

量子密钥分发(quantum key distribution, QKD)是一种基于量子特性的密钥传输方式,允许通信双方(假定为Alice和Bob)产生并共享一个随机且安全的密钥[1],其安全性依赖于量子力学的基本原理:任何窃听行为都会不可避免地干扰量子系统,而这种干扰可以被通信方检测到[1]。根据量子态的Hilbert编码空间维度,QKD通常被分为2大类:离散变量量子密钥分发(discrete variable QKD,DV-QKD)[1]和连续变量量子密钥分发(continuous variable QKD,CV-QKD)[2]。DV-QKD的概念提出较早,技术发展也相对成熟;但由于其系统复杂性,实现成本通常较高。CV-QKD虽然起步较晚,但由于协议设计较为简单且成本较低,近年来已成为量子密码学领域的研究焦点。
一次完整的QKD过程包括量子传输和后处理2个阶段。在量子传输阶段,Alice制备量子态并通过量子信道发送给Bob,由Bob随后进行测量。由于设备不完美和信道干扰等因素,Alice和Bob得到的原始密钥可能会存在误差。为了纠正这些误差,消除窃听者(假定为Eve)获取的信息,并最终提取出安全的密钥,后处理变得必不可少。后处理步骤涵盖基础筛选、参数估计、数据协调和隐私放大。其中,数据协调是后处理的关键环节,因其确保了通信双方密钥的一致性。
1 基础理论
1.1 符号表示
使用大写字母(如X,Y)表示随机变量,相应的小写字母(如x,y)表示其对应的实现值;xi∶j表示行向量(xi, xi+1, …, xj),xi∶jT或 x(i)∶(j)表示相应的列向量,当不满足条件1≤i≤j时为空向量。H(X)表示随机变量X的二元熵,I(X; Y)表示随机变量X和Y之间的互信息。N表示编码的码长,N=2n(n≥1),[N]表示集合{1, 2, …, N},K(1≤K≤N)表示编码的信息长度;$ \mathbb{R}$ 表示实数集,$ \mathbb{Z}$ 表示整数集。字符上标c表示补集。
1.2 连续变量量子密钥分发
CV-QKD过程包括量子传输阶段和后处理阶段,如图 1所示,在量子传输阶段,Alice通过量子信道向Bob发送连续变量X。由于设备不完善和信道干扰等因素,Bob接收到的信号Y与X存在误差Z。在后处理阶段,Alice通过经典信道向Bob发送补充信息,Bob根据Y和补充信息生成与Alice相同的密钥。在本研究中,假设X、Y和Z都服从Gauss分布,且Z与X相互独立。
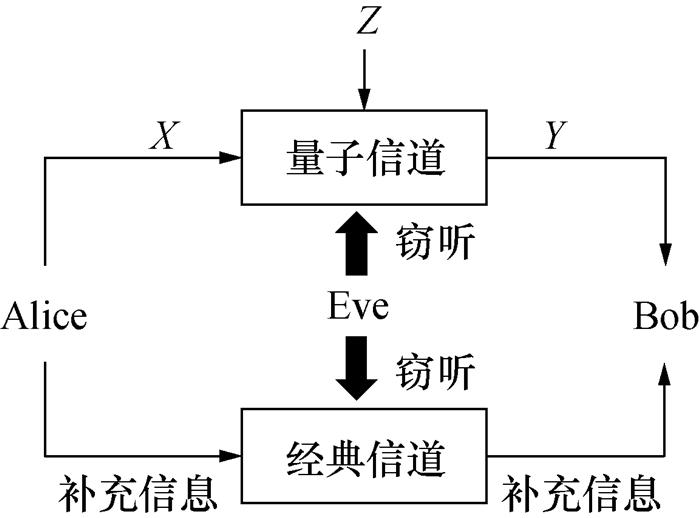
1.3 数据协调
由于量子信道的固有特性,任何窃听行为均能被检测到,这使得量子传输阶段发送的消息可以认为是完全保密的。然而,经典信道不具备这一特性,无法保证后处理阶段传输的信息不被第三方窃听。因此,后处理阶段不仅要实现密钥同步,还要确保信息的安全性。数据协调作为后处理的关键步骤,负责保证通信双方能够生成一致的密钥。在高SNR的通信环境下,切片协调是一种常用的数据协调方案[3],其核心思想是通信的一方先将连续变量进行量化,然后利用纠错编码技术帮助另一方获取相同的量化结果。
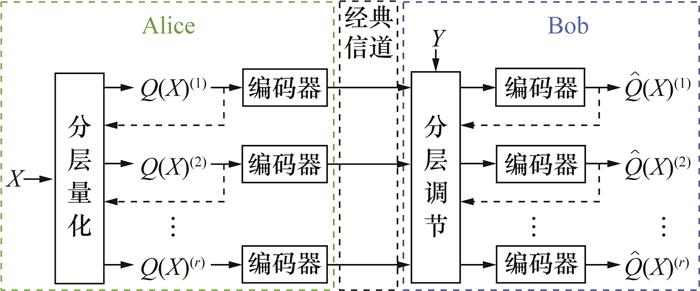
切片协调通常采用多级编码框架[6]来处理连续变量的量化问题。简单来说,量化操作可以视为一个信道,其中量化失真对应于信道噪声,量化后的离散变量视为信道输入,而量化前的连续变量则作为信道输出。根据信道输出和信道条件,可使用纠错码的译码器获得量化结果。
量化完成后,执行方将量化信息进行编码,并发送给另一方。接收方利用这些补充信息以及自己持有的连续变量数据,尝试复现出与发送方相同的量化结果。切片协调可以分为正向协调和反向协调,在正向协调中,由Alice负责执行量化并发送补充信息,而在反向协调中,这一操作由Bob完成。基于多级编码的正向切片协调框架如图 3所示,其中r表示量化级数,Q(X)(l)(1≤l≤r)表示每一级量化得到的二进制数据。
数据协调的2个核心指标为协调成功率和协调效率。协调成功率定义为协调结束后通信双方获得相同密钥的概率。协调效率β定义为每次密钥交换过程中有效密钥长度与总交换信息量之比,表示为
其中:H(Q(X)(l))表示Q(X)(l)的二元熵,Rl表示第l级量化中利用解码器获得的数据占比。
1.4 极化码
极化码是基于信道极化理论提出的一种信道编码方式[8],可由三元组(N, K, $\mathcal{A}$ )表示,其中N表示码长,K表示信息长度,$\mathcal{A}$ ⊆[N]表示用于传输信息比特的子信道集合(信息集合),$\mathcal{F}$ =[N]/$\mathcal{A}$ 表示传输冻结比特的子信道集合(冻结集合)。码长为N的极化码生成矩阵可以表示为
其中$\boldsymbol{G}_{2}^{\otimes _n}$ 为$\boldsymbol{G}_{2}=\left(\begin{array}{ll}1 & 0 \\ 1 & 1\end{array}\right)$ 的n阶Kronecker内积。
极化码的编码过程可以表示为
其中:X1:N为极化码的码字,U1:N为未编码的比特向量。假设一个码字x1:N的每一位xi(i∈[N])分别在N个独立的二进制对称信道(binary symmetric channel, BSC)W上传输后输出y1:N。通过信道极化,可得到N个子信道,第i个子信道WN(i)的转移概率为
其中:WN(y1:N|x1:N)为N个独立信道W的联合转移概率。当N趋于无穷大时,子信道将仅表现为无噪信道或完全的噪声信道,其中无噪信道所占的比例等于W的对称容量。信息集合$\mathcal{A}$ 代表了无噪子信道的索引集合,在编码过程中,$U_{\mathcal{A}}=\left\{U_{i} \mid i \in\right. \mathcal{A}\}$ 被信息比特填充从而实现可靠传输,$U_{\mathcal{F}}=\left\{U_{i} \mid\right. i \in \mathcal{F}\}$ 则被共享的冻结比特(全为0)填充。
极化码编码的关键在于信息集合$ \mathcal{A}$ 的选择,这一过程也被称为极化码的构造。Arikan[8]首先提出利用Bhattacharyya参数构造极化码,Bhattacharyya参数的计算公式为
Bhattacharyya参数可以用来衡量信道出错概率上限,但是对于任意的BSC,精确计算子信道的Bhattacharyya参数较为复杂,实用性欠佳。Tal和Vardy[14]提出的基于信道归并的算法降低了Bhattacharyya参数的计算复杂度,并保持了较高的精度。Tal-Vardy算法不仅在BSC具有出色的性能,而且还能通过一组BSC量化连续信道实现对连续信道的构造。
极化码的经典译码算法是连续消除译码(successive cancellation decoder, SC)算法[8],SC算法的核心可以表达为
极化码不仅在信道编码中发挥着重要作用,同样可以应用于无损信源编码[18]。在无损信源编码过程中,极化码的编码可以表示为
其中:X1:N为非均匀分布的信源向量,U1:N为编码后的码字。由于无损信源编码与信道编码是对偶过程,因此式(7)可以看作式(3)的逆过程。在无损信源编码中,U1:N会极化成2个部分,分别是高熵集合$\mathcal{H}$ 与低熵集合$\mathcal{H}^{c}$ 。当$i \in \mathcal{H}^{c}$ 时,H(Ui│U1:i-1)→0,即当U1:i-1的取值已知时Ui的取值几乎可以被确定。当$i \in \mathcal{H}$ 时,H(Ui│U1:i-1)→1,此时即使已知U1:i-1的取值也无法确定Ui的取值。因此只需要保存$U_{\mathcal{H}}$ 就可实现对信源的无损压缩,极化码的信源编码可以使用SC译码器进行解压缩,表示为
1.5 极化格
一个格是$\mathbb{R}^{N}$ 中的一组离散子集,表示为
其中:B表示格的生成矩阵,此处N表示格的维度[19]。
给定一个N维格Λ,对于N维向量x1:N∈$\mathbb{R}^{N}$ ,对Λ取模为mod(x1:N, Λ)=x1:N-$\underset{\lambda \in \varLambda}{\operatorname{argmin}}$ ‖λ-x1:N‖。Λ的Voronoi区域为V(Λ)={x1:N|mod(x1:N, Λ)=x1:N)},Λ的体积V(Λ)=|det(B)|。格解码的错误概率Pe (Λ, σ2)是一个N维独立同分布且每个维度均值为零和方差为σ2的Gauss噪声向量x1:N落在V(Λ)之外的概率PX1:N {x1:N∉V(Λ)}。对于σ>0且c1:N∈$\mathbb{R}^{N}$ ,以c1:N为中心,方差为σ2的Gauss分布的概率密度函数定义为
其中x1:N∈$\mathbb{R}^{N}$ 。给定一个格Λ,定义以Λ为周期的概率密度函数为
可以认为fσ, Λ(x1:N)是x1:N经过mod-Λ后的概率分布。格Λ的平坦因子[20]定义为
其表示了格与所量化的连续Gauss分布的密集程度之比。平坦因子趋近于0时,表示量化的精度已经足够表示该分布了。
给定子格Λ′⊂Λ,商群Λ/Λ′将Λ划分为多个Λ′的等价群,称Λ/Λ′为格划分,其阶数|Λ/Λ′|等于陪集的数量。如果|Λ/Λ′|=2,则称之为二进制划分。假设Λ/Λ1 /…/Λr(r≥1)为格的链式划分,对于Λl-1/Λl(1≤l≤r,Λ0表示Λ/Λ1/…/Λr中的最上级格Λ),任意一个码Cl在Λl-1/Λl上选择一组代表ai来代表Λl的陪集。如果每个划分都是二进制划分,那么码Cl就是二进制码。格码D构造法[21]利用一组嵌套线性二进制码C1⊆C2⊆…Cr构造N维的格,其中Cl的码长为N,信息位数为Kl(1≤l≤r)。假设有基向量 g1, g2, …, gN∈$\mathbb{F}^{N}_2$ ,使得 g1, …, gKl的线性组合能够表示Cl的所有码字。本研究中主要关注一维格的链式划分$\mathbb{Z}$ /2$\mathbb{Z}$ /…/2r $\mathbb{Z}$ ,其形式为
其中ul(i)∈{0, 1},每一级的码字在mod-Λl-1/Λl信道上传输,且mod-Λl-1/Λl信道是mod-Λl/Λl+1信道的退化信道。
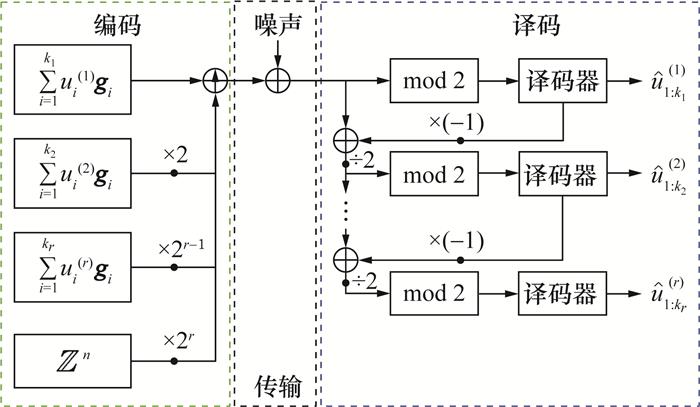
2 基于极化格的量子密钥分发后处理方案
2.1 Wyner-Ziv问题与量子密钥分发后处理
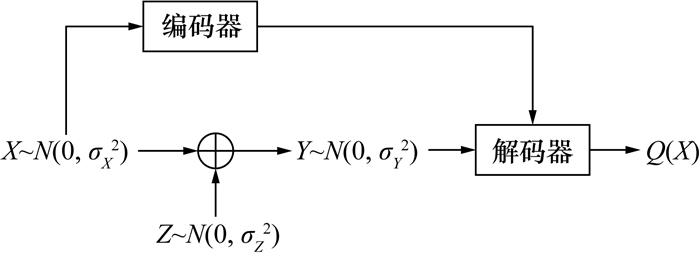
Gauss变量下的Wyner-Ziv问题如图 5所示,涉及2个Gauss变量X~N(0, σX2)和Y~N(0, σY2),中X代表待压缩的信源,Y代表解码端的边信息,二者之间存在一个与X相互独立的噪声Z~N(0, σZ2),满足σZ2+σX2=σY2。Wyner-Ziv问题旨在失真水平D下设计编码方案,使解码端能基于Y和编码信息恢复出X的近似Q(X)。Wyner-Ziv问题的挑战在于编码端无法直接访问全部数据,需设计编码策略以实现解码端的有效数据恢复。这与CV-QKD中信息协调任务相似,后者通过经典信道的补充信息校正数据,实现密钥一致性。因此,CV-QKD的信息协调可视为Wyner-Ziv问题在量子通信领域的应用。
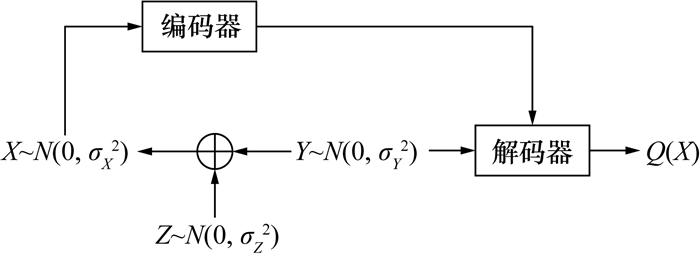
在CV-QKD中,反向数据协调可以通过正向Wyner-Ziv模型来描述,其中Alice负责发送量子信息,而Bob负责编码并发送辅助信息。Gauss变量下的反向Wyner-Ziv问题如图 6所示,可通过对正向Wyner-Ziv问题进行最小均方误差(minimum mean square error,MMSE)放缩得到[24],这一模型对应于正向数据协调,即量子信息的制备和辅助信息的编码都由Alice完成。由于放缩操作的可逆性,正向数据协调和反向数据协调在理论上是等效的,并且都能达到相同的性能极限。为了简化问题,本研究将基于反向Wyner-Ziv问题进行编码设计。值得注意的是,极化格已被证明能够达到Wyner-Ziv问题的理论极限[24],为该方案提供了坚实的理论基础。
反向Wyner-Ziv问题的编码模型如图 7所示,其中ND~(μ, σ2)表示离散Gauss分布。离散采样点ϕ的概率分布表示为
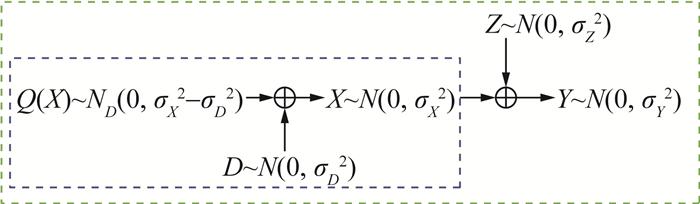
其中:Ψ为所有量化点的集合。
该方案包含编码设计的2个阶段,在量化阶段(蓝色虚线框内),信源X根据所需的失真水平被量化为Q(X)。在纠错阶段(绿色虚线框内),解码端利用边信息Y以及编码得到的辅助信息尝试获得相同的量化结果。
2.2 数据协调
量化阶段与纠错阶段的信道模型如图 8所示。在量化阶段,将Q(X)视为量化信道的输入,X视为量化信道的输出,量化产生的失真视为信道噪声。从这种视角看,量化操作和信道传输是等价的,因此可利用如图 4所示的编译码流程进行译码得到Q(X)。在纠错阶段,将Q(X)视为纠错信道的输入,Y视为纠错信道的输出,量化失真与量子信道的噪声之和视为纠错信道的噪声,同样可以利用图 4的方案进行译码得到Q(X)。由图 8可知,量化信道的噪声功率一定小于或等于纠错信道的噪声功率,当且仅当量子信道不存在噪声时等号成立,即纠错信道为量化信道的退化信道。因此,针对纠错信道的编码码率一定不大于针对量化信道的编码码率,纠错信道的译码器还需要一些补充信息才能恢复Q(X),这2个码率的差值代表了补充信息占所有信息的比例。从极化格的角度看,传输在量化信道的第l级极化码Clq的码率一定不小于传输在纠错信道的第l级极化码Cle的码率。当Cle⊆Clq时,第l级补充信息即为被Clq视为信息比特,而被Cle视为冻结比特的信息。本研究的目标是设计2组相互嵌套的极化码用以构建两套极化格,确保每组极化码内部的码字都是嵌套的,同时两组极化码在同一级别上也保持嵌套关系。

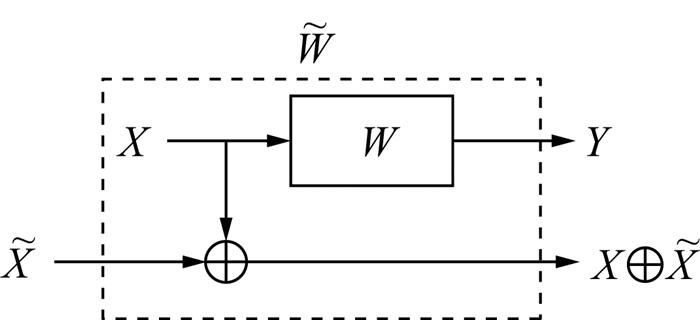
信道W和其对称化信道$\widetilde{W}$ 的信道转移概率具有以下联系:
对称化信道$\widetilde{W}$ 的信道转移概率为不仅包含了信道W的转移概率,还融入了W的输入分布信息。$\widetilde{W}$ 的信道容量为
利用信道对称化技术,可使用基于Bhattacharyya参数的构造算法来构造针对非对称信道的极化码。
通过分别对量化信道和纠错信道进行对称化处理,并基于Bhattacharyya参数针对它们的对称化信道构造极化码,能够获得2组嵌套的极化码,图 10描述了同一级极化码之间的关系。在解码第l级极化码的过程中,Bob和Alice遵循以下规则以确保量化结果一致:
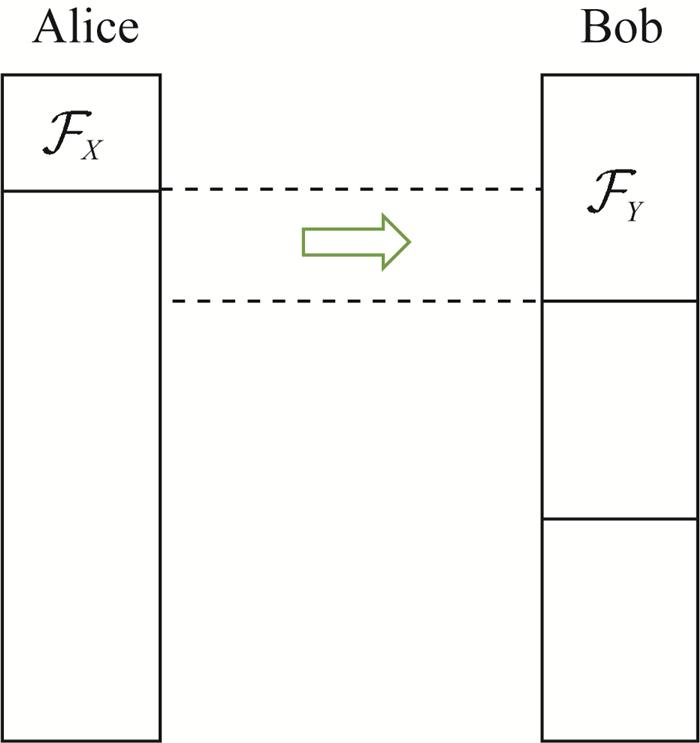
1) 对于满足条件$i \in \mathcal{F}_{Y} \cap \mathcal{F}_{X}$ 的$u_{i}\left(\mathcal{F}_{Y}\right.$ 和$\mathcal{F}_{X}$ 分别表示Bob构造的极化码的冻结集合与Alice构造的极化码的冻结集合),Bob和Alice都将这些值设为0。
2) 对于满足条件$i \in \mathcal{F}_{Y}^{c} \cap \mathcal{F}_{X}^{c}$ 的ui,Bob和Alice都可以利用已知的序列u1:i和解码器来确定其值。
3) 对于满足条件$i \in \mathcal{F}_{Y} / \mathcal{F}_{X}$ 的ui,Alice仍然可以利用已知的序列u1:i和解码器来确定这些值,而Bob则将这些值视为冻结比特。为了保持Bob的解码结果与Alice一致,Bob在解码时不直接将这些值设为0,而是由Alice发送那些满足条件$i \in \mathcal{F}_{Y} / \mathcal{F}_{X}$ 条件的ui。这部分信息就是Alice在数据协调过程中需要发送的补充信息。
通过这种方式,确保了Alice和Bob的量化结果的一致性,实现了数据协调的目的。
2.3 隐私放大
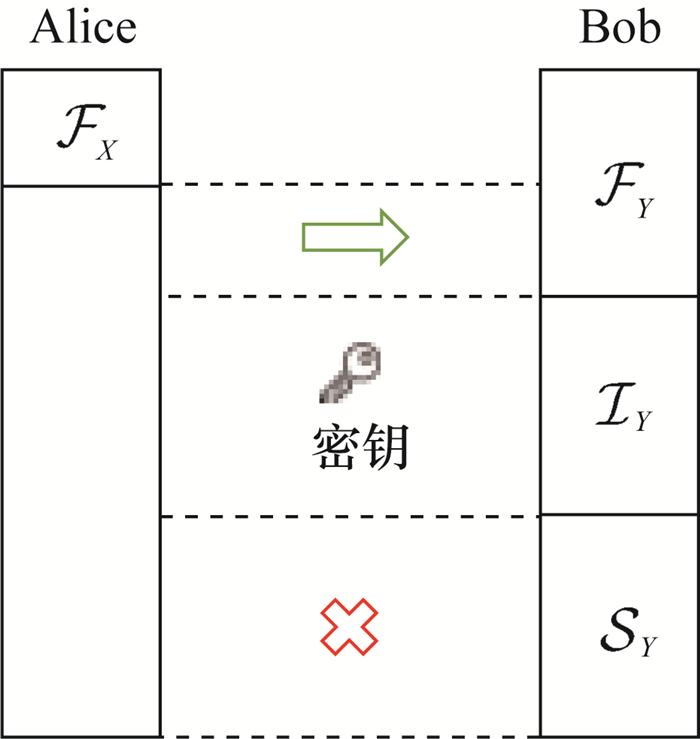
在数据协调的过程中,部分信息是已经明确泄露的,即那些满足条件$i \in \mathcal{F}_{Y}$ 的ui。此外,由于量化所得到的离散变量Q(X)并非均匀分布,这意味着在Q(X)中的每一级量化结果可能不是均匀分布的,每一级量化结果的概率分布如图 11所示。根据信源极化理论,当信源(量化结果)不服从均匀分布时,存在部分信息Ui满足条件H(Ui│U1:i-1)→0,即Ui的取值能够根据U1:i-1的取值推断。当$[i-1] \cap \mathcal{F}_{Y}^{c} \neq \varnothing$ 时,Ui的信息会存在泄露风险,因此在最终的密钥中必须剔除这部分信息以确保安全性。对于寻找满足条件H(Ui│U1:i-1)→0的索引i,基于信道极化与信源极化之间的对偶性,可使用信道编码的构造算法找到这部分低熵集合$\mathcal{S}_{Y}$ 。对于每一级极化码,引入一组BSC,其出错概率与图 11中的概率分布相对应。将这组BSC作为原始信道进行信道极化,极化子信道中的无噪信道就对应了信源极化中的低熵集合。
如图 12所示,此时可以将纠错信道的信息划分为3个部分:信息集合$\mathcal{I}_{Y}$ 、冻结集合$\mathcal{F}_{Y}$ 和低熵集合$\mathcal{S}_{Y}$ 。其中$\mathcal{F}_{Y}$ 表示已经明确泄露的信息,$\mathcal{S}_{Y}$ 表示可能根据已泄露信息推测出的信息,$\mathcal{I}_{Y}$ 则表示安全未泄露的信息。
3 仿真实验
3.1 实验设置
在仿真实验中,将X的方差σX2设定为9,量化噪声D的方差σD2设定为0.25。极化格是基于一维的格划分链$\mathbb{Z} / 2 \mathbb{Z} / \cdots / 2^{r} \;\mathbb{Z}$ 构造的,构造级数r为5。每一级极化码都是基于Tal-Vardy算法进行构造的,针对mod-Λ信道的Tal-Vardy算法的描述详见文[25]。使用16个BSC对连续信道进行量化,在实际应用中可通过量化信道的数量实现构造算法复杂度和编码性能的权衡。使用SC算法作为极化码的译码算法。本研究设置的目标为协调成功率不低于90%,所使用的信噪比SNR的计算公式为
3.2 量化效果
使用极化格对Gauss变量X进行量化,基于格的量化实际上是一种等距离量化,量化精度取决于用于构造极化格的格划分链精度,而量化范围取决于格的构造级数。使用式(12)中的εΛ (σ)判断量化精度是否足够,当εΛ (σ)→0时量化失真可以忽略不计。量化范围可以根据Gauss分布的3σ原则确定,即数值分布在(μ-3σ, μ+3σ)中的概率约为0.997 4,其中μ表示均值,σ表示标准差。
由于每一级极化码的解码器都是基于P(X, Y)进行初始化的,因此式(1)中Rl的上限是第l级信道对称化后的容量即1-H(Q(X)(l), Q(X)(1:l-1), Y),式(1)中分子的上限为
协调效率的上限为
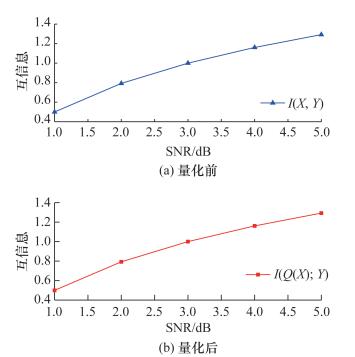
图 13展示了X量化前后与Y之间的互信息大小。如图所示,在信噪比从1到5的区间内,量化前后的互信息量保持了高度一致,这表明量化引入的失真非常小,几乎可以忽略不计。这同时也意味着协调效率的理论上限可以接近100%。
3.3 码率分配
在多级构造的码率分配中,确定每级极化码的码率是一个复杂的过程。本研究中使用了Tal-Vardy算法估算极化子信道的Bhattacharyya参数,由于Bhattacharyya参数刻画了子信道出错概率的上界,因此基于Bhattacharyya参数进行码率分配能够确保协调成功率不会低于我们设定的目标成功率。对于每一级极化码,需要找到最大的kl(1 ≤l ≤r),使得
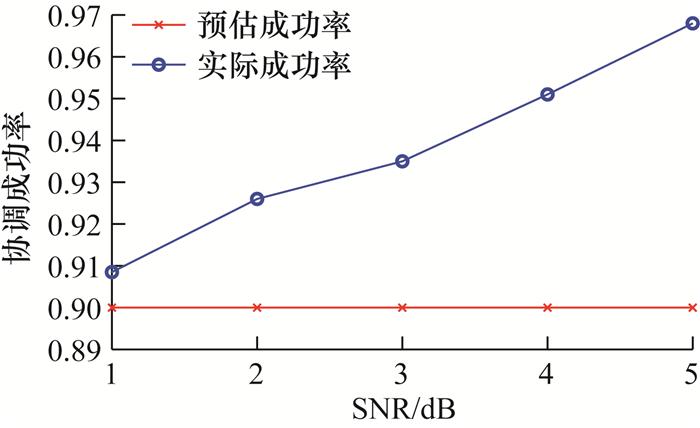
其中:Pe (W(i))为第i个极化子信道的错误率,(1-α)为协调成功率,r为极化格的构造级数。为了满足一般性要求,假设Pe (W(1))≤Pe (W(2))≤…≤ Pe (W(N))。在码长为220,不同信噪比(1, 2, 3, 4, 5)下的实际协调成功率如图 14所示,由图可知,在所考察的信噪比范围内,实际协调成功率均超过了本研究设定的90%的目标成功率。
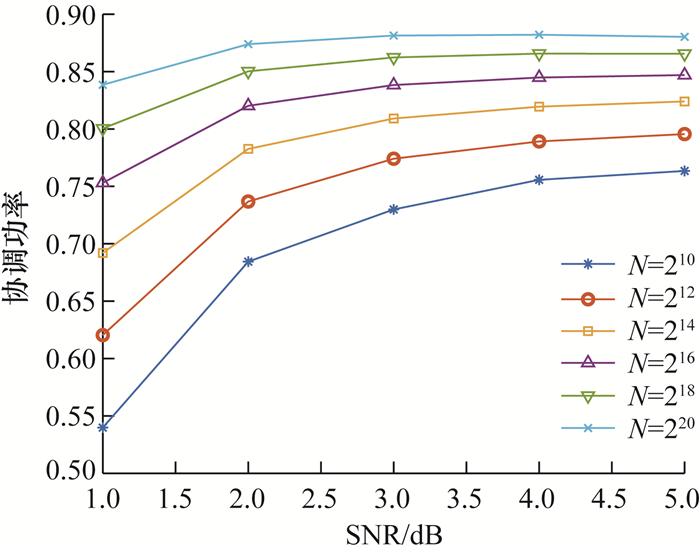
3.4 协调效率
4 结论
基于极化格理论设计了一种连续变量量子密钥分发的后处理方案,包括数据协调和隐私放大。我们将数据协调视为Wyner-Ziv问题的一个实例,通过设计两个嵌套的极化格实现了量化与纠错操作。此外,基于信源极化理论剔除了存在泄露风险的数据,实现了隐私放大。获得主要结论如下:
1) 高效的分布式编码结构设计:通过将信息协调建模为Wyner-Ziv问题,并采用嵌套极化格架构,所提出的方案在不同信道条件下均表现出优异的数据协调效率,尤其在长码长情况下,其性能逼近Slepian-Wolf理论极限,验证了其在信息论意义上的高效性。
2) 兼顾安全性的隐私放大机制:利用信源极化理论,能够有效区分出可靠与不可靠的比特位,将可能被窃听者获取的信息从最终密钥中剔除,从而实现了符合量子密钥分发安全需求的隐私放大过程,显著提升了密钥的安全等级。
3) 可扩展性:本方案的模块化设计便于在未来扩展至更复杂的网络环境和动态信道模型中,为构建大规模量子保密通信网络提供了坚实基础。
实验结果表明,本文提出的方案在协调效率上随着码长的增加而不断提升,显示出接近理论极限的趋势。
极化格的优势主要体现在长码条件下,这对编码构造和译码过程提出了巨大的挑战,因此可进一步针对构造和译码的性能优化和复杂度降低展开研究。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}