

现代信息系统已经成为企业运转过程中的重要组成部分之一。然而,这些系统时常受到来自内部员工的攻击威胁。内部攻击人员有权访问企业的网络信息系统,并且了解企业结构和安全程序,能够比较容易地规避系统防御检测机制,对企业的资产造成严重的损害[1-2]。2023年内部威胁报告显示,高达74%的企业遭受了频繁的内部攻击[3],体现出开发高效、准确的内部威胁检测模型的必要性。现有的内部威胁检测技术主要分为基于用户行为的检测和基于图的检测两大类。基于用户行为的检测通过分析个体行为模式来识别异常,但往往忽略用户间的关联,如角色互动和通信模式,这些信息对于识别潜在的内部威胁至关重要;另一方面,基于图的检测虽然考虑了用户间的互动,但通常缺乏对行为模式随时间变化的动态分析,限制了其检测能力。此外,数据集的不均衡性也是内部威胁检测面临的一大挑战。
为了克服这些局限性并提高内部威胁检测的准确性和适用性,本文综合考虑用户之间的关联、用户行为模式的动态性以及数据不均衡的影响,首先提出了DySAT_DNN内部威胁检测模型,该模型利用自注意力机制,在单一时间点聚合相邻节点的信息,在多个时间点捕获用户行为的动态变化,学习到更加准确、全面的表示,增强内部威胁检测的性能。接着通过消融实验,深入探究构成图结构的不同规则对模型性能的影响,并在验证集CERT R5.2上展示模型的泛化能力。此外,研究了数据不均衡问题,提出有效的采样策略来平衡正负样本的比例,进一步与当前先进的内部威胁检测方法进行比较,验证模型的有效性。
1 相关工作
内部威胁正成为许多企业面临的严重安全挑战。该威胁被定义为内部人员在安全环境中执行的异常活动,会导致系统破坏、电子欺诈和信息窃取,对个人、组织和国家安全造成潜在危害。近年来,内部威胁检测在学术界和工业界均引起了较大关注。相关工作主要围绕现有的两大类内部威胁检测技术展开。
1.1 基于用户行为的检测技术
在早期研究中,研究者们普遍认识到长短期记忆网络(long short-term memory,LSTM)在处理时间序列数据方面的潜力,并将其应用于从用户活动模式中提取顺序上下文信息。如Yuan等[4]通过LSTM-CNN框架来发现用户异常行为,解决了特征提取困难问题。Sharma[5]等提出了一种基于LSTM-Autoencoder模型,该模型通过计算会话活动的重构误差,有效地识别用户行为中的异常数据点。Singh等[6]指出现有内部威胁检测方法通过预置规则来检测异常用户活动,对不可预见的威胁的检测效果不佳,因此采用双向长短期记忆网络(bidirectional long short-term memory,Bi-LSTM)进行特征提取,采用支持向量机(support vector machine,SVM)将用户分类为正常或异常。Nasir等[7]提出LSTM-Autoencoder内部威胁检测模型,通过对用户活动进行分析,进行特征选择,从而有效地检测内部威胁。然而,上述方法只关注了序列数据的时间动态,忽略了数据中的其他类型特征。
与此同时,一些方法采用机器学习模型进行内部威胁检测。如Duc等[8-9]利用逻辑回归(logistic regression,LR)、深度神经网络(deep neural network,DNN)、随机森林(random forest,RF)、XGBoost等模型,结合用户行为的频率特征和统计特征,检测异常行为;且进一步考虑到用户行为序列之间的时间信息,通过比较用户行为序列与历史数据来识别异常。Zou等[10]结合XGBoost与数据调整策略来检测异常行为,减轻了数据不均衡的影响。Al-Mhiqani等[11]提出AD-DNN的检测模型,使用自适应合成技术(adaptive synthetic technique,ADASYN)解决数据不平衡问题,并应用DNN进行威胁检测。然而上述方法需要标签数据,检测精度不高。
在近期研究中,关于编码器-解码器以及注意力机制的方法受到研究者的关注。如Meng等[12]采用自编码器来建模正常行为,同时将门控循环单元(gated recurrent unit,GRU)与多头注意力机制结合提高检测性能。Huang等[13]利用基于注意力机制的Bi-LSTM进行有效的异常检测,通过对输入的行为向量进行加权处理,自动识别每个行为对分类结果的影响,从而提供行为级别的检测结果。Wang等[14]提出了一种端到端的深度聚类模型用于内部威胁检测,该模型首先通过编码解码结构从多源日志中学习用户行为特征,然后利用深度聚类确定中心并优化特征表示,最终通过分析用户行为与聚类中心的偏离程度来识别潜在的内部威胁。Pal等[15]提出了一个集成基于堆叠LSTM和堆叠GRU的注意力模型,用于从用户的单日活动序列中检索有关用户正常和异常行为的有用信息。Zhu等[16]提出一个基于对抗自编码器的无监督内部威胁检测方案AUTH,该方案结合时间卷积网络和LSTM进行特征提取,特别关注时间特征和事件频率特征,在没有预定义标签的情况下重构正常行为序列。
1.2 基于图的检测技术
基于图的检测技术一般采用用户间的角色、用户间的邮件通信来构建图结构,进而更加全面地分析和识别潜在的内部威胁。如Gamachchi等[17]提出了一种利用属性图聚类和异常评分机制来增强内部威胁检测的框架,以识别用户行为中的异常活动。Wang等[18]提出,为了更准确地检测用户的异常行为,除了关注用户自身的活动外,还需要考虑具有相同工作角色的其他用户的潜在异常活动。Jiang等[19]设计了图卷积神经网络(graph convolutional network,GCN)模型以检测用户的异常行为,该模型结合邮件通信关系和用户行为的相似性设计了加权函数作为邻接矩阵,提高了检测的准确性。Hong等[20]提出了一种包含图神经网络和卷积神经网络(convolutional neural network,CNN)组件的残差混合网络ResHybnet模型,利用用户间的归属关系构建图结构。此外,还有一些基于特定规则来构建图结构的方法,如Liu等[21]针对目前异常检测模型仅考虑用户日志记录的序列关系,却忽略了其他关系(例如用户在一段时间内的日常行为相对规律);利用日志记录的多种关系构建异构图,采用随机游走和word2vec,生成操作记录的表示向量,采用聚类的方法来判定用户操作是否异常。Fei等[22]提出基于GCN的内部威胁检测方法Log2Graph。采用数据扩充来平衡数据集,对于图的构造,它将每条日志视为一个节点,并将时间序列和逻辑关系中的日志节点连接起来形成图。
1.3 现有技术比较
表 1 内部威胁检测方法对比 |
| 序号 | 检测方法 | 特征提取方式 | 考虑因素 | 验证数据集 | 来源 | |
| 时序信息 | 结构关系 | |||||
| 1 | LSTM | √ | × | CERT R4.2 | 文[4] | |
| 2 | LSTM | √ | × | CERT R4.2 | 文[5] | |
| 3 | Bi-LSTM | √ | × | CERT R4.2 | 文[6] | |
| 4 | LSTM | √ | × | CERT R4.2 | 文[7] | |
| 5 | 数据预处理聚合 | × | × | CERT R5.2 | 文[8] | |
| 6 | 数据预处理聚合 | √ | × | CERT R4.2 | 文[9] | |
| 7 | 基于行为 | 数据预处理聚合 | × | × | CERT R6.2 | 文[10] |
| 8 | 日志聚合和解析器 | × | × | CERT R4.2 | 文[11] | |
| 9 | Multi-att-LSTM | √ | × | CERT R6.2 | 文[12] | |
| 10 | Bi-LSTM-att | √ | × | CERT R4.2 | 文[13] | |
| 11 | Encoder-decoder | √ | × | CERT R4.2 | 文[14] | |
| 12 | stacked-LSTM-GRU-att | √ | × | CERT | 文[15] | |
| 13 | Adver-autoencoder | × | × | CERT R6.1/6.2 | 文[16] | |
| 14 | —— | × | √ | CERT R4.2 | 文[17] | |
| 15 | 角色关系构建图结构 | × | √ | CERT R6.2 | 文[18] | |
| 16 | 基于图 | 邮件关系构建图结构 | × | √ | CERT R4.2 | 文[19] |
| 17 | (静态图) | 角色关系构建图结构 | √ | √ | CERT R4.2 | 文[20] |
| 18 | 既定规则构建图结构 | √ | √ | CERT R5.2 | 文[21] | |
| 19 | 既定规则构建图结构 | √ | √ | LANL | 文[22] | |
| 20 | DySAT_DNN | √ | √ | CERT R4.2或CERT R5.2 | 本文 | |
因此,尽管现有的内部威胁检测技术在特征提取和方法论上取得一定的进展,但在处理动态变化的数据以及应对数据不均衡问题方面仍存在一些局限。因此,本研究提出一种基于动态图的内部威胁检测模型(DySAT_DNN模型),基于Sankar等[23]提出的动态自注意力网络(DySAT),利用注意力机制在单一时间点聚合相邻节点的信息,在多个时间点捕获用户行为的动态变化,准确地识别内部威胁。此外,针对数据不均衡的问题,通过实验揭示数据不平衡对模型性能的影响,从而找到一种有效的采样策略以平衡正负样本的比例,提升模型的整体性能。
2 内部威胁检测模型
内部威胁检测的关键是对用户的正常行为进行建模,以检测异常行为。本文所提出的DySAT_DNN模型如图 1所示。整体过程如下:
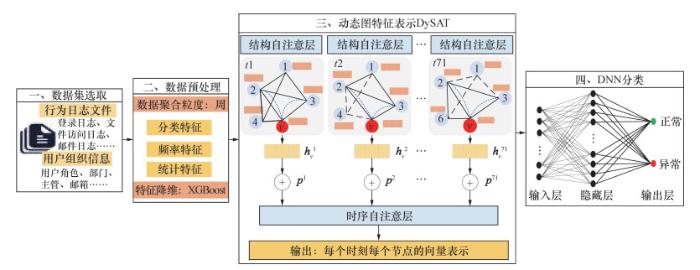
1) 数据集选取:选用卡内基梅隆大学计算机应急响应团队发布的用户行为日志数据集CERT R4.2。该数据集由用户行为日志和用户的组织信息组成。
2) 数据预处理:在周粒度(以周为单位的数据划分)下聚合上述多源数据,提取用户行为的数值特征。然后,采用XGBoost方法进行数值特征的降维,忽略次要特征的影响。
3) 动态图特征表示:由于用户行为和用户之间的关联性随时间变化,传统的静态特征表示方法无法充分捕捉这一动态性。因此,采用动态图DySAT模型来学习用户行为的特征表示。
4) DNN分类:使用全连接神经网络作为分类器来对学习到的表示进行分类任务,通过训练使其能够区分正常行为和异常行为。
2.1 数据集选取
CERT R4.2数据集包含1 000个用户,其中70个是异常用户。数据集模拟了企业在18个月中用户的正常和异常活动。数据集由用户行为日志文件,如登录日志(logon.csv)、设备连接日志(device.csv)、文件操作日志(file.csv)、邮件日志(email.csv)、网站访问日志(http.csv)和用户的组织信息(LDAP)。数据集相关信息的描述如表 2所示。
表 2 CERT R4.2数据集描述 |
| 数据集组成 | .csv文件中字段 | |
| 行为日志文件 | logon.csv | id、日期、用户、pc、活动(登录、注销) |
| device.csv | id、日期、用户、pc、活动(是否连接) | |
| file.csv | id、日期、用户、pc、文件名、内容 | |
| email.csv | id、日期、用户、pc、收发邮箱、大小等 | |
| http.csv | id、日期、用户、pc、url、内容 | |
| 用户组织信息 | LDAP | 用户、企业邮箱、角色、部门、主管 |
注:id为记录用户行为的唯一标识;pc表示用户使用的电脑信息;url表示用户进行http访问的地址。 |
2.2 数据预处理
首先,为了整合用户在一段时间内的活动信息,在周粒度的聚合条件下,基于用户id将登录活动、文件操作、邮件操作、网站访问、设备连接等多源日志数据进行了聚合。通过比较原始数据样本与聚合后的数据样本(见表 3),可以观察到聚合后的数据在分布上仍然呈现出不均衡的特点。
表 3 原始数据样本与聚合数据样本比较 |
| 正常样本 | 异常样本 | |
| 原始数据样本 | 322 762 804 | 7 423 |
| 聚合后数据样本 | 66 321 | 316 |
接着,对聚合后的数据进行特征提取,生成用户活动的数值特征。具体来说,是对用户在不同时间段内进行的各类操作以及用户在不同PC上的操作进行统计。通过对操作的统计和分析,得到了频率特征(如发送邮件数量、下班后文件访问数量等)和统计特征(如邮件大小、文件大小等)。最终,提取的用户行为特征维度总计为652。为了进一步完善用户信息,在LDAP中提取了用户的组织信息,得到了用户的分类特征(如用户角色、所属部门、团队等),分类特征维度为6维。按周粒度聚合的数据样本的标签设定原则为:判断用户的异常行为是否在该周出现,若出现,则该数据样本为“异常”,反之为“正常”。
最后,对于高维特征数据,进一步采用XGBoost模型进行特征降维,降低计算的复杂度。本文选取了特征重要性分数大于或等于15的16维特征作为最终的输入特征。16维特征及其重要性分数如表 4所示。
表 4 16维特征及其重要性分数 |
| 特征 | 重要性分数 |
| pc0上进行usb操作数 | 44 |
| usb操作总数 | 39 |
| 访问恶意网站总数 | 35 |
| 上班期间usb操作总数 | 34 |
| 访问网页的url深度 | 26 |
| 进行登录操作的总数 | 24 |
| 文件操作中文件大小 | 24 |
| 上班期间pc0进行usb操作数 | 21 |
| pc0上的总操作数 | 20 |
| pc3上的总操作数 | 19 |
| 上班期间登录操作的总数 | 19 |
| 上班期间接收邮件数 | 17 |
| 网页访问数 | 17 |
| 总操作数 | 15 |
| 向外发送邮件数量 | 15 |
| 向外发送含bcc的邮件数量 | 15 |
注:pc0表示用户个人电脑;pc3表示用户主管电脑;usb表示外部设备;url表示用户进行http访问的地址;bcc表示秘密发送收件人。 |
在图的构建部分,利用LDAP文件夹中给出的组织关系,获取1 000个用户对应角色(user)和主管(sup)的信息,根据以下3个规则来构建图:
1) 如果user-A的主管是sup1,那么建立user-A与sup1之间的连接关系;
2) 如果user-A和user-B归属于同一个主管,则建立user-A与user-B之间的连接关系;
3) 如果组织中的用户属于同一角色,则为同一角色的用户建立连接关系。
2.3 动态图特征表示
现有大多数研究采用静态图来学习用户行为的特征表示,但现实中的图大多为动态,随时间演变。DySAT模型由2个主要部分组成:结构自注意层和时序自注意层,该模型可以灵活适应节点和边的动态变化,通过自注意力机制能够学习并捕获图结构特性和时间演化模式的节点表示。鉴于本文研究的用户行为和用户之间关系随时间动态变化,因此采用DySAT模型来学习表示。
2.3.1 结构自注意层
将聚合后的数据样本按照周进行划分,可以观察到71个时间步长(即T=71)。随着时间的推移,用户数量是不固定的,因此所构建的图结构也不同。结构自注意层的输入和输出表示如图 2所示,其中黑色虚线表示对应节点在该时间步长下消失,蓝色虚线表示基于相邻的结构性关注。每个时间步长根据上节所述规则构建图结构,生成了动态图集合$G=\left\{\mathcal{G}^1, \mathcal{G}^2, \cdots, \mathcal{G}^t, \cdots, \mathcal{G}^{T-1}, \mathcal{G}^T\right\}$。任一时间步长下的图$\mathcal{G}^t=\left(V, \varepsilon^t\right)$具有节点集V、边集εt和邻接矩阵At。
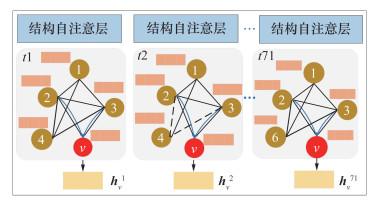
结构自注意层聚集相邻节点的特征以计算每个时间步长的中间节点表示。该层的输入数据是一个时间步长下的图$\mathcal{G}^t \in \mathbb{G}$和输入节点的特征{xv∈$\mathbb{R}^D, \forall v \in V$},本文中D设置为16。输出是节点的中间表示$\left\{\boldsymbol{h}_v \in \mathbb{R}^F, \quad \forall v \in V\right\}$,本文中F设置为16。以任一时间步长为例,节点v的中间表示可由式(1)—(2)计算。
其中,$\mathcal{N}_v=\{u \in V: (u, v) \in \varepsilon\}$是图$\mathcal{G}^t$中节点v的直接相邻节点集,$\boldsymbol{W} \in \mathbb{R}^{D \times F}$是图中每个节点共享的权重,xu表示与v节点相邻的节点的特征,$\boldsymbol{a} \in \mathbb{R}^{2 F}$是一个权重向量,用作实现注意力函数的参数。$\|$表示连接操作,σ(·)是非线性激活函数。Auv是当前图$\mathcal{G}^t$中节点u和v之间的连接权重。αuv系数的计算表明在当前图中节点u对节点v的重要性。对v节点的所有相邻节点进行加权求和得到v节点的中间表示。依次遍历所有的时间步长,即可得到每个时间步长下所有节点的中间表示。
2.3.2 时序自注意层
时序自注意层的关键目标是捕获图结构在多个时间步长的变化。结构自注意层的输出作为时序自注意层的输入,将不同时间步长的中间表示进行拼接,得到每个节点的序列表示。由于存在节点的动态变化(即并非所有的节点会有71个时间步长),因此,需要对不足71个时间步长的节点序列表示进行补0操作。
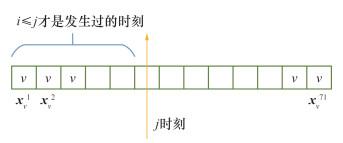
时序自注意层的输入序列表示如图 3所示。对于节点v,将位置嵌入pt添加到输入特征hvt上,用于引入时间信息,则序列表示为{ xv1, xv2, …, xvt, …, xvT}, 且 $\boldsymbol{x}_v^t=\left(\boldsymbol{h}_v^t+\boldsymbol{p}^t\right) \in \mathbb{R}^F, \boldsymbol{p}^t$是采用Xavier初始化方法得到的值。输出是在共计T个时间步长下节点v的新的表示序列{zv1, zv2, …, zvt, …, zvT}, 且$\boldsymbol{z}_v^t \in \mathbb{R}^{F^{\prime}}$。F′表示经过时序自注意层的节点输出维度。使用矩阵$\boldsymbol{X}_v \in \mathbb{R}^{T \times F}$ 和Zv∈ $\mathbb{R}^{T \times F^{\prime}}$分别作为节点v的输入和输出表示。
采用自注意力机制计算节点v在每个时间步长下的输出Zv,计算方法如下:
其中:$\boldsymbol{W}_q \in \mathbb{R}^{F \times F^{\prime}}、\boldsymbol{W}_k \in \mathbb{R}^{F \times F^{\prime}}、\boldsymbol{W}_v \in \mathbb{R}^{F \times F^{\prime}}$是自注意参数,$\boldsymbol{\beta}_v \in \mathbb{R}^{T \times T}$表示节点v所有时间步长下的注意力系数,$\boldsymbol{M} \in \mathbb{R}^{T \times T}$表示一个掩码矩阵,i表示当前要更新的时间步,j表示被i所关注的时间步,在i≤j时,Mij =0;在i>j时,Mij=-∞,这时softmax函数产生零注意权重,即βvij=0,只需要关注j时刻发生之前的时间步长的注意力。
采用式(1)—(5)获得其他节点的输出表示,对于填充0的节点序列,在输出表示中移除。将每个节点在71个时间步长上的表示和相应的标签进行关联,构建节点表示和标签的数据集。最后将上述节点表示和标签数据作为DNN分类器的输入进行分类。
2.4 DNN分类
为了训练和评估DNN分类器的性能,将数据集的前70%作为训练集,用于训练模型并调整参数;剩下的30% 作为测试集,用于评估模型在未见数据上的泛化能力。DNN分类器的实现基于PyTorch深度学习框架。在训练过程中,使用交叉熵损失函数和Adam优化器对模型进行训练。根据DNN分类器的输出结果,判断用户活动是否异常以采取相应的安全措施。
3 实验评估
3.1 性能指标
在进行内部威胁检测时,主要使用分类器模型进行二分类任务,判断用户是否存在异常活动。为了衡量本文所提模型的性能,使用精度P、宏精度Pmacro、召回率R、宏召回率Rmacro、F1、宏F1分数F1macro、曲线下面积(AUC)以及假阳性率(FPR)作为评估指标,计算公式如式(6)—(12)所示:
其中:TP和TN表示正确预测的部分,FP和FN表示错误预测的部分。以正常样本(正样本)为例,P表示所有预测为正常样本中,真实类别为正常的比例,表示精度;R表示所有真实类别为正常样本中,预测类别为正常的比例,表示召回率;FPR表示所有真实类别为异常样本(负样本)下,预测类别为正常的比例;“宏”表示所有类别对应评估指标的平均值,即Pmacro,Rmacro,F1macro。
3.2 实验结果
为了有效验证所提出模型的性能,本文设计了4个阶段的实验进行全面评估。第一阶段通过与现有分类器模型进行比较,评估DySAT_DNN模型的检测性能。第二阶段通过消融实验,深入探究构建图结构的3个规则(详见2.2节)对检测结果的影响以及模型在验证集(使用CERT R5.2数据集)上的性能。第三阶段研究数据不均衡问题,分析数据采样策略对模型检测性能的具体影响。第四阶段与当前先进的内部威胁检测技术进行比较研究,验证本模型有效性。
3.2.1 模型性能分析
将6个常用的分类器模型与DySAT_DNN模型的检测性能进行了对比,包括SVM、RF、LR、LSTM、DNN、CNN。由表 5可知,DySAT_DNN模型总体上取得了很好的效果,在Rmacro和F1macro方面表现领先,分别达到0.80和0.81。尽管RF在Pmacro方面表现良好,但Rmacro较低,这可能表明在不均衡的数据集下,RF分类的结果更加偏向于数量较多的类别。LSTM能够捕获时序信息,但忽略了用户关系所包含的信息,导致其Rmacro较低。相比之下,DNN和CNN在Rmacro方面表现较好,这可能是因为神经网络能够学习到较丰富的特征。
值得一提的是,DNN在单独作为分类模型时效果不理想,但通过结合DySAT学习到的表示,在Pmacro,Rmacro,F1macro方面显著提升。这充分体现了DySAT利用聚合的相邻节点信息和时序信息的优势,获得了更加准确全面的特征表示,使模型可以学习和利用更多的信息,从而取得了更好的性能。
表 5 不同检测模型性能对比 |
| 模型 | Pmacro | Rmacro | F1macro |
| SVM | 0.82 | 0.59 | 0.64 |
| RF | 0.96 | 0.61 | 0.68 |
| LR | 0.78 | 0.62 | 0.67 |
| LSTM | 0.81 | 0.59 | 0.64 |
| DNN | 0.65 | 0.65 | 0.65 |
| CNN | 0.81 | 0.69 | 0.73 |
| DySAT_DNN | 0.81 | 0.80 | 0.81 |
3.2.2 消融实验
1) 图规则对模型性能的影响。
本文考虑的3种规则详见2.2节。通过改变这些规则的组合,评估每条规则对模型检测性能的贡献,探究构建图结构的不同规则对模型性能的影响,从而优化图结构的设计。不同规则组合下的DySAT_DNN模型性能对比如表 6所示,由表可知,仅使用规则1时,DySAT_DNN模型的Pmacro和Rmacro分别为0.65和0.67,该效果与传统分类器方法相当。同时使用规则1和2时,Pmacro提高到0.71。同时使用规则1、2和3时,模型的Pmacro和Rmacro均达到最高,分别为0.81和0.80。这表明综合使用所有规则能显著提升模型的检测性能。此外,本文的规则设置通过定义用户与主管之间的连接关系,有助于更好地捕捉主管相关的威胁活动,例如用户登录其主管的电脑发布警示邮件造成的组织混乱的情况,可以通过本文设置的规则得到更好的识别和分析。
表 6 不同规则组合下模型性能对比 |
| 模型设置 | Pmacro | Rmacro |
| DySAT_DNN(规则1) | 0.65 | 0.67 |
| DySAT_DNN(规则1+2) | 0.71 | 0.68 |
| DySAT_DNN(规则1+2+3) | 0.81 | 0.80 |
2) 验证集CERT R5.2上的性能分析。
在本实验中,采用CERT R5.2数据集来验证DySAT_DNN模型。该数据集中有2 000个用户,其中99个用户被标记为异常用户。数据集由用户行为日志文件和用户组织信息文件组成。
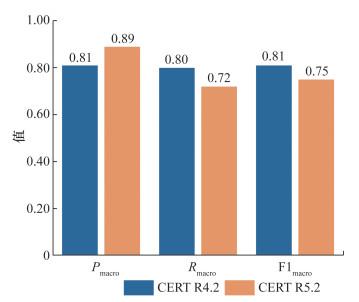
首先,对数据进行了统一的预处理,以生成适用于DySAT_DNN模型的输入数据。然后,在训练好的模型上应用这些数据,得到如图 4所示的结果。经过分析发现,DySAT_DNN模型在CERT R5.2数据集上的Rmacro和F1macro略低于CERT R4.2数据集上的,但Pmacro有所提高。这种性能差异主要源于数据分布的问题。在CERT R4.2数据集上的正常样本和异常样本的数量分别为66 005和316个,而CERT R5.2上的分别为137 808和552个。正如文[15]中的分析,随着正负样本比的变化,Rmacro从0.775下降至0.109,这表明正负样本比例的显著变化可能导致模型在Rmacro上的性能明显下降。然而,本模型在CERT R5.2数据集上的Rmacro和F1macro指标仍然保持在0.72左右,这进一步说明了模型具有一定的泛化能力。
此外,本节进一步对不同数据集上的异常用户检测模型所需的计算成本进行了分析。计算成本包括数据预处理、图构建、DySAT特征提取以及分类所需的时间成本,且时间单位为min。由表 7可知,CERT R5.2数据集的数据样本明显比CERT R4.2数据集多,且具有更高的特征维度,导致其计算时间成本达到235.96 min,高于CERT R4.2数据集的83.32 min。文[13]中提出的方法利用ML-Transformer架构来捕获上下文感知的动态表示,但其时间成本高达600 min。相比之下,本文提出的模型在不同数据集上的运行时间远低于这一数值,表明其在保持合理时间成本的同时,具备良好的可扩展性和效率。
表 7 不同数据集上检测所需的计算成本 |
| 数据集 | 数据样本/条 | 特征维度 | 时间成本/min | |
| 正常 | 异常 | |||
| CERT R4.2 | 66 005 | 316 | 652 | 83.32 |
| CERT R5.2 | 137 808 | 552 | 1 080 | 235.96 |
3.2.3 数据采样策略对模型性能的影响
针对数据不均衡这一普遍存在的问题,本节首先进行了采样策略与模型性能的关系分析,研究不同的正负样本条数比对模型性能的影响。选取2个分类器模型(CNN和DNN)与DySAT_DNN模型进行性能对比,结果如表 8所示。由表可知,在正负样本条数比为1∶1时,CNN、DNN和DySAT_DNN均表现出很好的性能;当正负样本条数比增加至10∶1时,DNN模型的性能急剧下降;进一步增加至50∶1时,尽管CNN和DNN模型的性能明显降低,但DySAT_DNN模型仍保持较高水平。当正负样本条数比增加至100∶1时,所有模型的性能都有所下降,但DySAT_DNN模型在F1macro上仍然优于其他2个模型。这一现象表明,随着正样本条数的增多,模型的F1macro通常会下降,而Rmacro的下降更为显著。这进一步说明,随着正负样本条数比的增加,模型越来越难以检测到负样本。这一结果强调了采样策略的重要性。
表 8 不同正负样本条数比下检测模型性能对比 |
| 模型 | 正负样本条数比1∶1 | 正负样本条数比10∶1 | 正负样本条数比50∶1 | 正负样本条数比100∶1 | |||||||
| Rmacro | F1macro | Rmacro | F1macro | Rmacro | F1macro | Rmacro | F1macro | ||||
| CNN | 0.93 | 0.94 | 0.91 | 0.91 | 0.83 | 0.83 | 0.76 | 0.79 | |||
| DNN | 0.94 | 0.94 | 0.80 | 0.85 | 0.77 | 0.77 | 0.67 | 0.73 | |||
| DySAT_DNN | 0.98 | 0.98 | 0.93 | 0.94 | 0.92 | 0.85 | 0.74 | 0.81 | |||
接着,为了确定最优的采样策略,评估了6种采样策略对模型性能的影响,包括无采样、仅欠采样、仅过采样以及3种不同的采样组合,实验结果如表 9所示。由表可知,未进行任何采样时,模型对正常样本存在显著偏见,导致训练集和测试集的R非常低,FPR为0,几乎不存在误报;对正常样本(多数类)进行欠采样时,尽管异常样本(少数类)的测试集的R提高至0.962,但由于正常样本数量显著减少,测试集的假阳性率上升至0.091;随着异常训练样本数量的增加(通过GAN和重复复制来生成异常样本,见第3—5行),模型逐渐对特定异常实例过拟合,从而降低了对未知异常样本的预测能力。最后,仅对异常样本进行过采样(第6行)时,模型出现高度过拟合,导致异常类的测试R下降至0.500。对于采样2策略,模型在训练集和测试集上都显示出较高的AUC和R以及较低的FPR。这表明该采样策略有效地提高了模型对少数类的识别能力,同时保持了对多数类的有效识别水平,综合表现最优。
表 9 不同的采样策略对模型性能的影响 |
| 序号 | 采样方法(正常样本条数/异常样本条数) | AUC | R | FPR | |||||
| 训练集 | 测试集 | 训练集 | 测试集 | 训练集 | 测试集 | ||||
| 1 | 原始数据(66 005/316) | 0.828 | 0.989 | 0.174 | 0.196 | 0 | 0 | ||
| 2 | 仅欠采样(316/316) | 0.976 | 0.989 | 0.969 | 0.962 | 0.098 | 0.091 | ||
| 3 | 采样1(3 160/3 160) | 0.994 | 0.993 | 0.987 | 0.912 | 0.039 | 0.026 | ||
| 4 | 采样2(15 800/15 800) | 0.997 | 0.997 | 0.995 | 1.000 | 0.021 | 0.008 | ||
| 5 | 采样3(22 120/22 120) | 0.998 | 0.996 | 0.996 | 0.890 | 0.017 | 0.017 | ||
| 6 | 仅过采样(66 005/66 005) | 0.999 | 0.776 | 0.997 | 0.500 | 0 | 0.010 | ||
通过上述实验,不仅揭示了数据不平衡对模型性能的影响,而且找到了一种有效的采样策略,可以平衡正负样本的比例,提升模型的整体性能。此外,DySAT_DNN模型在极端不均衡数据条件下,比其他模型展现出了更强的泛化能力和稳健性。
3.2.4 比较研究
为了进一步验证所提模型的有效性,选取了多种基线模型与DySAT_DNN模型进行性能对比。这些基线模型涵盖了多个方面:一是从用户活动模式中提取顺序上下文信息的模型,例如基于LSTM_ CNN的模型[4]、基于Bi_LSTM的模型[6]以及基于LSTM_autoencoder的模型[20];二是考虑了用户之间关联性的模型,如采用静态图神经网络进行训练的模型[19-20];三是运用注意力机制来强调活动模式关键部分的模型,比如采用堆叠的LSTM和堆叠的GRU模型的集成[15],基于Bi_LSTM_attention的模型[13]以及将多头注意力的LSTM作为特征提取模型[12]。然而,DySAT_DNN模型通过自注意力机制在单一时间点聚合关键信息,并跨多个时间点捕获行为的动态变化,有效提取活动序列丰富上下文信息,从而提供更精确的上下文特征向量表示活动模式。
DySAT_DNN模型与基线模型的性能对比如表 10所示,DySAT_DNN模型的性能指标是在特定的采样2策略下获得的。通过对比分析可以发现,DySAT_DNN模型在P、F1以及AUC方面高于基线模型,因此DySAT_DNN模型在内部威胁检测任务中具有较高的性能和较好的泛化能力。
表 10 DySAT_DNN模型与基线模型的性能对比 |
| 模型 | P | R | F1 | AUC |
| LSTM-CNN | — | — | — | 0.940 |
| Bi-LSTM-SVM | 0.851 | 0.823 | 0.827 | 0.930 |
| revised-GCN | — | 0.833 | — | — |
| ResHybnet | 0.910 | 0.928 | 0.921 | — |
| LSTM-GRU-att | — | 1.000 | — | 0.994 |
| Bi-LSTM-att | 0.933 | 0.918 | 0.924 | — |
| Multi-att-LSTM | — | 0.776 | — | — |
| DySAT_DNN | 0.990 | 1.000 | 0.940 | 0.997 |
4 结论
目前内部威胁检测研究主要面临2个局限:其一,未充分考虑到用户关系和用户行为模式随时间动态变化的特性;其二,数据不均衡问题普遍存在,这影响了模型的准确性和可靠性。因此,本文提出了一种基于动态自注意力深度神经网络的内部威胁检测模型(DySAT_DNN模型),该模型通过引入自注意力机制来捕捉用户行为随时间演化的动态特征,同时结合时序信息和用户关系的演变,得出如下结论:
1) 模型基于自注意力机制,可以动态聚合相邻节点信息和捕捉行为动态变化,在CERT R4.2数据集上的实验结果表明,该模型在内部威胁检测任务中的性能优于其他分类器模型。
2) 通过消融实验探究构成图结构中规则对模型性能影响,并在验证集CERT R5.2上测试了模型的泛化能力。
3) 针对数据不均衡问题,找到合适的采样策略平衡正负样本比例,进一步与当前先进的方法进行对比分析,DySAT_DNN模型在多个评估指标上表现出色,从而证明了模型在内部威胁检测的有效性和优越性。
本文中图的构建主要针对依据用户之间的角色关系和归属关系,未来可进一步考虑其他关系(如邮件关系)对模型性能的改进。此外,本文主要基于图的检测技术进行优化,而针对用户行为的检测有利于提前发现异常行为,避免威胁事件的发生,也值得深入研究。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}