


本文提出了一种基于残差网络的矢量量化堆叠自编码器(residual vector quantization stacked autoencoder,RVQS_AE)。首先,基于U-Net[12]网络结构,通过一维卷积将稀疏的长序列表征为稠密的短序列特征,并利用分层的残差结构,使编码器输出的隐向量直接传递给解码器作为输入的一部分,从而避免了现有矢量量化方法中高价值连续信息的丢失的问题。其次,利用矢量量化方法构建多重堆叠码本(code book),学习多维度的离散化类别特征表达,有效克服了编码器的后验坍塌问题。再次,通过引入对抗型网络,以缩小量化结果与编码器输出之间的差异,加速模型收敛速度;最后,数据生成阶段采用变换器(transformer)模型[13]在码本空间训练先验分布,从而实现在离散的隐空间进行先验采样,进而解码生成数据。通过在多个公开的推荐系统数据集上进行实验,验证了该方法在多项指标上的良好性能。
1 相关工作
早期的生成式模型是通过编码器(encoder)和解码器(decoder)构建自编码器[14]。编码器负责将输入数据压缩成低维的潜在空间表示,而解码器基于这个压缩表示重构输入数据。通过最小化输入与输出之间的重构误差,使得自编码器能够有效捕捉数据的内在结构,并在降维和特征提取方面展现了出色的性能。然而,由于其主要关注于数据的重构,而非样本多样性,因此在生成新样本方面的能力相对有限。
近年来,扩散模型通过逐步添加Gauss噪声并逆向预测这些噪声,在连续域的重构和生成中取得了显著成果。然而,由于Gauss噪声添加不适合离散数据,大多数扩散模型只能应用于连续数据。
2 基于残差网络的矢量量化堆叠自编码器
本文基于U-Net网络结构和残差连接构建图 1的模型结构。图中标注了模型各关键部件的输入、输出向量及其维度信息。U-Net网络以其对称的编码器-解码器架构和跳跃连接而著称,能够有效地缓解深度模型中信息丢失的问题。本文模型的对称结构结合残差跳跃连接,能够在解码器中保留原始离散序列的多尺度细节信息,同时通过为梯度传播提供直接路径,有效缓解了梯度消失问题,提高了模型的训练效率和稳定性。
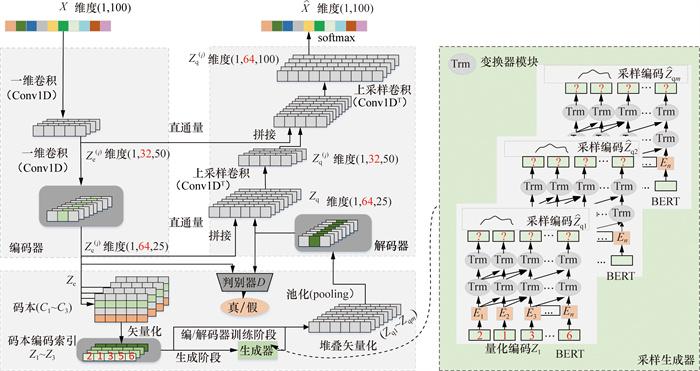
具体而言,图 1中利用残差连接在编码器和解码器之间建立直接的信息传递通道,使低层特征能够直接参与高层特征的重构,从而避免深层网络中细节信息的过早丢失。此外,残差机制通过简化优化目标,减少了模型训练过程中的梯度消失现象,使得深层网络的参数更新更加高效,使模型能够在更复杂的数据集上表现出色。
该结构主要包括4个核心模块:编码器模块、堆叠矢量化模块、解码器模块和采样生成器模块。这种模块化设计不仅提高了模型的表达能力,还增强了生成结果的语义一致性和可控性,为多种复杂任务提供了理论支持和实践优势。
2.1 编码器模块
通过定义编码器,将输入序列$ \boldsymbol{X}=\left(x_1, x_2, \cdots, x_t\right).$ 经过一系列一维卷积(Conv1D)操作后的输出 ze作为编码器输出:
为了详细描述这一过程,用 ze(l)表示第l层卷积的输出:
其中:W(l)和 b(l)分别是编码器第l层的卷积核和偏置项,L代表编码器的总层数。
2.2 堆叠矢量量化模块
传统的VQ-VAE通过单一的矢量量化将连续的潜在空间映射到离散的向量集合,即码本中的向量集合。然而,当处理高维或多模态数据时,单个码本可能无法充分捕捉数据分布的细节。为了符合多兴趣表达,本文构建了m个不同的量化模块VQi (i=1, 2, ···, m),并相应地创建了m个码本。每个VQi负责将编码器输出的连续稠密隐向量 ze,通过最近邻相似度匹配映射到其对应码本Ci中的编码索引zi和最近邻向量zqi:
然后,对 zqi进行池化操作,最终输出矢量化嵌入向量 zq。池化操作可以是平均池化、最大池化或其他形式:
由于 zq由离散的量化映射获得,而VQ-VAE模型优化过程需要引入直通式估计量[5],因此存在的码本损失和承诺损失影响了重构损失。降低该部分对重构损失的影响,成为提升矢量量化方法重构质量的关键。本文采用堆叠的多个码本,平滑单个码本的额外损失。
2.3 解码器模块
本文基于U-Net网络结构的解码器与编码器具有相同的层数L,解码器首层的输入zq(1)由量化输出zq和编码器末端的输出ze(L)通过拼接操作构成。随后通过一维转置卷积(Conv1DT),也称为反卷积,进行上采样,以匹配编码器相应层的维度。该过程可以表示为
其中:$ \oplus$ 表示拼接操作,Wd(1)和 dd(1)分别是解码器第1层的反卷积核和偏置项。随后,对于解码器第l层,其输入zq(l)由前一层的输出zq(l-1)和编码器中第l层输出ze(L-l+1)拼接构成,再经过反卷积上采样操作
其中:Wd(l)和 bd(l)分别是解码器第l层的反卷积核和偏置项。最后,将编码器输出zq(L)经过softmax函数恢复到输入时的离散序列分布:
其中:$ z_{\mathrm{q}}^{(L)}=\left(\begin{array}{llll}z_1 & z_2 & \cdots & z_K\end{array}\right)$ ,K为离散编码空间大小。式(4)—(6)可汇总为一般形式:
其中:zq为式(3)矢量量化后的池化结果,$ \left\{\boldsymbol{z}_{\mathrm{e}}^{(L-l+1)}\right\}_{l=1}^L$ 为式(1)编码器中各层残差直通量。
2.4 采样生成器模块
由于编解码过程没有学习样本概率分布,还无法进行采样。本文通过增加一个先验分布模块学习码本映射的概率分布,并基于码本分布在隐空间采样生成新的码本编码。
1) 码本先验分布概率学习。
首先,利用2.1节中训练过的编码器对离散输入序列进行推理,以获得对应的m个离散码本编码向量zi。随后,部署与之对应的m个BERT模型,用以学习编码序列的分布概率,见图 1右侧部分。具体而言,每个码本编码序列zi的概率分布p(zi),是通过将BERT模型的输出应用softmax函数得到:
2) 序列掩码。
此外,为了确保概率分布的先验采样能够适应多样化的任务场景,码本概率分布的学习过程需要对输入数据进行一定的掩码。本文采纳无掩码、随机掩码、块掩码、滑动掩码和完全掩码5种掩码策略,如图 2所示。在训练过程中对所有样本随机选择一种策略进行掩码。
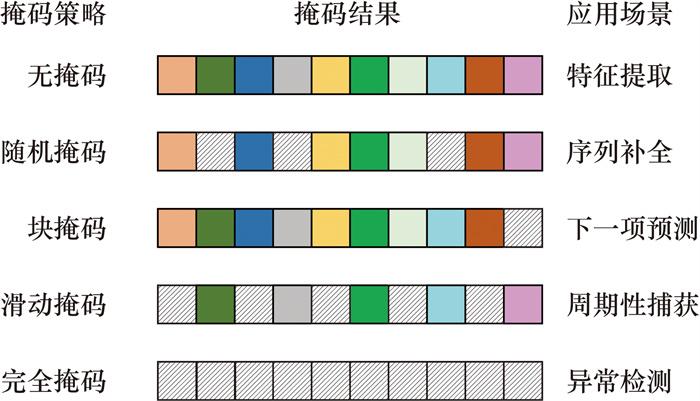
其中,无掩码将离散序列直接进行编解码,通过最小化重构误差学习有效的特征提取能力;随机掩码通过随机选择一定比例的数据进行遮盖,有效模拟了数据缺失情况和不同分辨率的数据处理;块掩码则覆盖了序列尾部的固定长度数据,通过调整覆盖长度来适应不同输出长度的预测需求;滑动掩码通过设定步长,规律性地覆盖序列中的一部分数据,有助于整合时间序列中的非连续信息如不同周期的数据,从而提升模型的表现力;完全掩码则对整个输入序列进行遮盖,或者随机输入任意序列,促使模型重构整个序列,适用于异常检测等场景。通过这些掩码策略的实施,提高了先验概率模块适应多任务场景的泛化能力和实用性。
3) 采样生成。
基于上述掩码机制,由输入序列 X根据不同的掩码策略生成掩码序列:
随后,将 X′送入编码器中以获取对应的连续编码序列:
然后,采用式(4)获取m个独立的码本编码索引和最近邻向量(zi, zqi)。并采用式(8)基于zi计算p(zi)。
对p(zi)进行采样得到码本编码$ \hat{\boldsymbol{z}}_i$ , 可以直接查找Ci中的索引进行量化嵌入,从而得到VQi量化嵌入向量zqi对应的采样嵌入向量$ \hat{\boldsymbol{z}}_{\mathrm{q} i}$ 。最后,结合式(10)编码器中各层输出的残差ze(l)作为直通量,利用式(7)进行解码生成新的样本序列$ \hat{\boldsymbol{X}}$
3 模型训练
基于残差网络的矢量量化堆叠自编码器模型训练的优化目标是使总损失最小化,主要包括3个方面。
3.1 重构损失
模型的一个核心优化目标是最小化重构损失即模型输出与原始输入之间的差异。这通常通过计算输入数据和解码器输出的重构数据之间的差异来实现,对于推荐系统中离散的序列数据,基于式(8)定义交叉熵损失:
其中:T为序列长度,输入序列 X中第i项xi作为真实标签。
3.2 量化损失
量化损失是矢量量化编码特有的损失函数,定义为
其中:sg是停止梯度操作符,β是超参数。该损失函数由2部分组成:一部分是编码器输出与码本嵌入向量之间的差异即嵌入损失;另一部分是嵌入向量与编码器输出之间的差异即承诺损失。利用β来平衡这2部分的权重。通过最小化该损失函数,使得ze更接近于zqi。
3.3 对抗性损失
对抗性损失用于训练量化向量和判别器D,使得量化后的池化聚合结果zq能够“欺骗”判别器,从而缩小zq与ze的差异:
3.4 总损失
模型的总损失是重构损失、量化损失和对抗损失之和:
4 实验结果及分析
4.1 实验数据集
1) 电影数据集ML-1M。
根据数据规模不同,数据集MovieLen主要包含MovieLens 100K、MovieLens 1M和MovieLens 10M等。其中MovieLens 1M即ML-1M包含了6 000名用户对4 000部电影的100万条评分的交互数据,因其规模适中、数据质量高,成为了推荐系统研究领域中一个非常重要的数据集。
2) 电子商务数据集Retail Rocket。
该数据集包含了140万条用户行为记录,涉及4.5个月内他们对商品的浏览、添加到购物车和购买行为。Retail Rocket数据集因其真实性和全面性,在推荐系统研究领域中扮演着重要角色。通过分析这些用户行为数据,研究者可以构建和评估推荐算法,以提高个性化推荐的准确性和效率。
数据集的概要统计信息如表 1所示。在预处理过程中,按照用户数量8∶1∶1的比例划分训练集、验证集和测试集。并在T为20和100时分别对用户的交互历史进行窗口滑动,构成离散的ID序列。
表 1 数据集概要统计信息 |
| 数据集 | 用户数 | 物品数 | 交互数 |
| ML-1M | 6 040 | 3 706 | 1 000 209 |
| Retail Rocket | 1 407 580 | 235 061 | 2 756 101 |
4.2 评价指标
1) 重构能力评估指标。
重构损失是生成式模型衡量重构能力的一项重要指标,能够定量比较各个模型及超参数配置的优劣。为了公平评价重构能力,本文只对各模型在训练阶段的交叉熵损失进行度量,如式(11)所示。此外,采用Top-1准确率[3]定量评价序列数据重构能力。
2) 生成能力评估指标。
首先,本文采用2.4节中的掩码策略,对原始序列进行随机掩码操作。然后,将经过掩码处理的序列输入生成器进行采样,将生成的样本作为评估对象,旨在衡量原始样本数据与生成数据之间推荐物品是否存在显著的曝光度差异。
计算每一个推荐物品曝光均值和方差:
其中:μvA和σv2(A)分别代表推荐物品v在原始样本交互矩阵A中的曝光均值和曝光方差;μvB和σv2(B)分别代表推荐物品v在生成样本交互矩阵B中的曝光均值和曝光方差。$ v=1, 2, \cdots, I$ ,I代表推荐物品的总数,N代表用户总数;Auv代表在A中用户u与物品v的交互情况,Auv为1代表有交互,为0代表无交互;Buv代表在B中用户u与物品v的交互情况,Buv=1代表有交互,为0代表无交互。然后,计算物品v对应的t检验统计量和p检验值:
其中Φ是标准正态分布的累积分布函数。
4.3 基线模型及实验设置
本文将对比生成领域常见的5种模型:
1) 自编码器(AE)[14]。用于学习输入数据的高效表示,通常用于降维或特征学习。
2) 变分自编码器(VAE)[6]。将输入数据编码到概率潜在空间,然后从这个空间中采样以生成新数据。
3) 向量量化变分自编码器(VQ-VAE)[5]。向量量化层将连续的潜在表示聚类到有限的离散向量集合中,通过单独学习先验分布采样生成数据。
4) 向量量化变分自编码器2(VQ-VAE2)[11]。VQ-VAE模型的扩展,引入了分层潜在空间结构,每一层负责学习不同粒度的离散特征。
5) 变分自编码器生成对抗网络(VQGAN)[16]。结合了VQ-VAE的生成能力和GAN的判别能力。矢量量化部分VQ作为生成器,判别器D用于评估矢量化嵌入向量与编码器输出的差异。
对于离散的序列样本数据,将所有对比模型统一引入一维卷积,并保证相同的卷积层数、卷积核大小和卷积步长。鉴于矢量量化系列模型要求较低的学习率,将VQ-VAE、VQ-VAE2和VQGAN模型的学习率设置为0.000 2,其他模型的学习率设置为0.01。
4.4 总体性能比较
4.4.1 重构能力分析
从表 2中不难看出AE具有强大的重构能力,在2个数据集上,T分别为20和100时的重构损失均明显小于其他模型,并且重构准确率达到98%以上。VAE准确率最低,且在图 3和4中可以看到重构损失曲线比其他模型变化幅度小,说明重构的拟合能力不足。VQ-VAE在引入矢量量化后,重构能力有所提升;VQ-VAE2进一步增加量化层次,重构能力继续增强。然而,VQGAN通过强制拉近编码器输出和量化结果的差距,性能并未得到改善。RVQS_AE在2个数据集上重构损失均快速下降,重构损失曲线逼近AE模型,这一现象表明RVQS_AE在离散序列特征表达中借助堆叠量化进行了提升改进,且由于引入了残差机制,其核心优化目标仍然与AE一致,均以重构误差为主导。因此,其重构能力与AE相当,重构损失曲线高度吻合。然而,RVQS_AE采用多层堆叠的向量量化方法对潜在空间表示进行约束,这种离散化引入了量化误差,因此重构性能比AE低。
表 2 模型重构性能总览 |
| 数据集 | T | 重构损失 | 准确率/% | |||||||||||
| AE | VAE | VQ-VAE | VQ-VAE2 | VQGAN | RVQS_AE | AE | VAE | VQ-VAE | VQ-VAE2 | VQGAN | RVQS_AE | |||
| ML-1M | 20 | 3.14×10-7 | 7.511 | 4.902 | 4.159 | 4.918 | 0.151 2 | 0.998 | 0.002 7 | 0.042 | 0.496 | 0.056 | 0.706 9 | |
| 100 | 4.84×10-6 | 7.581 | 4.560 | 4.026 | 4.677 | 0.003 9 | 0.989 | 0.001 9 | 0.042 | 0.041 | 0.008 | 0.505 8 | ||
| Retail | 20 | 1.88×10-5 | 9.219 | 5.754 | 8.368 | 5.336 | 0.000 2 | 0.974 | 0.002 9 | 0.051 | 0.031 | 0.054 | 0.812 6 | |
| Rocket | 100 | 3.55×10-7 | 9.006 | 2.774 | 7.927 | 3.271 | 0.001 9 | 0.965 | 0.002 6 | 0.045 | 0.032 | 0.062 | 0.742 1 | |
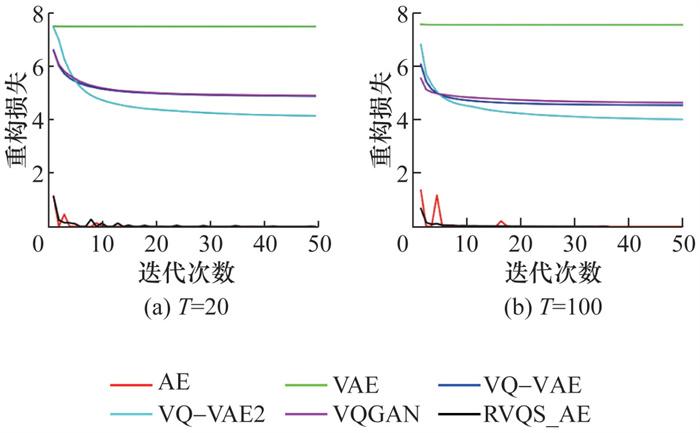
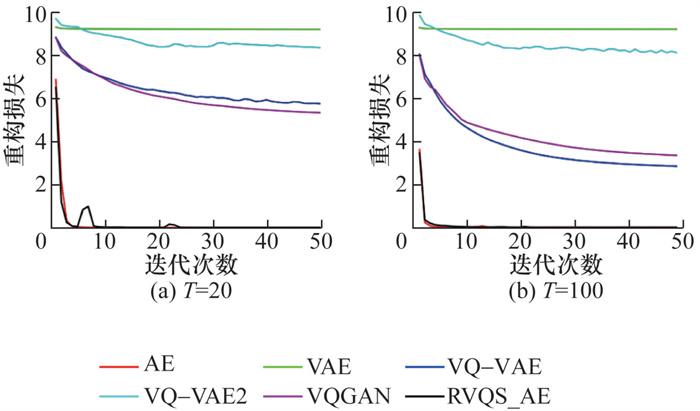
各模型在重构准确率指标上差异巨大,主要源于以下几点:AE凭借连续潜在空间,能精准捕捉输入数据特征,重构细节能力强;VAE因后验坍塌,潜在变量信息不足,重构能力受限;VQ-VAE与VQ-VAE2由于存在量化误差,丢失了样本特征细节信息,重构性能明显降低;VQGAN的对抗性训练虽拉近了量化结果与编码器输入的差距,但因GAN的训练不稳定性,且单一码本的量化误差在不同数据集上可能进一步放大,因此重构性能比AE更低;RVQS_AE借助残差机制保留了编码器输出特征,并采用堆叠量化平滑了单一码本的量化误差,因此重构能力仅次于AE。
4.4.2 生成能力分析
由于物品空间庞大,根据式(18)难以直观比较整体样本生成前后曝光程度的差异。为此,借助生物学基因组分析方法中广泛使用的火山图进行可视化分析[18],通过将用户的会话序列视为基因序列,交互的物品视为基因,分析基因片段的显著性变化。横坐标为物品曝光均值的对数变化倍数如lb (μvB/μvA)。该值为正时,表示生成数据中物品曝光度相对原始数据上调;本文设置上调阈值为2,表示生成数据中物品v的曝光度是原始数据的4倍。该值为负时,表示曝光下调;本文设置下调阈值为-2,表示生成数据中物品v的曝光度是原始数据的1/4倍。纵坐标为物品对应的p检验值的负对数值如-lgpv,表示曝光差异的统计显著性。pv越小,表示生成数据中物品v曝光差异越显著。本文设置显著性阈值为0.05,用于区分物品的pv是否具有统计显著性。
从图 5a和6a不难看出,当T为20时,从物品曝光均值变化看,为了确保足够的重构能力,生成数据中物品呈现曝光度上调;从纵向统计显著性看,AE模型得到的物品p检验值较高,对应的负对数值较低,表明在统计上没有足够的证据认为生成数据与原始数据之间存在显著差异。图 5b和6b中VAE模型生成数据中物品曝光度均下调,并且统计显著性与训练集中物品的曝光度具有一定相关性,即原始数据中曝光量越大的物品,显著性越强,表明模型的生成能力严重不足。VQ-VAE和VQ-VAE2模型中生成数据中物品曝光度下调,说明存在一定量的样本序列重构性欠缺,但同时也有一定的物品曝光度增强。图 5e和6e中VAEGAN通过引入对抗性,生成数据中物品在曝光一致性和显著性方面均有所改善,但是不够明显。RVQS_AE总体表现为生成数据中曝光度偏差和显著性变化与AE模型相似,即生成数据中物品曝光程度上调,但统计显著性低。说明RVQS_AE模型生成数据中物品在曝光程度上与原始数据具有较高的一致性。
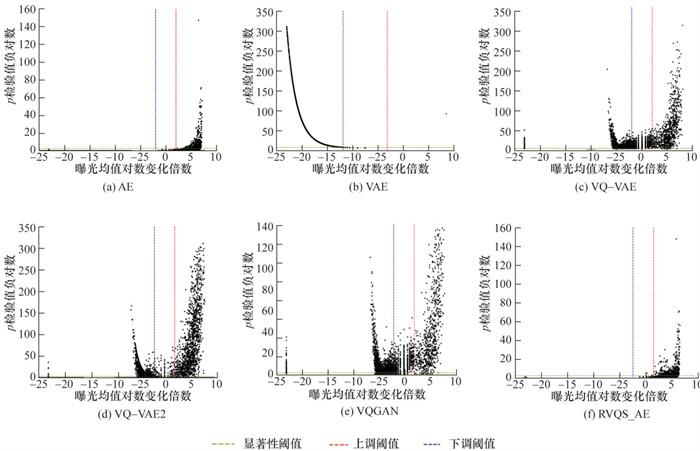
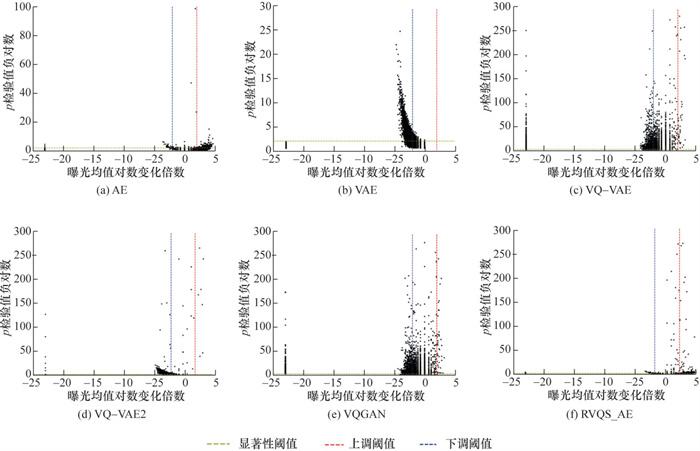
此外,当T为100时各模型在2个数据集上的生成能力表现与T为20时相似,因此不再赘述。
4.5 超参数分析
表 3 ML-1M数据集上的超参数实验 |
| m | T | 重构损失 | 准确率/% |
| 1 | 20 | 0.184 9 | 0.651 1 |
| 100 | 0.045 2 | 0.480 3 | |
| 2 | 20 | 0.184 2 | 0.652 3 |
| 100 | 0.043 1 | 0.485 2 | |
| 3 | 20 | 0.172 8 | 0.690 2 |
| 100 | 0.041 5 | 0.498 5 | |
| 4 | 20 | 0.151 2 | 0.706 9 |
| 100 | 0.003 9 | 0.505 8 | |
| 5 | 20 | 0.162 3 | 0.695 1 |
| 100 | 0.040 9 | 0.501 2 |
表 4 RetailRocket数据集上的超参数实验 |
| m | T | 重构损失 | 准确率/% |
| 1 | 20 | 2.92×10-4 | 0.762 1 |
| 100 | 4.25×10-5 | 0.722 1 | |
| 2 | 20 | 2.64×10-4 | 0.798 4 |
| 100 | 4.12×10-5 | 0.732 1 | |
| 3 | 20 | 2.42×10-4 | 0.812 6 |
| 100 | 3.94×10-5 | 0.742 1 | |
| 4 | 20 | 2.99×10-4 | 0.775 4 |
| 100 | 4.14×10-4 | 0.712 1 | |
| 5 | 20 | 2.96×10-4 | 0.751 9 |
| 100 | 3.01×10-4 | 0.651 4 |
在ML-1M数据集上,当m为4时模型性能达到最优。在Retail Rocket上,m为3时模型性能达到最优。当m继续增加时,性能不再提升,这表明过多的堆叠层数可能导致矢量码本趋向于同质化分布,对性能提升没有进一步贡献。同时,可以观察到T和样本空间的稀疏程度对重构能力有一定的影响,在2个数据集上均表现为较长的序列中模型性能更好,表明模型能够更有效地捕捉长序列中用户兴趣模式。
4.6 消融实验分析
RVQS_AE模型核心组件包括残差连接、堆叠矢量化和对抗性训练。为了系统评估这些关键组件对模型性能的具体贡献,本文分别在2个数据集上设计了一系列消融实验,通过分别剔除这些组件来评估它们对模型性能的影响。具体而言,对RVQS_AE模型去掉残差连接模块,记为NoRest-Stack;去掉堆叠量化,保留单一码本和残差连接(即4.5节中m为1),记为Rest-NoStack;去掉对抗性训练模块,记为NoAdv-Stack。此外,受数据集稀疏程度影响,NoRest-Stack和NoAdv-Stack模型在ML-1M上m为4,在RetailRocket上m为3。
从表 5可以看出,残差连接对模型的重构能力影响最为明显,NoRest-Stack模型性能最差。在保留堆叠矢量化的基础上,去掉池化聚合后的对抗性训练模块后,NoAdv-Stack模型性能略有降低。这表明在该模型中,对抗性训练模块对性能的提升作用相对较小。在保留残差连接和对抗性训练的基础上,去掉堆叠矢量化后,Rest-NoStack模型性能也有一定程度降低。这说明堆叠矢量化在缓解后验坍塌、提高模型编码效率和重构精度方面起到了重要的支撑作用。
表 5 消融实验结果 |
| 数据集 | 模型 | T | 重构损失 | 准确率/% |
| ML-1M | NoRest-Stack | 20 | 5.028 | 0.416 0 |
| 100 | 5.021 | 0.402 1 | ||
| Rest-NoStack | 20 | 0.184 | 0.651 1 | |
| 100 | 0.045 | 0.480 3 | ||
| NoAdv-Stack | 20 | 0.190 | 0.645 1 | |
| 100 | 0.048 | 0.475 5 | ||
| Retail Rocket | NoRest-Stack | 20 | 5.742 | 0.050 1 |
| 100 | 7.712 | 0.045 1 | ||
| Rest-NoStack | 20 | 2.92×10-4 | 0.762 1 | |
| 100 | 4.25×10-5 | 0.722 1 | ||
| NoAdv-Stack | 20 | 3.01×10-4 | 0.755 0 | |
| 100 | 4.50×10-5 | 0.715 1 |
4.7 模型计算效率分析
5 结论
本文提出了一种基于残差网络的矢量量化堆叠自编码器。通过分层残差连接,保留编码器在不同视野尺寸的有价值连续信息,并利用堆叠多个码本平滑解决了单一矢量化码本的后验坍塌问题。
实验结果显示,与现有模型相比,本文模型在提高离散序列数据的重构特征表达能力和生成数据分布的一致性方面取得了显著改善。这表明,该自编码器为推荐系统中的离散序列数据生成提供了一种新的有效解决方案。下一步可以探索该模型在其他类型数据和模型架构中的应用潜力,并优化模型结构以应对更复杂的推荐场景。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}