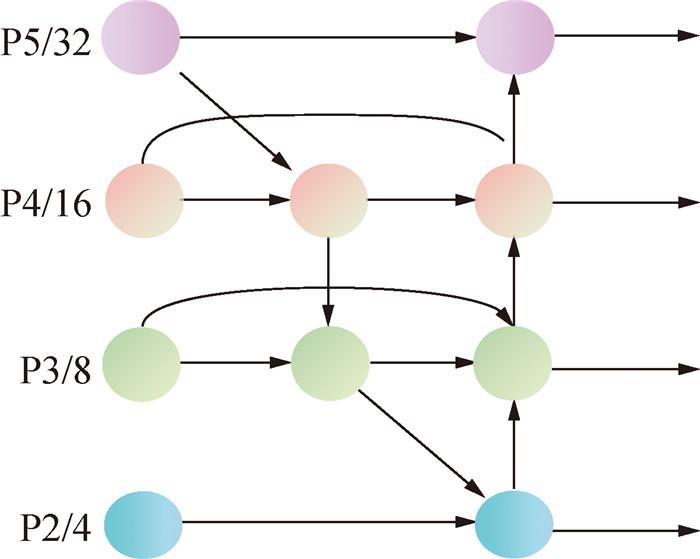
YOLOv8原始模型包含3个检测层:P5特征层20×20,用于检测尺寸大于32×32像素的目标,对应大型目标物体;P4特征层40×40,用于检测尺寸大于16×16像素的目标,对应中型目标物体;P3特征层80×80,用于检测尺寸大于8×8像素的目标,对应小型目标物体。为进一步提升模型对极小目标的检测能力,本研究引入P2特征层160×160,专门用于检测尺寸大于4×4像素的小目标裂缝,可提高小目标裂缝的检测精确率。为实现P2特征层与其他检测头之间的高效多尺度特征融合,引入BiFPN融合P2小目标检测层,通过跨层级的双向特征融合,使得语义低级特征能获得更广泛的感受野,以提升识别小目标的能力[21];通过引入多层特征融合机制,高级语义特征也获得了充分的细节特征信息,有助于识别大目标的边界细节,促进了特征的上下文传播,提高了整体对象检测的精确度,具体结构如图 4所示。
1.3 改进YOLOv8算法
一方面,考虑安全因素,无人机无法近距离拍摄桥梁裂缝;另一方面,桥梁裂缝尺寸较小且分布分散,导致获取的桥梁裂缝图像数据存在裂缝相对面积占比低且分布不均匀等问题。针对上述问题,原始YOLOv8模型存在漏检误检率高、检测精度低和检测头尺寸过大等缺陷。为解决上述问题,针对小目标裂缝数据的特点,本研究对YOLOv8算法的网络结构进行改进,具体改进措施如下,改进的YOLOv8网络结构如图 5所示。
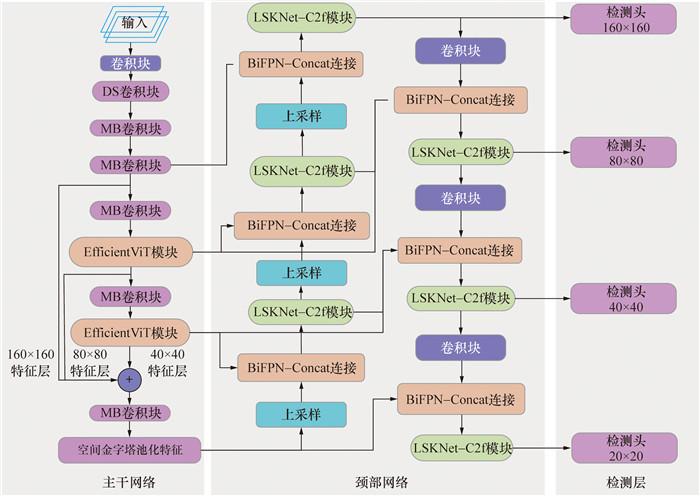
1) 用EfficientViT替换YOLOv8的主干网络,通过自注意力机制和卷积核分组稀疏化,减少冗余参数。
2) 保留并增强关键特征通道,提升对图像局部细节的特征提取能力,提高网络检测效率。
3) 在YOLOv8颈部结构中采用LSKNet注意力机制融合C2f模块,将标准2D卷积核分解为水平和垂直2个1D卷积核并级联,通过动态调整卷积核尺寸和稀疏化处理,降低模型的计算复杂度和内存占用。
4) 在YOLOv8颈部结构中引入BiFPN融合P2小目标检测层,实现不同尺度特征图之间的双向特征融合,降低上采样和下采样过程中的信息损失,增加160×160的P2检测头,以精准识别小目标裂缝。
2 网络训练与检测试验
2.1 数据集
目前,目标检测领域的公开数据集主要有PASCAL VOC、MS COCO和Image Net等[22]。本研究选取的裂缝检测数据集来自Roboflow中的公开数据集,包括南洋理工大学土木工程系公开裂缝数据集(https://universe.roboflow.com/ntu-department-of-civil-engineering/building_crack_obj)、new-workspace-hk52d公开裂缝数据集(https://universe.roboflow.com/new-workspace-hk52d/crack_1000_train)和fine公开裂缝数据集(https://universe.roboflow.com/fine-aqmsj/construction-site-jwnnh)。数据集共包含7 426张图像,其中:裂缝训练集图像6 426张,裂缝测试集图像1 000张。在裂缝训练集中选取1 396张图像作为裂缝验证集。本研究选取的裂缝模型训练数据集包含不同尺寸和类型的裂缝,以及同一图像中多种裂缝的情况,以提高模型的适用性,数据集的相关裂缝类型如图 6所示。小目标裂缝不仅占比过小,而且颜色较浅,因此难以识别。本研究选取的数据集具有多样性特征,可提高模型的泛化能力,增强模型的鲁棒性,并使模型在多场景下都有较强的实际应用能力,从而准确检测识别桥梁的小目标裂缝。本研究使用LabelImg标注数据集中的裂缝信息,将标注完成的图片另存为XML文件[23]。由于YOLOv8使用TXT格式的标注,因此须利用脚本从XML文件中提取每个ITEM的类别信息和4个坐标点信息,并将其保存在与图像命名一致的TXT文件中。标注完成的图像按照训练数据集、验证数据集和测试数据集分开保存。

2.2 试验平台及模型
本研究的模型训练平台为一高性能台式计算机,具体参数如表 1所示。为控制变量,本研究的每次试验均使用相同的计算机配置。
表 1 训练平台信息 |
| 计算机配置 | 参数信息 |
| CPU | 13th Gen Intel(R)Core(TM)i9-13900K |
| CPU内存 | 128 GB |
| GPU | NVIDIA GeForce RTX 4090 |
| GPU内存 | 64 GB |
| 操作系统 | Windows10 |
| Python版本 | 3.8.18 |
| Pytorch版本 | 2.0.1 |
| CUDA版本 | 11.7 |
| cuDNN版本 | 8.9.5 |
2.3 模型训练
为确保研究的严谨性和模型训练结果的可比性,本研究的所有模型设置相同的训练参数,如表 2所示,这些参数基于训练平台、模型训练效果和实际经验的综合考虑设置,以确保模型训练的稳定性和效率。上述参数在训练全过程中保持不变,以最大限度地控制训练条件的一致性,从而使不同模型的性能对比结果具有可靠性和参考价值。
表 2 模型训练参数 |
| 名称 | 信息 |
| 训练批量大小 | 16张图像 |
| 初始学习率 | 0.01 |
| 最终学习率 | 0.01 |
| 最大训练轮数 | 200 |
| 图像交并比 | 0.5 |
| 动量参数 | 0.8 |
2.4 评价指标
混淆矩阵是一种衡量分类模型性能的工具,广泛应用于图像识别领域的各类评价指标计算。本研究基于混淆矩阵计算了图像识别的多项评价指标,包括召回率R、准确率P、F1分数、平均精度均值50(mAP50)和平均精度均值50到95(mAP50-95)。这些指标能综合评估模型在小目标裂缝检测中的表现。
3 分析与讨论
为验证本文提出的改进YOLOv8算法的有效性,本研究进行了注意力机制LSKNet与C2f模块的融合对比试验、主干网络EfficientViT与融合BiFPN-P2的小目标改进对比试验和综合改进对比试验。
3.1 LSKNet与C2f模块的融合对比试验
为验证LSKNet注意力机制在不同位置改进的有效性,本试验将LSKNet融合C2f模块以不同的方式加入YOLOv8模型中的4个位置(Neck、Backbone、Backbone输出和Backbone输出与Neck组合),并分别命名为YOLOv8-LSKNet-Neck、YOLOv8-LSKNet-Backbone、YOLOv8-LSKNet- Backbone输出和YOLOv8-LSKNet-Backbone输出-Neck。在控制相关变量并保持模型训练条件一致的情况下,对4种模型依次进行训练。P、R和mAP50-95随迭代次数的变化曲线如图 7所示,模型最终的R、mAP50、mAP50-95、训练耗时和大小如表 3所示。
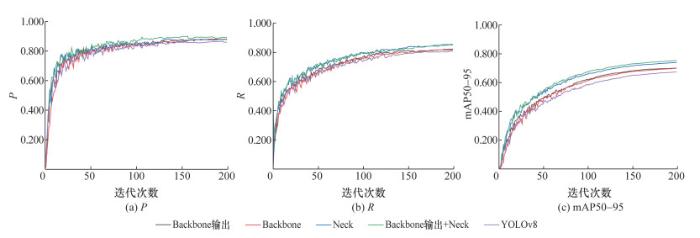
表 3 注意力机制改进对比试验最终结果 |
| 模型名称 | R | mAP50 | mAP50-95 | 训练耗时/h | 模型大小/MB |
| YOLOv8 | 0.809 | 0.858 | 0.674 | 1.750 | 6.3 |
| YOLOv8-LSKNet-Neck | 0.852 | 0.885 | 0.739 | 2.100 | 6.7 |
| YOLOv8-LSKNet-Backbone | 0.823 | 0.871 | 0.699 | 1.959 | 6.6 |
| YOLOv8-LSKNet-Backbone输出 | 0.820 | 0.877 | 0.701 | 2.555 | 10.9 |
| YOLOv8-LSKNet-Backbone输出-Neck | 0.855 | 0.897 | 0.752 | 2.035 | 7.0 |
训练结果表明,将注意力机制LSKNet融合C2f模块添加到YOLOv8算法的不同位置均可有效提高YOLOv8算法的相关性能。但添加注意力机制会导致模型大小、复杂度和构建时间增加。分析模型训练的迭代曲线可知,YOLOv8-LSKNet-Neck与YOLOv8-LSKNet-Backbone输出-Neck的R相似。由P和R评价结果可知,YOLOv8-LSKNet-Backbone输出-Neck模型在裂缝识别方面最有效。在其他模型的训练迭代曲线中,YOLOv8-LSKNet-Backbone输出-Neck均表现出优异的性能。与YOLOv8相比,YOLOv8-LSKNet-Backbone输出-Neck的提升最大,R提高了4.6%,mAP50提高了3.9%,mAP50-95提高了7.8%,表明其可提升裂缝识别的准确率。
3.2 EfficientViT与融合BiFPN-P2的小目标改进对比试验
为验证EfficientViT替换原始YOLOv8主干网络和融合BiFPN-P2小目标的有效性和可行性,本试验对原始YOLOv8主干网络和颈部结构进行了改进,并进行了3个试验:用EfficientViT替换YOLOv8算法的主干网络、用BiFPN-P2改进YOLOv8算法的颈部结构、融合EfficientViT和BiFPN-P2对YOLOv8算法进行改进。这3种改进模型分别命名为YOLOv8-EfficientViT、YOLOv8-BiFPN-P2和YOLOv8-EfficientViT-BiFPN-P2。在相同的模型训练条件下控制相关变量,并对3种改进模型进行训练。P、R和mAP50-95随迭代次数的变化曲线如图 8所示,模型最终的R、mAP50、mAP50-95、训练耗时和大小如表 4所示。
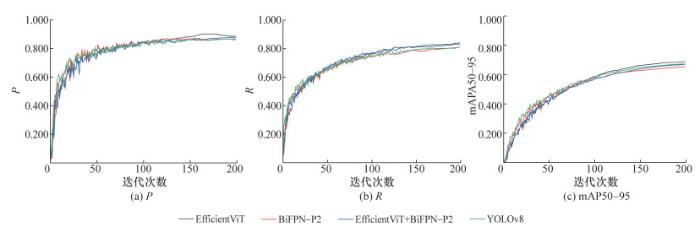
由各个模型的训练结果可知,YOLOv8-EfficientViT在各项评价指标上的总体提升效果最明显。但由于算法改进,模型参数增加,因此与原始的YOLOv8算法相比,所有模型的总体训练时间都变长,YOLOv8-BiFPN-P2甚至出现了负优化。与YOLOv8-BiFPN-P2相比,YOLOv8-EfficientViT-BiFPN-P2在性能上有所提升,表明YOLOv8融合EfficientViT和BiFPN-P2可以提高小目标算法的相关性能,但不及YOLOv8仅融合EfficientViT。最终结果表明,与YOLOv8算法相比,YOLOv8-EfficientViT的R提升了3.2%,mAP50提升了2.5%,mAP50-95提升了1.5%。综上所述,YOLOv8-EfficientViT和YOLOv8-EfficientViT-BiFPN-P2在性能上均有提升,因此能更准确地识别小目标裂缝。
3.3 综合改进对比试验
为验证本文改进YOLOv8模型的有效性,本试验用EfficientViT替换YOLOv8主干网络,并在基于颈部结构融合BiFPN-P2的基础上,引入LSKNet注意力机制,分别在改进算法的Neck、Neck与Backbone输出位置进行试验,并分别命名为YOLOv8改进-Neck、YOLOv8改进-Neck-Backbone输出。在3.2节中,YOLOv8-EfficientViT表现出色,因此将LSKNet注意力机制引入,也进行2组试验,分别命名为EfficientViT-Neck、EfficientViT-Neck-Backbone输出。保持有关变量不变,按照相同的模型训练条件对2种改进模型进行训练,并将其与YOLOv8、YOLOv8-EfficientViT和YOLOv8-EfficientViT-BiFPN-P2进行比较。P、R和mAP50-95随迭代次数的变化曲线如图 9所示,模型最终的P、R、F1、mAP50、mAP50-95、训练耗时和大小如表 5所示。
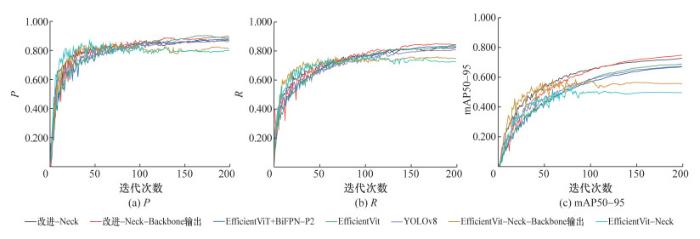
表 5 主干网络和颈部结构的改进对比试验的最终结果 |
| 模型名称 | P | R | F1 | mAP50 | mAP50-95 | 耗时/h | 模型大小/MB |
| YOLOv8 | 0.860 | 0.809 | 0.834 | 0.858 | 0.674 | 1.750 | 6.3 |
| EfficientVit+BiFPN-P2 | 0.878 | 0.829 | 0.853 | 0.874 | 0.670 | 4.328 | 16.2 |
| EfficientVit | 0.884 | 0.841 | 0.862 | 0.883 | 0.689 | 2.669 | 17.9 |
| EfficientVit-Neck | 0.799 | 0.727 | 0.757 | 0.800 | 0.516 | 2.625 | 17.9 |
| EfficientVit- Neck-Backbone输出 | 0.809 | 0.756 | 0.781 | 0.804 | 0.583 | 2.709 | 18.3 |
| 改进-Neck | 0.870 | 0.826 | 0.847 | 0.880 | 0.728 | 5.022 | 17.5 |
| 改进-Neck-Backbone输出 | 0.897 | 0.844 | 0.869 | 0.897 | 0.748 | 5.702 | 17.7 |
对比不同改进模型可知,YOLOv8改进-Neck-Backbone输出模型在各项评价指标上提升明显,但算法复杂度增加会导致模型的构建时间和大小均不如原始的YOLOv8算法。与YOLOv8算法相比,将主干网络替换为EfficientViT,融合BiFPN-P2结构进行小目标检测,在Neck和Backbone输出部分引入LSKNet融合C2f模块注意力机制,是提升效果最显著的改进方式,其中:P提升了3.7%,R提升了3.5%,F1提升了3.5%,mAP50提升了3.9%,mAP50-95提升了7.4%。由上述试验可知,与YOLOv8算法相比, 用EfficientViT网络替换YOLOv8主干网络,在颈部结构引入LSKNet融合C2f模块注意力机制,并增加BiFPN融合P2小目标检测头的模型性能提升较大,可准确识别小目标裂缝,能应用于实际应用中。
4 案例验证
本文以陕西省宝鸡市某斜拉桥为例,进行研究模型测试,如图 10所示,旨在验证YOLOv8改进模型在实际工程应用中的有效性。

本文利用DJI Mini 2消费级轻型无人机采集桥梁整体图像。由于DJI Mini 2无人机属于轻型无人机,因此能随时随地采集桥梁数据。飞行路线采用“弓”字形,从桥底向桥顶拍摄。依据DJI Mini 2提供的精确定位信息,确保无人机移动路径与桥梁表面保持平行,并将镜头垂直于航线方向,图像采集参数如表 6所示。最终获取了2 224张分辨率为4 000×2 250像素的桥梁原始图像,这些图像既包含桥梁裂缝的图像,又包含无裂缝的图像。由于桥梁状况良好,因此,经过人工复核,仅222张图像包含裂缝,这些图像被用于制作实际验证样本数据集。
表 6 图像采集参数 |
| 设备/飞行参数 | 说明 |
| 无人机 | DJI Mini 2 |
| 影像传感器 | 11.04 mm CMOS像素1 200万 |
| 卫星导航系统 | GPS+GLONASS+GALILEO |
| 定焦镜头 | 独立镜头 |
| 焦距/mm | 24 |
| 分辨率 | 4 000×2 250像素 |
| 镜头光圈 | f/2.8 |
| 拍摄时间/min | 120 |
| 拍摄距离/m | 3 |
| 重叠率 | 50% |
本研究分别利用改进的YOLOv8模型和原始的YOLOv8模型对采集的桥梁图像进行实际裂缝预测,部分预测结果如图 11所示。通过对比相同图像,本研究发现,与原始的YOLOv8算法相比,改进的YOLOv8算法更能准确地识别桥梁裂缝,尤其是像素占比较小的裂缝目标,避免了漏检情况。本研究还使用改进的YOLOv8模型和原始的YOLOv8模型对实际采集的桥梁裂缝图像进行了验证,部分验证结果如表 7所示。由图 11可知,本文所提改进YOLOv8算法在近景和远景图像中均表现出色,能准确识别桥梁裂缝。在实际桥梁应用中,与原始的YOLOv8算法相比,改进的YOLOv8算法的R提高了3.5%,mAP50提高了0.4%,mAP50-95提高了5.1%,而且图像处理耗时缩短了0.1 ms。改进YOLOv8算法能有效、快速、准确地检测桥梁裂缝,并能验证消费级无人机在桥梁裂缝监测方面的可行性。

5 结论
本文基于YOLOv8算法提出一种改进的桥梁裂缝小目标检测算法。首先,用EfficientViT网络替换YOLOv8的主干网络,并用深度可分离卷积优化特征融合网络,以减少大量冗余参数,并增强图像局部特征的提取能力;其次,通过引入LSKNet融合C2f模块注意力机制,弥补非结构化环境造成的精度损失,并通过选择性调整卷积核尺寸,降低运行参数,减少计算复杂度;最后,增加BiFPN融合P2小目标检测头、不同尺度特征图之间的信息耦合和小目标裂缝检测框,以提高小目标裂缝特征信息提取效果。与YOLOv8算法相比,本文算法的准确率提升了3.7%,召回率提升了3.5%,F1提升了3.5%,mAP50提升了3.9%,mAP50-95提升了7.4%,小目标裂缝的识别准确性得到较好提升。
通过无人机采集桥梁表观数据,可更高效、快捷地获取桥梁表观信息,与图像识别算法相结合,能解决桥梁健康监测中桥梁表观病害检测不足的问题。本文利用消费级无人机获取桥梁图像,既能降低桥梁的监测成本,又能满足图像的处理需求。
本文改进算法虽然能准确识别桥梁小目标裂缝,但模型参数的增加导致模型复杂度提升,从而使模型的训练耗时和大小大于原始YOLOv8算法。未来,本研究团队将继续深入研究小目标裂缝算法,以更加轻量化、高效的方式呈现模型内部的特征表示,解决算法误检和漏检等相关问题,将图像识别算法更好地应用于智能移动设备的使用场景中,使桥梁表观病害检测更便捷。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}